昇思MindSpore 2.6版本正式发布,支持DeepSeek端到端全流程开箱即用,主流SOTA模型Day0迁移,从易用到好用
昇思MindSpore 2.6版本正式发布,支持DeepSeek端到端全流程开箱即用,主流SOTA模型Day0迁移,从易用到好用
经过昇思MindSpore开源社区开发者们几个月的开发与贡献,现正式发布昇思MindSpore2.6版本。
本次版本发布三大特性升级:
1. 支持DeepSeek MoE模型训推全流程开箱即用,预训练、后训练特性升级:全面支持Dropless MoE训练,实现基于GRPO算法的强化学习训练
2. 兼容主流生态,插件式接入vLLM生态,openEuler协同优化,DeepSeek部署20分钟开箱即用
3. 从易用到好用:支持MindSpeed加速库,主流SOTA模型Day0迁移,一行代码配置自动并行,接口功能解耦,调试调优工具升级
下面就为大家详细解读昇思2.6版本的关键特性。
——DeepSeek全栈能力支持——
1 全面支持Dropless MoE训练,分层通信+前反向通信掩盖加速DeepSeek V3大集群部署
基于静态图动态Shape能力和Sharding自动重排布能力,昇思MindSpore2.6版本新增了Morph自定义并行,允许用户自主在前端脚本中控制通信算子的插入,极大提升了静态图并行的易用性和灵活性。同时昇思MindSpore MoE在Capacity模式的基础上,利用Morph封装高动态、非对齐Shape的专家并行,并嵌入基于自动重排布的整网,从而实现了静态图下的Dropless MoE训练。此外通过异构缓存、融合算子、反向通信掩盖等优化手段进一步提升端到端性能。
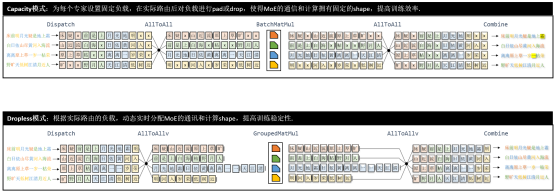
- 异构缓存:MoE训练的AllToAllv通信Shape依赖于数据的实时路由状态,通信算子下发需要提前将路由状态从device搬运到host上,从而引发D2H拷贝和算子下发流中断。而当前可以通过昇思MindSpore的异构能力,在首次D2H后于Host侧缓存其路由状态,把下发流中断的次数从4次或6次(含重计算)降到1次,实测DeepSeek V3上有5%的性能收益。
- 融合算子:在Dropless MoE的实现中利用permute和unpermute融合算子对数据进行排序和反排序,利用GMMAssignAdd融合算子合并MoE dW的计算和梯度累积,利用MMAssignAdd融合算子合并MLA部分的dW的计算和梯度累积,Swiglu将激活函数的计算融合成一个算子,并允许将两个前置矩阵计算合二为一。RoPE融合算子整合整个旋转位置编码的算法,加速相关计算。实测DeepSeek V3上有10%的性能收益。
- 反向通信掩盖:将反向的Combine AllToAllv与共享专家的反向重叠,将Dispatch AllToAllv与MoE dW的计算重叠,做到反向的计算通信掩盖,实测DeepSeek V3上有6%的收益。
在大规模集群上部署DeepSeek V3 671B,高稀疏度和大规模专家并行会导致AllToAll通讯占据30%左右的开销,而昇思MindSpore MoE通过分层通讯和前反向通信掩盖实现通讯性能优化。
参考链接:https://gitee.com/mindspore/mindformers/tree/dev/research/deepseek3
2 通过图编译+组合量化,提升推理系统吞吐率,显存资源占用减半
昇思MindSpore2.6版本针对DeepSeek-V3/R1的网络结构特点与MLA结构,实现和优化了更高效的推理网络。
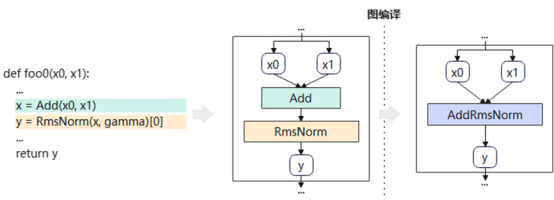
- 图生成:MindSpore通过JIT编译自动将模型的python类或者函数编译成一张完整的计算图,JIT编译提供了多种方式(ast/bytecode/trace)以满足不同场景的用途,覆盖了绝大部分Python语法。
- 算子融合:基于计算图通过自动模式匹配实现算子融合,在整图范围内将多种小算子组合,融合成单个大颗粒的算子。大算子既减少Host下发的开销,同时也大大缩短了Device的计算时延。
- 动态shape支持:构建了Shape推导、Tiling数据计算、下发执行的三级流水线,实现Host计算和Device计算的掩盖,有效提升了计算图动态Shape执行效率。
同时,为降低DeepSeek-R1大模型的部署成本,昇思MindSpore2.6版本提供了金箍棒模型压缩工具,无需侵入修改模型网络脚本,即可构造和验证多种组合量化方案。
参考链接:
MindSpore DeepSeek-V3/R1推理模型脚本:https://gitee.com/mindspore/mindformers/tree/dev/research/deepseek3
