昇思MindSpore 2.7版本正式发布,支持ZeroBubbleV流水线并行调度提升训练效率,升级适配vLLM V1架构,采用组合优化提升DeepSeek-V3推理性能
昇思MindSpore 2.7版本正式发布,支持ZeroBubbleV流水线并行调度提升训练效率,升级适配vLLM V1架构,采用组合优化提升DeepSeek-V3推理性能
经过昇思MindSpore开源社区开发者们几个月的开发与贡献,现正式发布昇思MindSpore2.7版本。
在大模型训练性能提升方面,新增支持ZeroBubbleV流水线并行调度进一步降低bubble耗时,并创新性实现重计算通信掩盖技术,提升大模型重计算部分训练效率;
在生态兼容扩展方面,升级适配vLLM v0.8.3版本和V1架构,并采用多项组合优化显著提升DeepSeek-V3推理性能;
在强化学习训推性能提升方面,支持推理均匀采样、动态packing训练,提升吞吐效率,同时支持6D并行权重重排技术,实现任意模型并行策略下的权重重排,以及支持强化学习断点续训,实现灵活的训练调试、部署;
在工具效率提升方面,提供了在线监控平台(msMonitor),能够实现快速性能诊断,同时msprobe工具支持静态图模块级Dump与自动比对,提升问题定位效率;
下面就为大家详细解读昇思2.7版本的关键特性。
——大模型训练性能提升——
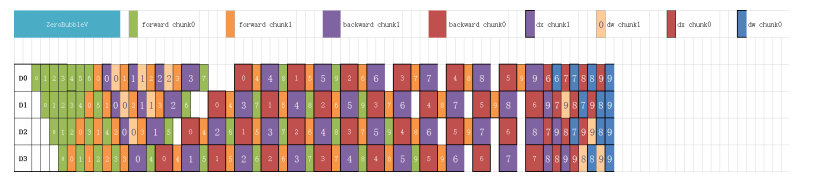
1 支持ZeroBubbleV流水线并行调度,进一步降低bubble耗时,实现更高比例的计算通信掩盖
流水线并行是大规模分布式训练的常用并行方式,但是流水线并行会不可避免的引入bubble,从而降低设备利用率。昇思MindSpore2.7版本新增支持ZeroBubbleV流水线调度方案,如下图所示,将dx和dw的计算分离,并把dw填充到bubble中进行计算,进一步缩小了机器的空闲时间,并在正反向交替执行阶段支持1B1F融合掩盖,提升训练效率。
参考链接:https://www.mindspore.cn/docs/zh-CN/master/features/parallel/pipeline_parallel.html
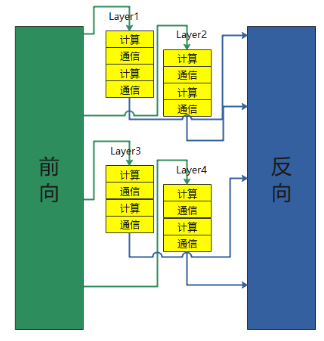
2 实现重计算通信掩盖技术,提升大模型重计算部分训练效率
随着Transformer模型层数突破千级,传统训练模式面临两大核心挑战:1) 显存爆炸:反向传播需存储中间激活值,百层网络缓存占用超400GB; 2) 通信阻塞:分布式训练中通信占比超50%,计算利用率不足60%。
为此,针对显存开销,业界往往选用重计算方案来大幅消减激活值开销,选用完全重计算可以最大化的降低激活值显存开销,但是此时重计算本身开销也较大。
昇思MindSpore2.7版本创新性实现了重计算通信掩盖架构,通过分组流水线机制提升重计算部分的效率,如下图所示,将重计算层动态划分为两两一组(如Layer1、Layer2为A组,Layer3、Layer4为B组),每组内实现两个重计算Layer之间的计算与通信的掩盖,实现重计算模块性能提升15%。
——生态兼容扩展——
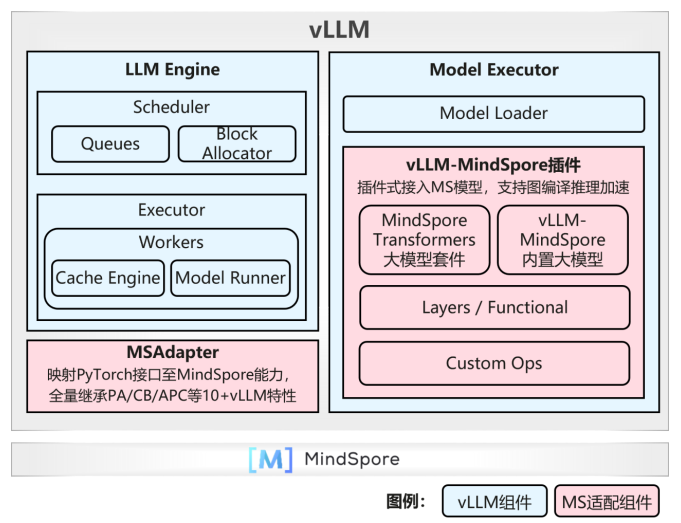
3 升级适配vLLM v0.8.3版本和V1架构,组合优化显著提升DeepSeek-V3推理性能
