![]()
GAN for Image Generation
Model Introduction
Generative adversarial network (GAN) is a generative machine learning model, and is recently one of the most promising methods for unsupervised learning in complex distribution.
GAN was first proposed by Ian J. Goodfellow in his paper Generative Adversarial Nets in 2014. It consists of two different models: generator (generative model) and discriminator (discriminative model).
The generator generates "fake" images that look like the images for training.
The discriminator determines whether the images output by the generator are real images or fake images.
GAN contains the generator and discriminator, which contest each other in a zero-sum game, and therefore generate good output.
The core of GAN model is to propose a new framework of estimating the generator through adversarial process. In this framework, two models will be trained at the same time: the generator \(G\) that captures data distribution and the discriminator \(D\) that estimates whether the sample comes from the training data.
In the training process, the generator continuously attempts to deceive the discriminator by generating a better fake image, and the discriminator gradually improves the capability of discriminating images in this process. It reaches the Nash equilibrium when the distribution of the fake image generated by the generator is the same as that of the training image. That is, the confidence of true/false judgment of the discriminator is 50%.
\(x\) represents the image data, and \(D(x)\) is used to represent the probability that the discriminator network determines the image as a real image. During the discrimination process, \(D(x)\) needs to process the image data whose size is \(1\times 28\times 28\) as a binary file. When \(x\) comes from training data, the value of \(D(x)\) should be approximate to \(1\). When \(x\) comes from the generator, the value of \(D(x)\) should be approximate to \(0\). Therefore, \(D(x)\) may also be considered as a conventional binary classifier.
\(z\) represents the implicit vector extracted from the standard normal distribution, and \(G(z)\) represents the generator function that maps the implicit vector \(z\) to the data space. An objective of the function \(G(z)\) is to transform random noise \(z\) obeying Gaussian distribution into data distribution that approximates the true distribution \(p_{data}(x)\) by generating a network. We want to find \(θ\) so that \(p_{G}(x;\theta)\) is as close as possible to \(p_{data}(x)\), where \(\theta\) represents a network parameter.
\(D(G(z))\) indicates the probability that the fake image generated by the generator \(G\) is determined to be a real image. As described in Generative Adversarial Nets, \(D\) and \(G\) are in a game. \(D\) wants to correctly classify real and fake images to the greatest extent, that is, parameter \(\log D(x)\). \(G\) attempts to deceive \(D\) to minimize the probability that the fake image is recognized, that is, parameter \(\log(1−D(G(z)))\). Therefore, a loss function of the GAN is:
Theoretically, it reaches the Nash equilibrium when \(p_{G}(x;\theta) = p_{data}(x)\), where the discriminator randomly guesses whether the input is a real or fake image. The following describes the game process of the generator and discriminator:
At the beginning of the training, the quality of the generator and discriminator is poor. The generator randomly generates a data distribution.
The discriminator optimizes the network by calculating the gradient and loss function. The data close to the real data distribution is determined as 1, and the data close to the data distribution generated by the generator is determined as 0.
The generator generates data that is closer to the real data distribution through optimization.
The data generated by the generator reaches the same distribution as the real data. In this case, the output of the discriminator is 1/2.
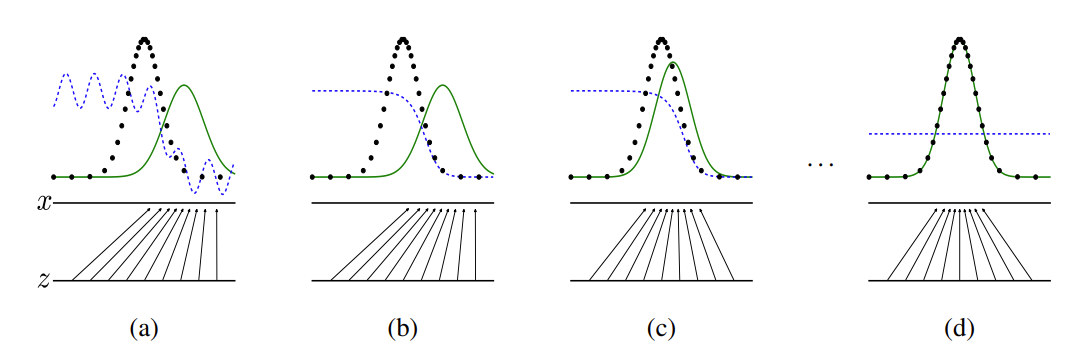
In the preceding figure, the blue dotted line indicates the discriminator, the black dotted line indicates the real data distribution, the green solid line indicates the false data distribution generated by the generator, \(z\) indicates the implicit vector, and \(x\) indicates the generated fake image \(G(z)\). The image comes from Generative Adversarial Nets. For details about the training method, see the original paper.
