MindSpore 1.2:国内首个支持千亿参数大模型训练的AI计算框架
MindSpore 1.2:国内首个支持千亿参数大模型训练的AI计算框架
国内首个支持千亿参数大模型训练的AI计算框架MindSpore 1.2正式发布,无论是动态图分布式训练效率的大幅提升,还是一键模型迁移、CA鲁棒性标准达标、深度分子模拟及量子机器学习等,都能让AI开发者尽享AI开发。

老规矩上视频!(请点击“老规矩上视频!”并在微信里进行视频观看)
MindSpore开源周年狂欢,量子机器学习与深度分子模拟等巨量新特性来袭!
先回顾下我们在一周年中发布的新特性,再来看看这次新版本还有哪些新特性~

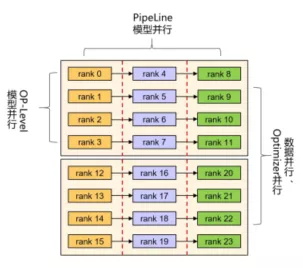
如何在大集群下高效训练千亿至万亿参数模型?当前主要面临两个挑战:切分难——用户需要综合考虑参数量、计算量、计算类型、集群带宽拓扑和样本数量等,才能设计出性能较优的并行切分策略;编码难——模型编码除了要考虑算法以外,还需要编写大量并行切分和通信代码。
MindSpore采用多维度自动并行,通过数据并行、模型并行、Pipeline并行、异构并行、重复计算、高效内存复用及拓扑感知调度,降低通信开销,实现整体迭代时间最小(计算时间+通信时间)。

相较于移动终端设备,IoT设备上系统资源有限,对ROM空间占用、运行时内存和功耗要求较高,为了使得IoT设备上也能方便快速的部署AI应用,MindSpore Lite此次正式开源了代码自动生成工具Codegen,旨在将模型编译为极简的代码,用于推理。
Codegen可对接MindSpore Lite的NNACL算子库和ARM的CMSIS算子库,支持生成可在X86/ARM64/ARM32A/ARM32M平台部署的推理代码。
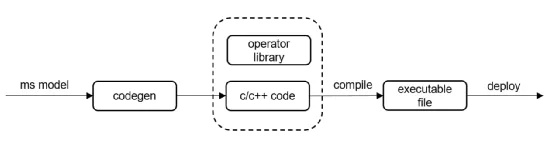
易上手:用户输入ms模型文件,并指定推理执行硬件平台,即可生成与该模型执行相关的代码、编译构建脚本。
极致优化:无图引擎,模型即代码,极小ROM占用完成推理。算子数据重排、内存分配移至离线完成,节省了初始化时间;同时引入Conv & BN & Pooling融合,Conv分块计算等技术,达到极致性能。我们的方案在华为内部应用广泛,比如在Huawei Watch GT系列的智慧抬腕亮屏算法中,推理内存占用仅1KB,时延低至5ms。
官网快速入门:

MindSpore在MindInsight部件中集成了的可解释AI能力:显著图可视化、反事实解释和可解释AI评估体系(度量体系),旨在帮忙开发者更好进行模型调优。
显著图可视化和反事实解释:能够为图片分类模型的推理结果,标识影响分类结果的关键特征,方便理解分类依据,帮助分析定位分类错误原因,加速模型调优。
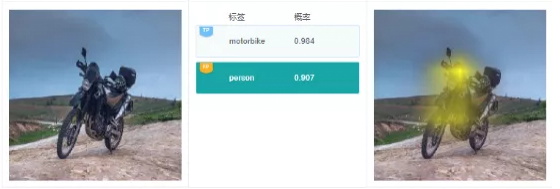
这个例子中,有个错误预测标签“person”,根据显著图可视化结果,高亮区域在摩托车的前部,便于针对性的分析误判的可能原因。

在这个例子中,图片被错分为“cat”,使用基于层级遮掩的反事实解释,发现对这个分类结果影响最可能的区域是右边遮掩后留下的区域,便于用户发现判断错误的缘由,从而帮助调优。
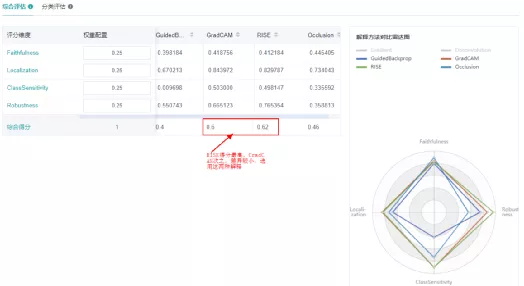
评估体系:面向各种解释方法,给出在具体场景下,选中解释方法在不同度量方法下的解释效果得分,助力用户选择最优的解释方法,从而更好的帮助模型调优。
查看教程:
https://www.mindspore.cn/tutorial/training/zh-CN/r1.1/advanced_use/model_explaination.html
MindSpore官方资料
GitHub : https://github.com/mindspore-ai/mindspore
Gitee:[https : //gitee.com/mindspore/mindspore](https : //gitee.com/mindspore/mindspore)
官方QQ群 : 871543426
扫描下方二维码加入MindSpore项目↓