昇思MindSpore 2.7版本配套的vLLM-MindSpore插件,升级适配了vLLM v0.8.3版本,支持V0和V1架构,新增支持了Prefix Caching、Chunked Prefill、Multi-step Scheduling、MTP、Multi-LoRA等服务化特性。同时,改用动态图(PyNative)和JIT(Just-In-Time)编译实现接入vLLM后端的昇思MindSpore大模型,显著提升了推理后处理性能。
同时,昇思MindSpore采用多项优化组合,显著提升了DeepSeek-V3/R1为代表的稀疏MoE大模型推理性能:
1. 混合并行:支持面向Attention和MoE单元,分别部署张量并行(TP)、数据并行(DP)、专家并行(EP)组合方案,可提升DeepSeek-V3/R1多请求吞吐性能35%+。
2. 推理融合算子:新增接入MoeInitRoutingQuant、MultiLatentAttention等面向稀疏MoE计算的融合算子,及Combine/Dispatch等通信优化算子,降低算子下发和等待时延。
3. 模型量化:改进了W8A8静态量化,降低量化推理的运行时开销,并提升Function Call等场景的精度。新增支持W4A16量化推理,支持单台Atlas 800I A2 (64GB)服务器部署DeepSeek-V3/R1模型。
通过叠加上述性能优化技术,2台Atlas 800I A2(64GB)部署DeepSeek-R1/V3 W8A8量化推理,在Decode时延≤100ms约束条件下,256序列输入/输出非首Token吞吐可达2600token/s以上,进入开源推理方案第一梯队。
参考链接:https://www.mindspore.cn/vllm_mindspore/docs/zh-CN/master/index.html
——强化学习训推性能提升——
4 支持推理均匀采样,提高数据生成端到端吞吐
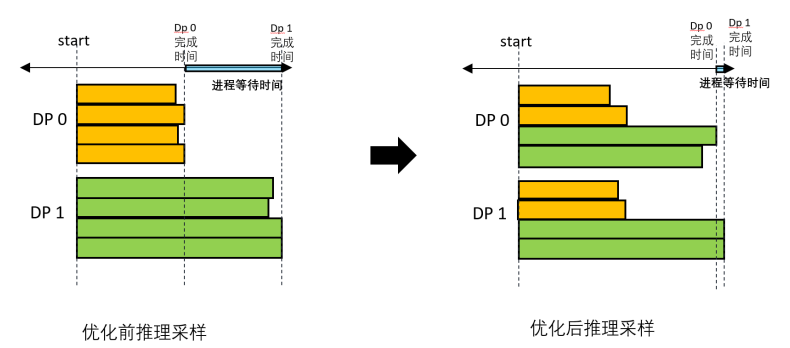
传统的强化学习经验收集过程中,不同的dp处理自己对应的问题,但是由于不同问题之间的回答长度是严重不均衡的,所以会引起较大的“等待空泡“,从而导致端到端性能差,甚至引起进程因等待时间过长而中断的问题。MindSpore RLHF最新版本中采用了推理均匀采样技术,如下图所示,我们将不同问题均匀分配在各个dp上,从分布上尽量让各个推理实例的负载尽量均衡,从而可以大量减少不同dp之间的等待时间,使得系统能更加稳定运行,在推理性能上约有5-10%的收益。
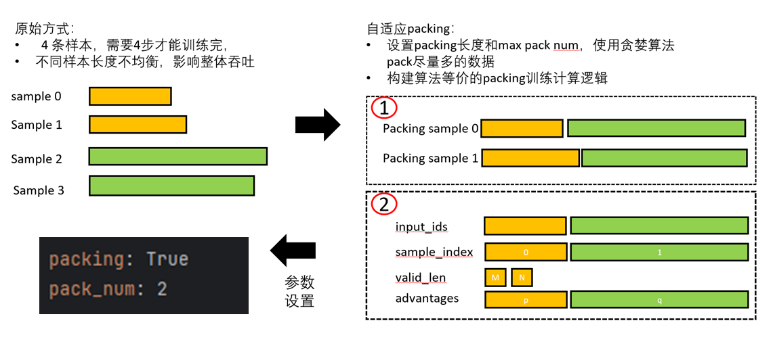
5 支持强化学习动态packing训练,实现训练吞吐翻倍
在预训练和微调阶段,packing训练已经被证明可以较快地提升端到端训练速度,并且对训练的效果的影响甚微。在MindSpore RLHF最新版本中提出了算法等价的动态packing训练方案,如下图所示,其主要功能是在loss函数等价的前提下,会根据预先设置的“最大pack长度”和“最大pack数量”,动态地将样本拼接到一起,从而可以最大化缩减样本的数量,且不对样本做截断(可能会影响样本质量)。在实际测试中,动态packing可以减少40%左右的训练时间,且训练效果没有下降。
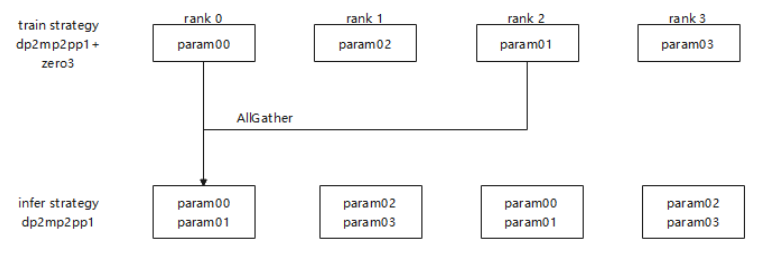
6 支持6D并行权重重排技术,实现任意模型并行策略下的权重重排
