昇思MindSpore 2.9版本正式发布,独创无图融合技术,绑核能力全面升级,提升训练稳定性与效率
昇思MindSpore 2.9版本正式发布,独创无图融合技术,绑核能力全面升级,提升训练稳定性与效率
经过昇思MindSpore开源社区开发者们几个月的开发与贡献,现正式发布昇思MindSpore2.9版本。 在基础框架演进方面,独创无图融合技术,支持动态图原生自动算子融合优化,实现网络模型性能收益,使能Triton Ascend算子,降低自定义算子开发门槛,并新增算子调度拦截机制,支持自定义控制算子执行,同时支持进程级、线程级与NUMA级绑核,提升大规模训练稳定性与Host侧执行效率。 在科学计算套件方面,发布MindSpore Science科研智能体系统,覆盖端到端科研全流程,大幅压缩科研周期。 下面就为大家详细解读昇思2.9版本的关键特性。
——基础框架持续演进——
1 独创无图融合技术,实现动态图原生自动算子融合优化
在业界主流AI框架中,自动算子融合一直是一个非常重要的性能优化手段,然而当前主流自动算子融合方案都依赖构建静态计算图进行融合,这种方式既限制了自动算子融合的可用范围,同时也为实现高性能模型代码增加额外的不必要约束。 为了解决该问题,昇思MindSpore独创实时无图融合技术并在2.9版本正式落地,实现对用户Python原生动态图模型进行自动实时算子融合优化,对用户模型零修改、零适配。 设置如下环境变量即可使能: export MS_DEV_PYNATIVE_FUSION_FLAGS="--opt_level=1 -- enable_ops=Dense,MatMul,BatchMatMul,BatchMatMulExt,MatMulExt" 无图融合技术基于昇思MindSpore社区已经孵化两年多的DVM实时算子编译和执行框架进行构建。主要技术原理是在动态图算子下发过程中自动识别可融合算子并加入待融合缓存池,当遇到不可融合算子、值依赖等调用时,对缓存池中的算子基于DVM进行实时融合和下发执行。通过无图融合,可实现网络模型平均约5%~15%的性能收益。
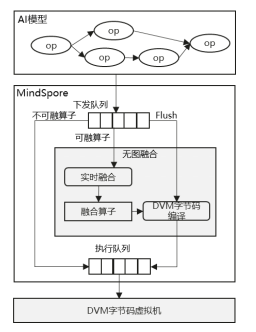
为了支持用户更好使用包括该特性在内的所有DVM融合能力,并繁荣社区生态,已同步对DVM代码进行了开源。 开源地址:https://gitcode.com/mindspore/dvm
2 使能Triton Ascend算子,降低自定义算子开发门槛
随着人工智能模型规模的持续扩大与架构创新的加速演进,对底层算子执行效率与开发灵活性的要求日益提升。传统自定义算子开发通常依赖 C++/ACL 等底层接口,存在开发周期长、调试复杂、跨平台迁移成本高等挑战。 Triton作为一种基于Python的领域特定语言(DSL),通过声明式编程模型与自动优化机制,显著降低了高性能GPU/NPU算子的开发门槛。triton-ascend项目在此基础上,进一步扩展了Triton对昇腾NPU架构的支持,并实现了与昇思MindSpore框架的无缝集成。这一改进带来了三大核心价值:
- 极简接入:用户无需了解昇思MindSpore内部的算子注册机制(如Custom原语),直接使用Python语法编写Triton内核并调用即可。
- 无缝对接:Triton算子可直接融入昇思MindSpore的计算图,支持自动微分与反向传播,可像内置算子一样参与模型训练。
- 生态兼容:高度兼容社区Triton算子代码资产,移植成本极低。 参考链接:https://gitcode.com/Ascend/triton-ascend
3 新增算子调度拦截机制,支持自定义控制算子执行
在实际开发中用户经常会有这样的需求:想知道某段代码执行了哪些算子、想在算子执行前后做一些自定义处理、或者希望自定义的Tensor子类能够控制算子的执行方式。此前,这些需求往往需要修改框架内部代码才能实现,而昇思MindSpore2.9版本新增算子调度拦截机制,提供了两种互补的方式——Tensor子类调度和Guard上下文管理器,让用户在不侵入框架源码的前提下,灵活地控制算子的执行行为。
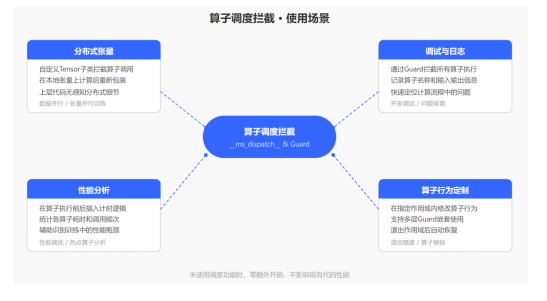
3.1 自定义张量子类调度
