Pipeline Parallel
![]()
Overview
In recent years, the scale of neural networks has increased exponentially. Limited by the memory on a single device, the number of devices used for training large models is also increasing. Due to the low communication bandwidth between servers, the performance of the conventional hybrid parallelism data parallel + model parallel is poor. Therefore, pipeline parallelism needs to be introduced. Pipeline parallel can divide a model in space based on stage. Each stage needs to execute only a part of the network, which greatly reduces memory overheads, shrinks the communication domain, and shortens the communication time. MindSpore can automatically convert a standalone model to the pipeline parallel mode based on user configurations.
Hardware platforms supported by the pipeline parallel model include Ascend, GPU, and need to be run in Graph mode.
Related interfaces:
mindspore.parallel.auto_parallel.AutoParallel(network, parallel_mode="semi_auto"): Encapsulates the specified parallel mode via static graph parallelism, where
networkis the top-levelCellor function to be encapsulated, andparallel_modetakes the valuesemi_auto, indicating a semi-automatic parallel mode. The interface returns aCellencapsulated with parallel configuration.mindspore.parallel.auto_parallel.AutoParallel.pipeline(stages=1, output_broadcast=False, interleave=False, scheduler='1f1b'): Configures pipeline parallelism settings.
stagesspecifies the total number of partitions for pipeline parallelism. If usingWithLossCellto encapsulatenet, the name of theCellwill be changed and the_backboneprefix will be added.output_broadcastdetermines whether to broadcast the output of the final pipeline stage to all other stages during inference.interleaveshows that whether to enable interleaving scheduling.schedulerdefines the pipeline scheduling strategy. Supported values:gpipe/1f1b/seqpipe/seqvpp/seqsmartvpp/zero_bubble_v.mindspore.parallel.Pipeline(network, micro_size=1, stage_config={"cell1":0, "cell2":1}): Pipeline parallelism requires wrapping the
networkwith an additional layer ofPipeline,micro_sizespecifies the number of MicroBatch, which are finer-grained splits of a MiniBatch to improve hardware utilization. If usingWithLossCellto encapsulatenetwork, the name of theCellwill be changed and the_backboneprefix will be added. The final loss is the accumulation of losses from all MicroBatches.stage_configindicates the stage assignment for each Cell in the network.micro_sizemust be greater than or equal to the number ofstages.mindspore.parallel.PipelineGradReducer(parameters, scale_sense=1.0, opt_shard=None): pipeline parallelism requires using
PipelineGradReducerfor gradient reduction. Because the output of pipeline parallelism is derived by the addition of several micro-batch outputs, as the gradient does.mindspore.parallel.sync_pipeline_shared_parameters(net): Synchronize pipeline parallel stage shared parameters.
Basic Principle
Pipeline parallel is the splitting of operators in a neural network into multiple stages, and then mapping the stages to different devices, so that different devices can compute different parts of the neural network. Pipeline parallel is suitable for graph structures where the model is linear.
As shown in Figure 1, the network of 4 layers of MatMul is split into 4 stages and distributed to 4 devices. In forward calculations, each machine sends the result to the next machine through the communication operator after calculating the MatMul on the machine, and at the same time, the next machine receives (Receive) the MatMul result of the previous machine through the communication operator, and starts to calculate the MatMul on the machine; In reverse calculation, after the gradient of the last machine is calculated, the result is sent to the previous machine, and at the same time, the previous machine receives the gradient result of the last machine and begins to calculate the reverse of the current machine.
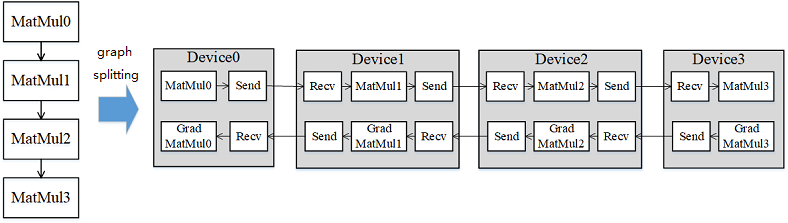
Figure 1: Schematic diagram of graph splitting in pipeline parallel
GPipe Pipeline Parallel Scheduler
Simply splitting the model onto multiple devices does not bring about a performance gain, because the linear structure of the model has only one device at work at a time, while other devices are waiting, resulting in a waste of resources. In order to improve efficiency, the pipeline parallel further divides the small batch (MiniBatch) into more fine-grained micro batches (MicroBatch), and adopts a pipeline execution sequence in the micro batch, so as to achieve the purpose of improving efficiency.
