Data Operation/Data Transformation
![]()
Data Operation
mindspore.dataset provides a series of dataset operations. Users can use these dataset operations, such as .shuffle / .filter / .skip / .take / .batch / … to further shuffle, filter, skip, and batch combine datasets.
Common data transformation operations include:
.filter(...): Filter multiple data sets based on specified conditions and retain samples that meet the expected conditions..project(...): Select multiple data columns or delete unnecessary data columns..rename(...): Rename specified data columns to facilitate data characteristic labelling..shuffle(...): Divide a data buffer and shuffle the data within the buffer..skip(...): Skip the first n samples in the dataset..take(...): Retrieve only the first n samples from the dataset..map(...): Data transformation, applying custom methods to enhance each sample..batch(...): Combinebatch_sizedata points.
The following example code demonstrates filter, skip, and batch data operations.
from mindspore.dataset import GeneratorDataset
# Random-accessible object as input source
class MyDataset:
def __init__(self):
self._data = [1, 2, 3, 4, 5, 6]
def __getitem__(self, index):
return self._data[index]
def __len__(self):
return len(self._data)
loader = MyDataset()
# find samples whose value < 4
dataset = GeneratorDataset(source=loader, column_names=["data"], shuffle=False)
filtered_dataset = dataset.filter(lambda x: x < 4, input_columns=["data"])
print("filtered_dataset", list(filtered_dataset))
# skip first 3 samples
dataset = GeneratorDataset(source=loader, column_names=["data"], shuffle=False)
skipped_dataset = dataset.skip(3)
print("skipped_dataset", list(skipped_dataset))
# batch the dataset by batch_size=2
dataset = GeneratorDataset(source=loader, column_names=["data"], shuffle=False)
batched_dataset = dataset.batch(2, num_parallel_workers=1)
print("batched_dataset", list(batched_dataset))
filtered_dataset [[Tensor(shape=[], dtype=Int64, value= 1)], [Tensor(shape=[], dtype=Int64, value= 2)], [Tensor(shape=[], dtype=Int64, value= 3)]]
skipped_dataset [[Tensor(shape=[], dtype=Int64, value= 4)], [Tensor(shape=[], dtype=Int64, value= 5)], [Tensor(shape=[], dtype=Int64, value= 6)]]
batched_dataset [[Tensor(shape=[2], dtype=Int64, value= [1, 2])], [Tensor(shape=[2], dtype=Int64, value= [3, 4])], [Tensor(shape=[2], dtype=Int64, value= [5, 6])]]
In addition, there are operations such as dataset combination, splitting, and saving.
Dataset Combination
Dataset combination can combine multiple datasets in a serial/parallel manner to form a brand-new dataset object.
import mindspore.dataset as ds
ds.config.set_seed(1234)
# concat same column of two datasets
data = [1, 2, 3]
dataset1 = ds.NumpySlicesDataset(data=data, column_names=["column_1"])
data = [4, 5, 6]
dataset2 = ds.NumpySlicesDataset(data=data, column_names=["column_1"])
dataset = dataset1.concat(dataset2)
for item in dataset.create_dict_iterator():
print("concated dataset", item)
# zip different columns of two datasets
data = [1, 2, 3]
dataset1 = ds.NumpySlicesDataset(data=data, column_names=["column_1"])
data = [4, 5, 6]
dataset2 = ds.NumpySlicesDataset(data=data, column_names=["column_2"])
dataset = dataset1.zip(dataset2)
for item in dataset.create_dict_iterator():
print("zipped dataset", item)
concated dataset {'column_1': Tensor(shape=[], dtype=Int64, value= 2)}
concated dataset {'column_1': Tensor(shape=[], dtype=Int64, value= 3)}
concated dataset {'column_1': Tensor(shape=[], dtype=Int64, value= 1)}
concated dataset {'column_1': Tensor(shape=[], dtype=Int64, value= 5)}
concated dataset {'column_1': Tensor(shape=[], dtype=Int64, value= 6)}
concated dataset {'column_1': Tensor(shape=[], dtype=Int64, value= 4)}
zipped dataset {'column_1': Tensor(shape=[], dtype=Int64, value= 2), 'column_2': Tensor(shape=[], dtype=Int64, value= 5)}
zipped dataset {'column_1': Tensor(shape=[], dtype=Int64, value= 3), 'column_2': Tensor(shape=[], dtype=Int64, value= 6)}
zipped dataset {'column_1': Tensor(shape=[], dtype=Int64, value= 1), 'column_2': Tensor(shape=[], dtype=Int64, value= 4)}
Dataset Splitting
Split the dataset into a training dataset and a validation dataset, which are used for the training process and validation process, respectively.