Dataset
Overview
The MNIST dataset of handwritten digits is a subset of the NIST dataset. There are 70,000 handwritten digit images, including 60,000 training samples and 10,000 test samples. The digit images are binary files, the image size is 28 x 28, and a single channel is used. Size normalization and centralization have been performed on images in advance.
This case uses the MNIST dataset to train a generative adversarial network that simulates the generation of handwritten digit images.
Downloading a Dataset
Use the download API to download the dataset and decompress it to the current directory. Before downloading data, use pip install download to install the download package.
The directory structure of the downloaded dataset is as follows:
./MNIST_Data/
├─ train
│ ├─ train-images-idx3-ubyte
│ └─ train-labels-idx1-ubyte
└─ test
├─ t10k-images-idx3-ubyte
└─ t10k-labels-idx1-ubyte
The code for downloading data is as follows:
# Download data.
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/MNIST_Data.zip"
download(url, ".", kind="zip", replace=True)
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/MNIST_Data.zip (10.3 MB)
file_sizes: 100%|███████████████████████████| 10.8M/10.8M [00:23<00:00, 455kB/s]
Extracting zip file...
Successfully downloaded / unzipped to .
Data Loading
Use MindSpore's own MnistDataset API to read and parse the source files of the MNIST dataset to build the dataset. Then, pre-process the data.
import numpy as np
import mindspore.dataset as ds
batch_size = 128
latent_size = 100 # Length of the implicit vector.
train_dataset = ds.MnistDataset(dataset_dir='./MNIST_Data/train')
test_dataset = ds.MnistDataset(dataset_dir='./MNIST_Data/test')
def data_load(dataset):
dataset1 = ds.GeneratorDataset(dataset, ["image", "label"], shuffle=True, python_multiprocessing=False)
# Data augmentation
mnist_ds = dataset1.map(
operations=lambda x: (x.astype("float32"), np.random.normal(size=latent_size).astype("float32")),
output_columns=["image", "latent_code"])
mnist_ds = mnist_ds.project(["image", "latent_code"])
# Batch operations
mnist_ds = mnist_ds.batch(batch_size, True)
return mnist_ds
mnist_ds = data_load(train_dataset)
iter_size = mnist_ds.get_dataset_size()
print('Iter size: %d' % iter_size)
Iter size: 468
Dataset Visualization
Use the create_dict_iterator function to convert data into a dictionary iterator, and then use the matplotlib module to visualize some training data.
import matplotlib.pyplot as plt
data_iter = next(mnist_ds.create_dict_iterator(output_numpy=True))
figure = plt.figure(figsize=(3, 3))
cols, rows = 5, 5
for idx in range(1, cols * rows + 1):
image = data_iter['image'][idx]
figure.add_subplot(rows, cols, idx)
plt.axis("off")
plt.imshow(image.squeeze(), cmap="gray")
plt.show()
Implicit Vector Construction
To track the learning progress of the generator, after each training epoch in the training process ends, a group of fixed implicit vectors test_noise that comply with Gaussian distribution are input to the generator, and the image effect generated by the fixed hidden code is used to evaluate the generator.
import random
import numpy as np
from mindspore import Tensor, dtype
# Create a batch of implicit vectors using random seeds.
np.random.seed(2323)
test_noise = Tensor(np.random.normal(size=(25, 100)), dtype.float32)
random.shuffle(test_noise)
Model Building
The structure of the GAN model built in this case is roughly the same as that proposed in the original paper. However, the used dataset MNIST contains only single-channel small-sized images, and there are few identifiable parameters. To facilitate training, we can achieve satisfactory results by using a fully-connected network architecture and a ReLU activation function in the discriminator and generator, and omit the Dropout strategy for reducing parameters and the learnable activation function Maxout in the original paper.