MindSpore RLHF权重重排通过昇思MindSpore训练网络的Layout信息和推理网络的Layout信息来进行重排布算子列表的推导。Layout信息是指通过昇思MindSpore内部一种表达Tensor排布的方式,通过设备矩阵Device Matrix以及分片的映射Tensor Map来描述当前权重在哪些维度被切分,各个切片分部到哪些Rank上。Layout信息可以表达现有的通用并行策略,如DP、TP、CP、PP、优化器并行、EP等6D并行。
如下图所示,当前的6D并行的权重重排方案,相比于业界case-by-case手写的重排,在泛化性上有较大优势,只要能通过昇思MindSpore自带的Layout来表达的切分策略,都可以通过一段统一代码进行重排列表的推导并执行,完成在线重排布。
7 支持强化学习断点续训,实现灵活的训练调试、部署
在强化学习中,随着模型规模和集群规模增大,训练也会像微调和预训练那样可能出现训练中断情况,因此。构建针对强化学习的断点续训就非常重要了。在MindSpore RLHF最新版本中实现了针对强化学习场景的断点续训,在推理、训练、reference模型的加载上,我们采用的策略是,首先加载训练的权重和优化器权重,保证其训练状态一致;然后利用训练权重和6D权重重排技术,将权重排布到推理和ref模型上,从而极大减少模型加载的IO时间。当前实现的断点续训功能可以完全对接中断前的loss和训练状态,实现真正意义上的“续训”。
参考链接:https://gitee.com/mindspore/mindrlhf
——工具效率提升——
8 提供在线监控平台(msMonitor),实现快速性能诊断
在AI计算领域,随着模型规模不断扩大,训练性能优化已成为开发者面临的关键挑战。特别是在大规模分布式训练场景下,传统性能监测方案存在明显不足:其一,采用被动式监测策略,往往在性能抖动发生后才能触发数据采集,导致问题定位存在显著延迟;其二,面对训练过程中产生的海量性能数据(通常达数百GB量级),传统方案的解析和转储效率低下,进一步延长了问题诊断周期。这些缺陷不仅影响排障效率,更会造成计算资源浪费。
昇思MindSpore2.7版本新增了MindSpore Profiler接入在线监控平台功能,用户在使用MindSpore Profiler框架集群训练场景下能够通过在线监控平台的monitor功能(常态监测)实时观察到训练的性能劣化点,实现性能问题的初步定位,后续可以通过在线监控平台的Profiler trace dump功能(精准采集)采集完整的性能数据,分析、定位性能瓶颈点,从而帮助开发者实现更高效的模型性能优化。
通过 "常态监测+精准采集" 的组合策略,msMonitor既能满足集群长稳训练时的实时监测需求,又能针对性能瓶颈进行定向分析,显著提升模型训练效率。
参考链接:https://gitee.com/ascend/mstt/tree/master/msmonitor
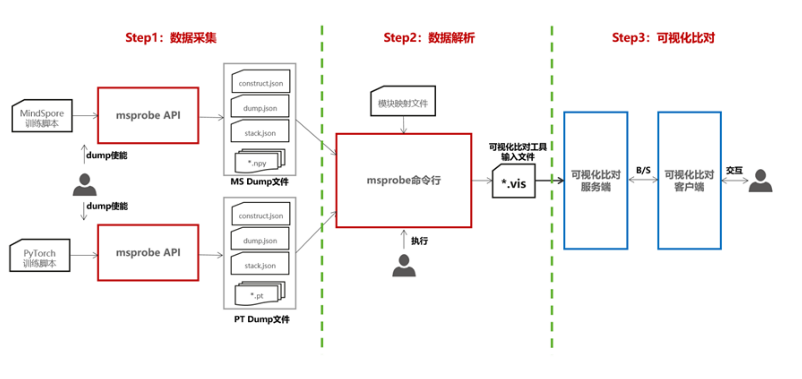
9 msprobe工具支持静态图模块级Dump与自动比对,提升问题定位效率
针对大模型场景下静态图精度定位困难问题,msprobe工具新增支持静态图模块级Dump与自动比对功能。如下图所示,首先通过msprobe工具用户可对网络模块的正反向输入输出进行真实数据Dump或max、min、mean、l2norm统计量Dump;进而根据mapping文件建立MindSpore Transformers与Megatron网络模块名称的对应关系;最后,借助可视化工具可将网络层级关系直观展现出来并计算出与标杆数据的相关精度指标,方便快速找到产生精度问题的模块,有效提升昇思MindSpore静态图下同框架与跨框架精度问题定位效率。