import mindspore.dataset as ds
data = [1, 2, 3, 4, 5, 6]
dataset = ds.NumpySlicesDataset(data=data, column_names=["column_1"], shuffle=False)
train_dataset, eval_dataset = dataset.split([4, 2])
print(">>>> train dataset >>>>")
for item in train_dataset.create_dict_iterator():
print(item)
print(">>>> eval dataset >>>>")
for item in eval_dataset.create_dict_iterator():
print(item)
>>>> train dataset >>>>
{'column_1': Tensor(shape=[], dtype=Int64, value= 6)}
{'column_1': Tensor(shape=[], dtype=Int64, value= 4)}
{'column_1': Tensor(shape=[], dtype=Int64, value= 1)}
{'column_1': Tensor(shape=[], dtype=Int64, value= 5)}
>>>> eval dataset >>>>
{'column_1': Tensor(shape=[], dtype=Int64, value= 3)}
{'column_1': Tensor(shape=[], dtype=Int64, value= 2)}
Saving Datasets
Resave the dataset in MindRecord data format.
import os
import mindspore.dataset as ds
ds.config.set_seed(1234)
data = [1, 2, 3, 4, 5, 6]
dataset = ds.NumpySlicesDataset(data=data, column_names=["column_1"])
if os.path.exists("./train_dataset.mindrecord"):
os.remove("./train_dataset.mindrecord")
if os.path.exists("./train_dataset.mindrecord.db"):
os.remove("./train_dataset.mindrecord.db")
dataset.save("./train_dataset.mindrecord")
Data Transformation
In most cases, raw data cannot be directly loaded into a neural network for training. Instead, it must first undergo data preprocessing. MindSpore provides various types of data transformations (Transforms) that can be used in conjunction with data processing pipelines to perform data preprocessing.
These transformations can generally be used in two ways: 'data transformation based on data operation maps' and 'lightweight data transformation'. These are described below.
Data Transformation Based on map Data Operations
mindspore.datasetprovides built-in data transformation operations for different data types such as images, text, and audio. All transformations can be passed to themapoperation, which automatically transforms each sample using themapmethod.In addition to built-in data transformations, the
mapoperation can also execute user-defined transformation operations.
# Download data from open datasets
from download import download
from mindspore.dataset import MnistDataset
import mindspore.dataset.vision as vision
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
# create MNIST loader
train_dataset = MnistDataset("MNIST_Data/train", shuffle=False)
# resize samples to (64, 64) using built-in transformation
train_dataset = train_dataset.map(operations=[vision.Resize((64, 64))],
input_columns=['image'])
for data in train_dataset:
print(data[0].shape, data[0].dtype)
break
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/MNIST_Data.zip (10.3 MB)
file_sizes: 100%|██████████████████████████| 10.8M/10.8M [00:01<00:00, 6.99MB/s]
Extracting zip file...
Successfully downloaded / unzipped to ./
(64, 64, 1) UInt8
# create MNIST loader
train_dataset = MnistDataset("MNIST_Data/train", shuffle=False)
def transform(img):
img = img / 255.0
return img
# apply normalize using customized transformation
train_dataset = train_dataset.map(operations=[transform],
input_columns=['image'])
for data in train_dataset:
print(data[0].shape, data[0].dtype)
break
(28, 28, 1) Float64
Lightweight Data Transformation
MindSpore provides a lightweight data processing way, called Eager mode.
In the Eager mode, transforms are executed in the form of a functional call. The code will be simpler and the results are obtained immediately. It is recommended for lightweight scenarios such as small data augmentation experiments and model inference.

MindSpore currently supports executing various Transforms in the Eager mode, as shown below. For more details, please refer to the API documentation.
vision module, data transform implemented based on OpenCV/Pillow.
text module, data transform implemented based on Jieba, ICU4C, etc.
audio module, data transform implemented based on C++, etc.
transforms module, general-purpose data transform implemented based on C++/Python/NumPy.
The following sample code downloads the image data to the specified location. With the Eager mode, you only need to treat Transform itself as an executable function.
Data Preparation
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/banana.jpg"
download(url, './banana.jpg', replace=True)
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/banana.jpg (17 kB)
file_sizes: 100%|███████████████████████████| 17.1k/17.1k [00:00<00:00, 677kB/s]
Successfully downloaded file to ./banana.jpg
'./banana.jpg'
vision
This example will use Transform in the mindspore.dataset.vision module to transform a given image.