Generator
The function of Generator is to map the implicit vector to the data space. Because the data is an image, this process also creates a grayscale image (or RGB color image) with the same size as the real image. In this case, this function is implemented through five Dense layers. Each layer is paired with the BatchNorm1d layer and the ReLU activation layer. The output data passes through the Tanh function and is returned within the range of [-1,1]. After instantiating the generator, you need to change the parameter name. Otherwise, an error is reported in static graph mode.
from mindspore import nn
import mindspore.ops as ops
img_size = 28 # Training image length (width)
class Generator(nn.Cell):
def __init__(self, latent_size, auto_prefix=True):
super(Generator, self).__init__(auto_prefix=auto_prefix)
self.model = nn.SequentialCell()
# [N, 100] -> [N, 128]
# Input a 100-dimensional Gaussian distribution between 0 and 1, and then map it to 256 dimensions through the first-layer linear transformation.
self.model.append(nn.Dense(latent_size, 128))
self.model.append(nn.ReLU())
# [N, 128] -> [N, 256]
self.model.append(nn.Dense(128, 256))
self.model.append(nn.BatchNorm1d(256))
self.model.append(nn.ReLU())
# [N, 256] -> [N, 512]
self.model.append(nn.Dense(256, 512))
self.model.append(nn.BatchNorm1d(512))
self.model.append(nn.ReLU())
# [N, 512] -> [N, 1024]
self.model.append(nn.Dense(512, 1024))
self.model.append(nn.BatchNorm1d(1024))
self.model.append(nn.ReLU())
# [N, 1024] -> [N, 784]
# It is converted into 784 dimensions through linear transformation.
self.model.append(nn.Dense(1024, img_size * img_size))
# After the Tanh activation function is used, the generated fake image data distribution is expected to range from -1 to 1.
self.model.append(nn.Tanh())
def construct(self, x):
img = self.model(x)
return ops.reshape(img, (-1, 1, 28, 28))
net_g = Generator(latent_size)
net_g.update_parameters_name('generator')
Discriminator
As described above, Discriminator is a binary network model, and outputs the probability that the image is determined as a real image. It is processed through a series of Dense and LeakyReLU layers. Finally, the Sigmoid activation function is used to return the data within the range of [0, 1] to obtain the final probability. After instantiating the discriminator, you need to change the parameter name. Otherwise, an error is reported in static graph mode.
# Discriminator
class Discriminator(nn.Cell):
def __init__(self, auto_prefix=True):
super().__init__(auto_prefix=auto_prefix)
self.model = nn.SequentialCell()
# [N, 784] -> [N, 512]
self.model.append(nn.Dense(img_size * img_size, 512)) # The number of input features is 784, and the number of output features is 512.
self.model.append(nn.LeakyReLU()) # Nonlinear mapping activation function with a default slope of 0.2.
# [N, 512] -> [N, 256]
self.model.append(nn.Dense(512, 256)) # Linear mapping.
self.model.append(nn.LeakyReLU())
# [N, 256] -> [N, 1]
self.model.append(nn.Dense(256, 1))
self.model.append(nn.Sigmoid()) # Binary activation function, which maps real numbers to [0,1]
def construct(self, x):
x_flat = ops.reshape(x, (-1, img_size * img_size))
return self.model(x_flat)
net_d = Discriminator()
net_d.update_parameters_name('discriminator')
Loss Function and Optimizer
After Generator and Discriminator are defined, the binary cross-entropy loss function BCELoss in MindSpore is used as the loss function. Both the generator and discriminator use the Adam optimizer. However, you need to build two optimizers with different names to update the parameters of the two models. For details, see the following code. Note that the parameter names of the optimizer also need to be changed.
lr = 0.0002 # Learning rate
# Loss function
adversarial_loss = nn.BCELoss(reduction='mean')
# Optimizers
optimizer_d = nn.Adam(net_d.trainable_params(), learning_rate=lr, beta1=0.5, beta2=0.999)
optimizer_g = nn.Adam(net_g.trainable_params(), learning_rate=lr, beta1=0.5, beta2=0.999)
optimizer_g.update_parameters_name('optim_g')
optimizer_d.update_parameters_name('optim_d')
Model Training
Training is divided into two parts.
The first part is to train the discriminator. The discriminator is trained to improve the probability of discriminating real images to the greatest extent. According to the method of the original paper, the discriminator is updated by increasing its stochastic gradient to maximize the value of \(log D(x) + log(1 - D(G(z)))\).