MindSpore DeepSeek-R1推理模型仓:https://modelers.cn/models/MindSpore-Lab/DeepSeek-R1-W8A8
3 支持GRPO训推全流程一体化部署,实现基于GRPO算法的强化学习训练
随着DeepSeek R1的出圈,GRPO算法受到业界广泛关注。GRPO(Group Relative Policy Optimization,组相对策略优化)是针对数学等逻辑推理任务提出的强化学习训练的算法,通过GRPO算法的大规模后训练得到的DeepSeek R1模型在逻辑推理能力上得到了显著提升,涌现出了长思维链和反思等深度思考能力,其在数学和编程任务上的表现已超越或媲美OpenAI o1系列模型。
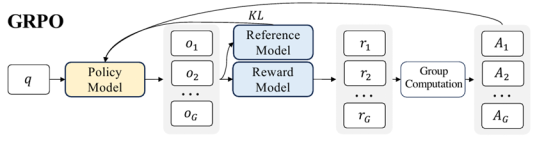
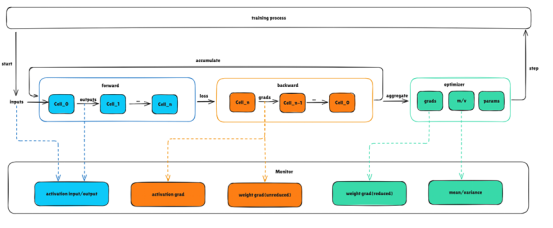
GRPO训练流程示意
与以往开发的单模型训练代码相比,GRPO强化学习训练流程涉及策略模型与参考模型,通过策略模型生成数据,利用参考模型和奖励函数计算Loss,然后进行策略模型的训练,如上图所示,这个过程需要模型在推理和训练状态间的频繁切换,并涉及参考模型和策略模型推理、训练三份权重,对训练性能和显存管理提出了更高的要求,对于强化学习开发者来说,快速完成算法开发和模型训练是个不小的挑战。昇思MindSpore2.6版本为GRPO强化学习训练流程提供了优化技术:
- 组件化解耦训练流程与模型定义,支持用户自定义修改模型结构、奖励函数、训练超参等。
- 训推共部署,实现训练和推理权重在线快速自动重排,避免权重文件落盘操作,节省离线转换保存权重文件的时间开销。
- 通过异构内存Swap技术,按需加载模型至显存,避免训练和推理的权重同时存在,支持更大规模模型的训练任务。
基于上述技术,昇思MindSpore实现了GRPO强化学习训练全流程打通,并为强化学习开发者提供了多种训练接口,支持算法快速实现。
参考链接:https://gitee.com/mindspore/mindrlhf/tree/master/examples/grpo
4 SAPP流水线负载均衡工具支持DeepSeek类异构模型,提升调优性能25%
DeepSeek的架构中不同的MoE层专家数存在着区别,并且还引入了MTP层,这让DeepSeek模型的不同层之间内存和计算建模有着显著差异。如果手工调优的话,需要工程师多次实验总结不同层处在不同stage时的内存变化规律,相比于Llama系列模型复杂度和工作量都是成倍的提升。
面对DeepSeek一类的异构模型,昇思MindSpore2.6版本中SAPP流水负载均衡工具通过执行序约束实现有效兼容。下表展示了DeepSeek-V3 671B调优的实例,在大规模集群实测训练性能tokens/s提高25%。
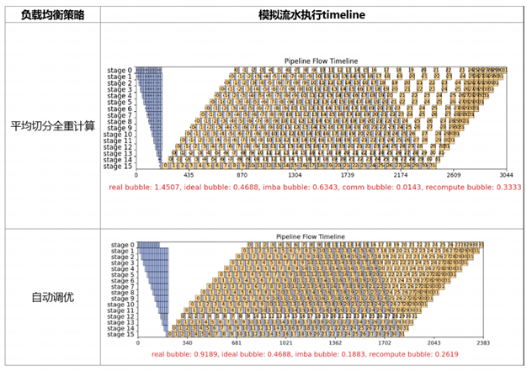
参考链接:https://gitee.com/mindspore/toolkits/tree/master/autoparallel/pipeline_balance
——生态兼容扩展——
5 插件式接入vLLM生态,openEuler协同优化,DeepSeek部署20分钟开箱即用
昇思MindSpore2.6版本开发了vllm-mindspore独立插件,将大模型推理能力接入到了vLLM生态中。对于vLLM服务化和调度组件,将PyTorch 接口映射至昇思MindSpore能力调用,全面支持其vLLM Continual Batching、PagedAttention等核心特性。通过将vLLM后端的模型、网络层、自定义算子等组件,替换为昇思孵化、基于前端并行的大模型推理模块,继承昇腾+昇思的高性能推理能力。
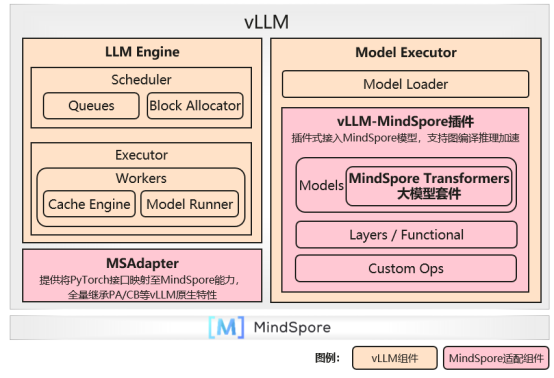
同时,昇思MindSpore联合OpenAtom openEuler(简称"openEuler")开源社区,面向基于鲲鹏+昇腾的DeepSeek大模型推理,开展了OS+AI基础软件的分层协同优化,发布了vLLM+MindSpore+openEuler的DeepSeek开源解决方案镜像,支持一键式推理服务部署,20分钟即可完成模型开箱,单请求吞吐可达18.5tokens/s,192请求吞吐可达1350tokens/s。
参考链接:https://gitee.com/mindspore/vllm-mindspore
——框架易用性提升——
6 并行配置项优化,一行代码配置自动并行
昇思MindSpore分布式并行接口主要使用set_auto_parallel_context()进行配置,配置项达25+,覆盖各类并行设置,这样对使用和理解带来一定门槛,例如:context为全局作用域,当一个进程中存在多个网络且每个网络的并行策略不一致时,需要在合适的位置进行重新配置,也需要深度熟悉并行策略冲突场景。