As shown in Figure 2. The small batches are cut into 4 micro-batches, and the 4 micro-batches are executed on 4 groups to form a pipeline. The gradient aggregation of the micro-batch is used to update the parameters, where each device only stores and updates the parameters of the corresponding group. where the white ordinal number represents the index of the micro-batch.
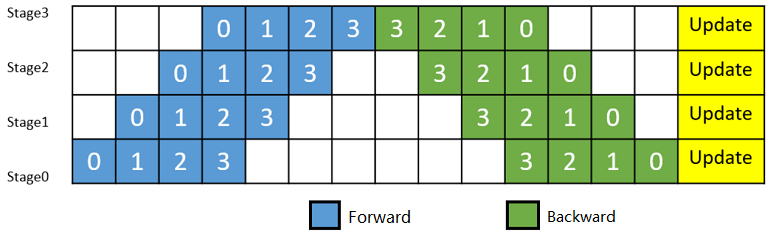
Figure 2: Schematic diagram of a pipeline parallel execution timeline with MicroBatch
1F1B Pipeline Parallel Scheduler
In MindSpore's pipeline parallel implementation, the execution order has been adjusted for better memory management.
As shown in Figure 3, the reverse of the MicroBatch numbered 0 is performed immediately after its forward execution, so that the memory of the intermediate result of the numbered 0 MicroBatch is freed earlier (compared to Figure 2), thus ensuring that the peak memory usage is lower than in the way of Figure 2.
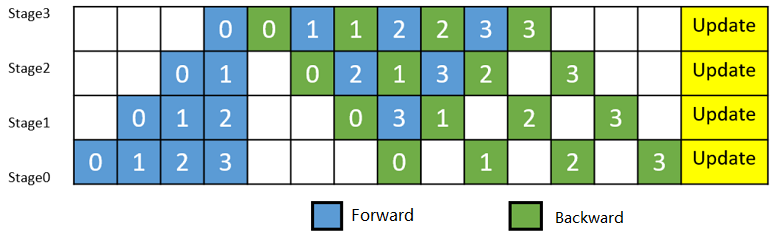
Figure 3: MindSpore Pipeline Parallel Execution Timeline Diagram
Interleaved Pipeline Scheduler
In order to improve the efficiency of pipeline parallelism and reduce the proportion of bubbles, Megatron LM proposes a new pipeline parallel scheduling strategy called "interleaved pipeline". Traditional pipeline parallelism typically places several consecutive model layers (such as Transformer layers) on a stage, as shown in Figure 3. In the scheduling of interleaved pipeline, each stage performs interleaved calculations on non-continuous model layers to further reduce the proportion of bubbles with more communication, as shown in Figure 4. For example, in traditional pipeline parallelism, each stage has 2 model layers, namely: stage 0 has layers 0 and 1, stage 1 has layers 2 and 3, stage 2 has layers 4 and 5, and stage 3 has layers 6 and 7, while in interleaved pipeline, stage 0 has layers 0 and 4, stage 1 has layers 1 and 5, stage 2 has layers 2 and 6, and stage 3 has layers 3 and 7.