The second part is to train the generator. As described in the paper, \(log(1 - D(G(z)))\) is minimized to train the generator to produce better false images.
In the two parts, the losses in the training process are obtained separately, and the test is performed at the end of each epoch. The implicit vectors are pushed to the generator in batches to intuitively track the training effect of the Generator.
import os
import time
import matplotlib.pyplot as plt
import mindspore as ms
from mindspore import Tensor, save_checkpoint
total_epoch = 200 # Number of training epochs
batch_size = 128 # Batch size of the training set used for training
# Parameters for loading a pre-trained model
pred_trained = False
pred_trained_g = './result/checkpoints/Generator99.ckpt'
pred_trained_d = './result/checkpoints/Discriminator99.ckpt'
checkpoints_path = "./result/checkpoints" # Path for saving results
image_path = "./result/images" # Path for saving test results
# Loss calculation process of the generator
def generator_forward(test_noises):
fake_data = net_g(test_noises)
fake_out = net_d(fake_data)
loss_g = adversarial_loss(fake_out, ops.ones_like(fake_out))
return loss_g
# Loss calculation process of the discriminator
def discriminator_forward(real_data, test_noises):
fake_data = net_g(test_noises)
fake_out = net_d(fake_data)
real_out = net_d(real_data)
real_loss = adversarial_loss(real_out, ops.ones_like(real_out))
fake_loss = adversarial_loss(fake_out, ops.zeros_like(fake_out))
loss_d = real_loss + fake_loss
return loss_d
# Gradient method
grad_g = ms.value_and_grad(generator_forward, None, net_g.trainable_params())
grad_d = ms.value_and_grad(discriminator_forward, None, net_d.trainable_params())
def train_step(real_data, latent_code):
# Calculate discriminator loss and gradient.
loss_d, grads_d = grad_d(real_data, latent_code)
optimizer_d(grads_d)
loss_g, grads_g = grad_g(latent_code)
optimizer_g(grads_g)
return loss_d, loss_g
# Save the generated test image.
def save_imgs(gen_imgs1, idx):
for i3 in range(gen_imgs1.shape[0]):
plt.subplot(5, 5, i3 + 1)
plt.imshow(gen_imgs1[i3, 0, :, :] / 2 + 0.5, cmap="gray")
plt.axis("off")
plt.savefig(image_path + "/test_{}.png".format(idx))
# Set the path for saving parameters.
os.makedirs(checkpoints_path, exist_ok=True)
# Set the path for saving the images generated during the intermediate process.
os.makedirs(image_path, exist_ok=True)
net_g.set_train()
net_d.set_train()
# Store the generator and discriminator loss.
losses_g, losses_d = [], []
for epoch in range(total_epoch):
start = time.time()
for (iter, data) in enumerate(mnist_ds):
start1 = time.time()
image, latent_code = data
image = (image - 127.5) / 127.5 # [0, 255] -> [-1, 1]
image = image.reshape(image.shape[0], 1, image.shape[1], image.shape[2])
d_loss, g_loss = train_step(image, latent_code)
end1 = time.time()
if iter % 10 == 0:
print(f"Epoch:[{int(epoch):>3d}/{int(total_epoch):>3d}], "
f"step:[{int(iter):>4d}/{int(iter_size):>4d}], "
f"loss_d:{d_loss.asnumpy():>4f} , "
f"loss_g:{g_loss.asnumpy():>4f} , "
f"time:{(end1 - start1):>3f}s, "
f"lr:{lr:>6f}")
end = time.time()
print("time of epoch {} is {:.2f}s".format(epoch + 1, end - start))
losses_d.append(d_loss.asnumpy())
losses_g.append(g_loss.asnumpy())
# After each epoch ends, use the generator to generate a group of images.
gen_imgs = net_g(test_noise)
save_imgs(gen_imgs.asnumpy(), epoch)