新增__ms_dispatch__协议,用户可以创建Tensor的子类并实现该类方法,用于拦截作用在该子类实例上的算子调用。当框架检测到算子的输入中包含带有__ms_dispatch__ 的张量子类时,会将执行流转交给用户定义的调度方法,由用户决定如何处理这次算子调用。 一个典型的应用场景是分布式训练中的DTensor。DTensor内部持有一个本地张量,当算子作用在DTensor上时,__ms_dispatch__将算子调用拦截下来,提取出本地张量完成实际计算,再将结果重新包装为DTensor返回。这样上层业务代码可以像使用普通Tensor一样使用DTensor,分布式的细节被封装在调度逻辑中。
3.2 MsDispatchGuard 上下文管理器
另一种拦截方式是MsDispatchGuard,与Tensor子类调度针对特定张量类型不同,Guard作用于一个代码范围——在其上下文内执行的所有算子都会被拦截。用户继承MsDispatchGuard并重写__ms_dispatch__方法,即可在算子执行前后插入自定义逻辑。Guard的常见用途包括:记录算子调用日志辅助调试、在算子前后插入计时代码做性能分析、或在特定范围内替换算子的执行行为,Guard同时支持作为上下文管理器和装饰器两种使用方式。 Guard支持嵌套使用,多个Guard按栈的方式管理,内层Guard优先执行。当用户在 ms_dispatch 中调用 func(*args) 时,框架会自动将执行流传递给栈中的下一个Guard,直到所有Guard都处理完毕后才执行原始算子逻辑。退出Guard作用域后,拦截行为自动恢复到外层的状态。该机制在前向和反向传播中均可正常工作,与昇思MindSpore的自动微分系统兼容,反向传播中的中间算子同样会经过Guard链处理。Tensor子类调度和Guard调度可以独立使用,也可以组合使用。当两者同时存在时,Guard的优先级更高——如果Guard栈非空,会优先走Guard链路径;Guard栈为空时,才检查Tensor级别的__ms_dispatch__。在都不使用的情况下,算子执行走原有路径,不产生任何额外开销。
4 支持进程级、线程级与NUMA级绑核,提升大规模训练稳定性与Host侧执行效率
随着大模型规模持续扩大,Host侧逐渐成为整机效率瓶颈;在多卡分布式场景中,训练进程、关键线程和内存访问如果完全依赖系统自由调度,容易带来CPU争抢、线程迁移和跨NUMA访存,影响Device侧供给稳定性。围绕这一问题,昇思MindSpore持续演进绑核能力,在昇思MindSpore 2.9版本中提供了从进程级绑核、线程级绑核到NUMA内存绑定,再到统一JSON配置的完整能力体系,不仅帮助关键线程获得更稳定、更低干扰的CPU运行环境,也让复杂部署场景下的配置和复用方式更加清晰,进一步提升大规模训练任务的稳定性与整机效率。
4.1 进程级绑核
昇思MindSpore首先提供了基于msrun的进程级绑核能力。该能力在分布式任务启动阶段尽早完成CPU范围划定,让不同训练进程拥有相对独立、稳定的CPU运行空间,减少进程之间的核心重叠、资源争抢和调度抖动。由于绑核动作发生在任务启动最前期,后续线程创建和调度继承也会更加稳定,为大规模分布式训练打下基础。
4.2 线程级绑核
在进程级绑核基础上,昇思MindSpore进一步提供线程级CPU亲和能力,通过mindspore.runtime.set_cpu_affinity对关键工作线程执行更细粒度绑定。重点覆盖的线程包括main、runtime、pynative 和 minddata,分别承担编译与流程控制、静态图下发、动态图算子下发和数据处理等职责。
这一能力的核心价值在于,不再平均对待所有线程,而是优先保证关键线程的CPU稳定性,减少线程迁移和普通线程干扰,使Host侧关键路径更加平稳,进而减少Device侧因等待 Host 供给而产生的空闲。
4.3 内存绑定
当服务器进入多路CPU和NUMA架构时代,仅仅把线程绑到某些CPU核心上已经不够。因为在NUMA架构中,线程如果频繁访问远端NUMA节点上的内存,依然会引入额外的访存时延和带宽损耗。 因此,昇思MindSpore将绑核能力进一步扩展到NUMA级别,关注的不只是“线程跑在哪个核上”,还包括“相关内存操作是否尽量在本地NUMA节点完成”。这使得该能力从CPU亲和优化进一步演进为CPU与内存协同优化,能够更系统地降低复杂服务器拓扑下的远端访存开销,尤其适用于大规模训练、数据处理和HyperOffload等场景。
4.4 JSON易用性提升
随着绑核能力从进程级扩展到线程级,再延伸到NUMA内存绑定,配置维度不断增加。如果这些能力长期分散在不同参数、接口和零散配置中,将显著增加用户理解和使用成本。 为此,昇思MindSpore提供了基于JSON的统一配置方式,将CPU/NUMA亲和关系整合为更清晰、更适合工程落地的配置入口。用户可以通过JSON描述复杂线程与资源映射关系,并将其纳入部署流程、环境复现和版本管理体系中,提升复杂场景下的可维护性和复用效率。