昇思MindSpore 2.6版本中新增AutoParallel类,支持对单个网络进行并行配置。对已构建的网络一行代码即可配置自动并行:
parallel_net = AutoParallel(single_net, parallel_mode="semi_auto")
parallel_mode可以选择sharding_propagation模式或recursive_programming模式,再根据各类并行场景,使用相对应接口进行开发。例如:通过parallel_net.hsdp()接口使能优化器并行,通过parallel_net.pipeline()接口使能流水线并行和调度策略。
参考链接:https://www.mindspore.cn/docs/zh-CN/master/api_python/mindspore.parallel.html
7 差异化接口功能对齐主流生态,支持MindSpeed加速库
为降低大模型迁移适配的门槛与工作量,昇思MindSpore 2.6版本构建了MSAdapter适配层,桥接MindSpeed加速库,在不改变用户原有使用习惯下,实现业界主流生态代码快速迁移到昇思MindSpore上,通过MindSpeed支持主流大模型,帮助用户高效使用昇腾算力。
用户可以通过MindSpeed-LLM文档指导,获取开箱即用的MindSpore版DeepSeek-V3脚本代码与数据集,快速体验。
参考链接:https://gitee.com/ascend/MindSpeed-Core-MS/blob/feature-0.2/docs/deepseekv3.md
8 全局set_context接口参数优化,提供职责单一的API接口使能编译/运行时等功能,提升代码可读性
昇思MindSpore2.6版本针对mindspore.set_context()接口的50+配置进行功能解耦,重新设计并推出职责单一的API接口,实现编译、运行时、设备管理等功能。
8.1 新增runtime/device_context模块,提升内存/硬件资源管理易用性
新增mindspore.runtime模块封装了执行、内存、流、事件的接口,方便在Python层调度硬件资源。例如:原set_context下内存相关参数max_device_memory/variable_memory_max_size /mempool_block_size/memory_optimize_level均在设置memory相关功能,优化合并为runtime.set_memory()接口,细颗粒度的memory设置改为函数入参,以此提升接口的可读性,方便理解并使用。
参考链接:https://www.mindspore.cn/docs/zh-CN/master/api_python/mindspore.runtime.html
8.2 新mindspore.jit使能动态图+编译能力,提升开发易用性
mindspore.set_context()中涉及编译能力的参数统一归纳到mindspore.jit()接口,同时对jit函数的参数进行重新设计,根据编译过程的关键特点提供对应参数给开发者控制,例如capture_mode(捕获代码方式)/jit_level(编译优化级别)/dynamic(是否动态shape)/backend(编译运行后端)参数,提升可理解性。
昇思MindSpore默认动态图模式,优先保证开发调试易用性,性能加速可对局部函数进行jit编译装饰。
参考链接:https://www.mindspore.cn/docs/zh-CN/master/api_python/mindspore/mindspore.jit.html
9 msprobe工具支持动态图训练状态监控,实时呈现训练状态,提高精度调优效率
针对大模型训练业务中异常的更新可能导致模型训练过程中状态变化剧烈且定位困难的问题,msprobe工具新增支持昇思MindSpore动态图场景训练状态监控,能够在较低性能损耗下收集和记录模型训练过程中的激活值、权重梯度、优化器状态和通信算子的中间值,实时呈现训练状态,快速分析精度问题。可根据需求监控相应对象,比如在loss上扬但grad norm正常的异常训练过程中,监控模型前向过程;在grad norm异常的训练过程中,监控权重和激活值的梯度。
可通过配置实现对整网训练中激活值的输入输出进行数据监控及落盘,作为人工分析模型训练精度的输入,帮助用户提高精度调优效率。
参考链接:https://gitee.com/ascend/mstt/blob/master/debug/accuracy_tools/msprobe/docs/19.monitor.md