# Save the model weight file based on the epoch.
if epoch % 1 == 0:
save_checkpoint(net_g, checkpoints_path + "/Generator%d.ckpt" % (epoch))
save_checkpoint(net_d, checkpoints_path + "/Discriminator%d.ckpt" % (epoch))
Epoch:[ 0/200], step:[ 0/ 468], loss_d:1.383930 , loss_g:0.693423 , time:0.864688s, lr:0.000200
Epoch:[ 0/200], step:[ 10/ 468], loss_d:1.356453 , loss_g:0.548430 , time:0.122673s, lr:0.000200
Epoch:[ 0/200], step:[ 20/ 468], loss_d:1.386923 , loss_g:0.628228 , time:0.120677s, lr:0.000200
Epoch:[ 0/200], step:[ 30/ 468], loss_d:1.385639 , loss_g:0.649491 , time:0.124667s, lr:0.000200
Epoch:[ 0/200], step:[ 40/ 468], loss_d:1.365866 , loss_g:0.683650 , time:0.122672s, lr:0.000200
...
Epoch:[ 99/200], step:[ 440/ 468], loss_d:1.170306 , loss_g:0.954169 , time:0.113697s, lr:0.000200
Epoch:[ 99/200], step:[ 450/ 468], loss_d:1.187954 , loss_g:0.970897 , time:0.113697s, lr:0.000200
Epoch:[ 99/200], step:[ 460/ 468], loss_d:1.277891 , loss_g:0.930688 , time:0.116688s, lr:0.000200
time of epoch 100 is 61.76s
Epoch:[100/200], step:[ 0/ 468], loss_d:1.197745 , loss_g:0.951075 , time:0.134640s, lr:0.000200
Epoch:[100/200], step:[ 10/ 468], loss_d:1.241353 , loss_g:0.939583 , time:0.131648s, lr:0.000200
Epoch:[100/200], step:[ 20/ 468], loss_d:1.222481 , loss_g:0.900680 , time:0.129653s, lr:0.000200
...
Epoch:[199/200], step:[ 420/ 468], loss_d:1.215858 , loss_g:1.071604 , time:0.151593s, lr:0.000200
Epoch:[199/200], step:[ 430/ 468], loss_d:1.238803 , loss_g:0.920928 , time:0.135638s, lr:0.000200
Epoch:[199/200], step:[ 440/ 468], loss_d:1.212080 , loss_g:0.954983 , time:0.134640s, lr:0.000200
Epoch:[199/200], step:[ 450/ 468], loss_d:1.236587 , loss_g:0.897825 , time:0.133643s, lr:0.000200
Epoch:[199/200], step:[ 460/ 468], loss_d:1.214701 , loss_g:0.939405 , time:0.135638s, lr:0.000200
time of epoch 200 is 71.98s
Effect Display
Run the following code to describe the relationship between the D and G losses and the training iteration:
plt.figure(figsize=(6, 4))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(losses_g, label="G", color='blue')
plt.plot(losses_d, label="D", color='orange')
plt.xlim(-20, 220)
plt.ylim(0, 3.5)
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
Image generated by implicit vector during visual training.
import cv2
import matplotlib.animation as animation
# Convert the test image generated during training to a dynamic image.
image_list = []
for i in range(total_epoch):
image_list.append(cv2.imread(image_path + "/test_{}.png".format(i), cv2.IMREAD_GRAYSCALE))
show_list = []
fig = plt.figure(dpi=70)
for epoch in range(0, len(image_list), 5):
plt.axis("off")
show_list.append([plt.imshow(image_list[epoch], cmap='gray')])
ani = animation.ArtistAnimation(fig, show_list, interval=1000, repeat_delay=1000, blit=True)
ani.save('train_test.gif', writer='pillow', fps=1)

As shown in the preceding figure, the image quality becomes better as the number of training epochs increases. If the value of epoch is greater than 100, the generated handwritten digit image is similar to that in the dataset. Now, let's load the generator network model parameter file to generate an image.
Model Inference
Now, let's load the generator network model parameter file to generate an image. The code is as follows:
import mindspore as ms
test_ckpt = './result/checkpoints/Generator199.ckpt'
parameter = ms.load_checkpoint(test_ckpt)
ms.load_param_into_net(net_g, parameter)
# Model generation result
test_data = Tensor(np.random.normal(0, 1, (25, 100)).astype(np.float32))
images = net_g(test_data).transpose(0, 2, 3, 1).asnumpy()
# Result display
fig = plt.figure(figsize=(3, 3), dpi=120)
for i in range(25):
fig.add_subplot(5, 5, i + 1)
plt.axis("off")
plt.imshow(images[i].squeeze(), cmap="gray")
plt.show()