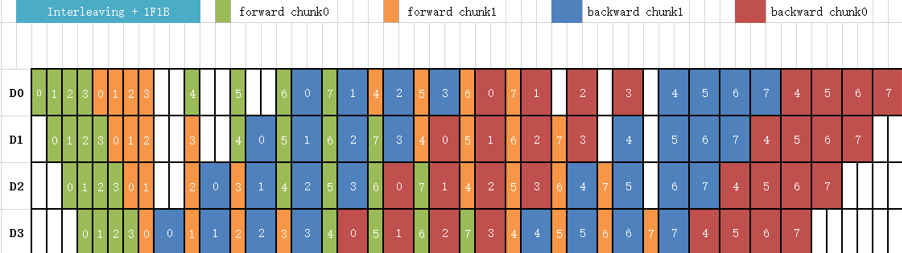
Figure 4: Scheduler of Interleaved Pipeline
MindSpore Interleaved Pipeline Scheduler
MindSpore has made memory optimization based on Megatron LM interleaved pipeline scheduling by moving some forward execution sequences back, as shown in Figure 5, which can accumulate less MicroBatch memory during memory peak hours.
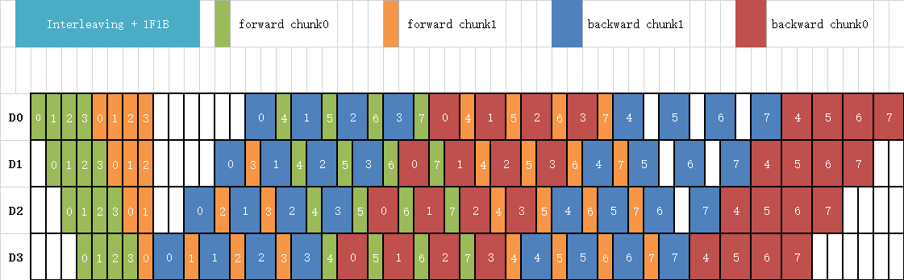
Figure 5: MindSpore Scheduler of Interleaved Pipeline
zero_bubble_v Pipeline Scheduler
As shown in Figure 6, zero_bubble_v pipeline parallelism further improves pipeline parallel efficiency and reduces bubble rate by dividing the backward computation into gradient computation and parameter update. For consecutive model layers, the stage value first increases and then decreases, the pipeline_segment of the first half of layers is 0, and the pipeline_segment of the second half of layers is 1. For example, for 8 layers, when the stage size is 4, stage0 has layer0 and layer7, stage1 has layer1 and layer6, stage2 has layer2 and layer5, stage 3 has layer3 and layer4, the pipeline_segment of layer0 to layer3 is 0, and the pipeline_segment of layer4 to layer7 is 1.
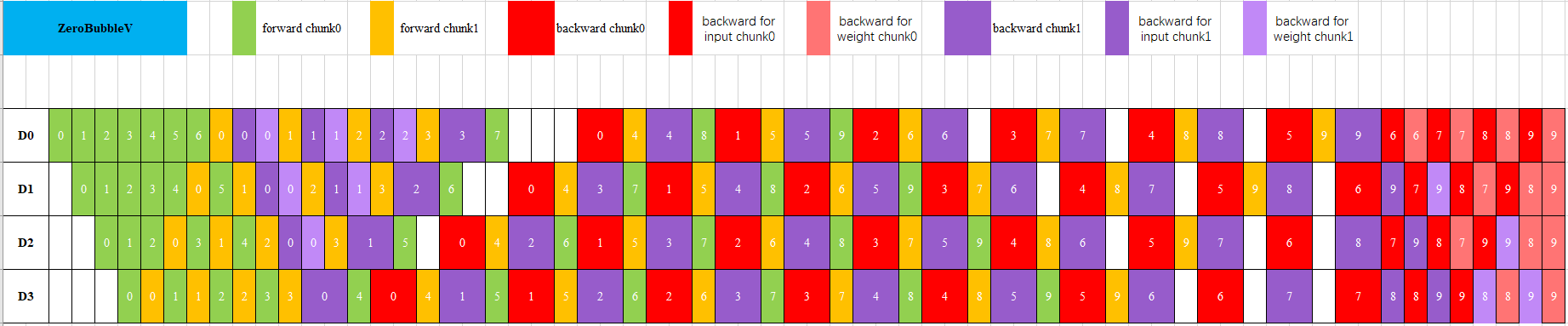
Figure 6: zero_bubble_v Pipeline Scheduler