The Eager mode of the Vision Transform supports numpy.array or PIL.Image type data as input parameters. For more examples, please refer to: Illustration Of Vision Transforms
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import mindspore.dataset.vision as vision
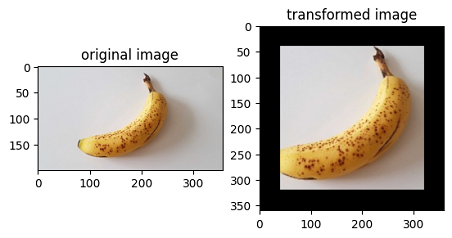
img_ori = Image.open("banana.jpg").convert("RGB")
print("Image.type: {}, Image.shape: {}".format(type(img_ori), img_ori.size))
# Apply Resize to input immediately
op1 = vision.Resize(size=(320))
img = op1(img_ori)
print("Image.type: {}, Image.shape: {}".format(type(img), img.size))
# Apply CenterCrop to input immediately
op2 = vision.CenterCrop((280, 280))
img = op2(img)
print("Image.type: {}, Image.shape: {}".format(type(img), img.size))
# Apply Pad to input immediately
op3 = vision.Pad(40)
img = op3(img)
print("Image.type: {}, Image.shape: {}".format(type(img), img.size))
# Show the result
plt.subplot(1, 2, 1)
plt.imshow(img_ori)
plt.title("original image")
plt.subplot(1, 2, 2)
plt.imshow(img)
plt.title("transformed image")
plt.show()
Image.type: <class 'PIL.Image.Image'>, Image.shape: (356, 200)
Image.type: <class 'PIL.Image.Image'>, Image.shape: (569, 320)
Image.type: <class 'PIL.Image.Image'>, Image.shape: (280, 280)
Image.type: <class 'PIL.Image.Image'>, Image.shape: (360, 360)
text
This example will transform the given text by using the Transforms in the text module.
Eager mode of Text Transforms supports numpy.array type data as input parameters. For more examples, please refer to: Illustration Of Text Transforms
import mindspore.dataset.text.transforms as text
import mindspore as ms
# Apply UnicodeCharTokenizer to input immediately
txt = "Welcome to Beijing !"
txt = text.UnicodeCharTokenizer()(txt)
print("Tokenize result: {}".format(txt))
# Apply ToNumber to input immediately
txt = ["123456"]
to_number = text.ToNumber(ms.int32)
txt = to_number(txt)
print("ToNumber result: {}, type: {}".format(txt, txt[0].dtype))
Tokenize result: ['W' 'e' 'l' 'c' 'o' 'm' 'e' ' ' 't' 'o' ' ' 'B' 'e' 'i' 'j' 'i' 'n' 'g'
' ' '!']
ToNumber result: [123456], type: int32
audio
This example will transform the given audio by using the Transforms in the audio module.
Eager mode of Audio Transforms supports numpy.array type data as input parameters. For more examples, please refer to: Illustration Of Audio Transforms
import numpy as np
import matplotlib.pyplot as plt
import scipy.io.wavfile as wavfile
from download import download
import mindspore.dataset as ds
import mindspore.dataset.audio as audio
ds.config.set_seed(5)
# citation: LibriSpeech http://www.openslr.org/12
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/84-121123-0000.wav"
download(url, './84-121123-0000.wav', replace=True)
wav_file = "84-121123-0000.wav"
def plot_waveform(waveform, sr, title="Waveform"):
if waveform.ndim == 1:
waveform = waveform[np.newaxis, :]
num_channels, num_frames = waveform.shape
time_axis = np.arange(0, num_frames) / sr
figure, axes = plt.subplots(num_channels, 1)
axes.plot(time_axis, waveform[0], linewidth=1)
axes.grid(True)
figure.suptitle(title)
plt.show()
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/84-121123-0000.wav (65 kB)
file_sizes: 100%|███████████████████████████| 67.0k/67.0k [00:00<00:00, 605kB/s]
Successfully downloaded file to ./84-121123-0000.wav
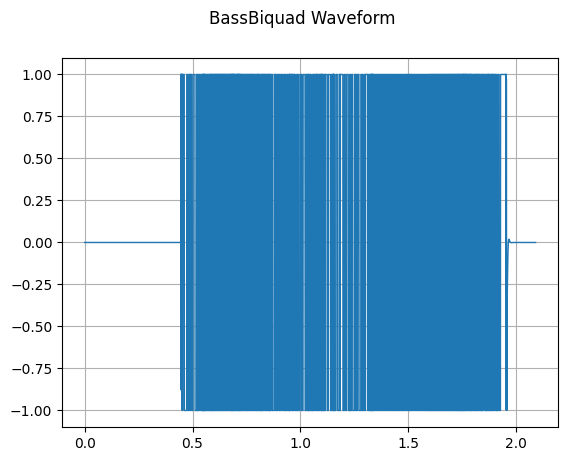
Transform BassBiquad performs a two-pole low-shelf filter on the input audio signal.
sample_rate, waveform = wavfile.read(wav_file)
bass_biquad = audio.BassBiquad(sample_rate, 10.0)
transformed_waveform = bass_biquad(waveform.astype(np.float32))
plot_waveform(transformed_waveform, sample_rate, title="BassBiquad Waveform")
transforms
This example will transform the given data by using the general Transform in the transforms module.
Eager mode of general Transform supports numpy.array type data as input parameters.
import numpy as np
import mindspore.dataset.transforms as trans
# Apply Fill to input immediately
data = np.array([1, 2, 3, 4, 5])
fill = trans.Fill(0)
data = fill(data)
print("Fill result: ", data)
# Apply OneHot to input immediately
label = np.array(2)
onehot = trans.OneHot(num_classes=5)
label = onehot(label)
print("OneHot result: ", label)
Fill result: [0 0 0 0 0]
OneHot result: [0 0 1 0 0]