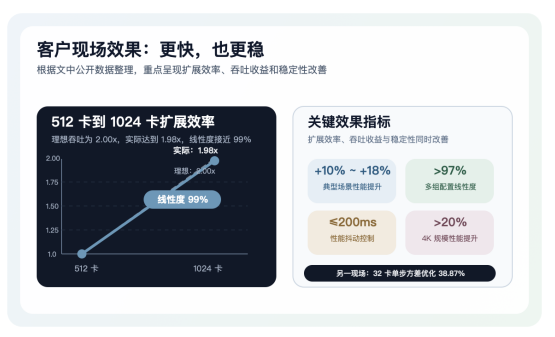
从实际效果来看,整套昇思MindSpore绑核方案已经在客户现场得到验证。在某万亿级MoE模型上,512卡扩展到1024卡时线性度达到99%,512卡场景平均性能提升约10%,1024卡场景平均性能提升约18%;在另一组256卡到1024卡配置中,线性度均超过97%,整体性能提升10%至15%,性能抖动控制在200ms以内; 在真实生产模型场景中,4K规模下性能提升超过20%,另一客户现场32卡场景单步耗时方差优化达到38.87%。这说明昇思MindSpore绑核能力不仅提升性能,也显著改善了运行稳定性。 参考链接: https://www.mindspore.cn/tutorials/zh-CN/master/parallel/msrun_launcher.html#%E8%BF%9B%E7%A8%8B%E7%BA%A7-cpunuma-%E4%BA%B2%E5%92%8C%E6%80%A7%E9%85%8D%E7%BD%AE
——科学计算套件增强——
5 MindSpore Science科研智能体系统版本发布,覆盖端到端科研全流程
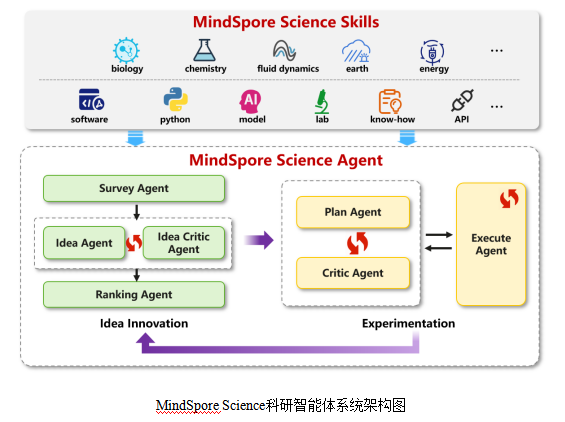
科研周期涉及文献阅读、假设提出、代码编写、实验试错和调优等阶段,过程繁琐,耗时冗长。昇思科学计算构建MindSpore Science科研智能体系统,通过将科学全流程Agent化,消除了科研环节之间的“人工衔接成本”,大幅压缩科研周期。 MindSpore Science科研智能体系统包含MindSpore Science Skills和MindSpore Science Agent 两大核心组件:
- MindSpore Science Skills是一个为通用科学研究全流程打造的开源智能体技能库,覆盖科研流程“分析-仿真-实验”流程中的常用技能。
- MindSpore Science Agent是一个面向科研全流程的开源科学智能体,支持假设生成、实验设计、自我修改、实验执行等sub-agent,并支持用户快速构建自己的AI科研助手。 本次发布MindSpore Science Skills 0.1版本与MindSpore Science Agent preview版本。
5.1 MindSpore Science Skills 0.1版本
MindSpore Science Skills 0.1内置了300+专业科研技能,覆盖了生物医药、化学材料、流体、PDE方程、地球科学、电磁等核心科学领域:
- 接入 VASP、OpenFOAM等配置复杂的工业级HPC软件及FitDock等SOTA工具。内置输入构建、参数调整、计算结果分析等流程,构建20+人人可用的复杂领域软件skills,提升Agent软件调用成功率;
- 覆盖生物、化学、流体、气象、能源等领域40+昇思、昇腾AI4S顶尖模型,极大扩展Agent知识边界;并支持用户分钟级将自有模型封装为智能体skill,将AI4S模型快速转换为即插即用的生产力工具;
- 打通干湿实验界限,提供湿实验设备操作skill(e.g.,电催化场景湿实验设备skill),为湿实验的设计和执行提供参考实现,缩短实验迭代周期,实现真正的闭环科研;
- 联合中科大等顶尖实验室沉淀化学、生物等领域“隐性知识”(e.g.,掺杂材料第一性原理计算skill),将复杂的长链路科研任务固化为Know-How类skill,提升Agent解决复杂科研任务效率。
- 集成业界常用文献、数据搜索API以及领域专用Python数据分析与处理工具库; 上述skills已覆盖科学分析、仿真与实验场景中的基础需求,降低智能体跨学科调用的技术门槛。MindSpore Science Skills可以与Hermes Agent、OpenClaw、Claude Code、JiuwenClaw等智能体无缝集成,也支持直接接入用户专属的AI科研助手中。 参考链接:https://gitcode.com/mindspore-lab/mindscience/tree/master/MindScienceSkills
5.2 MindSpore Science Agent preview版本
MindSpore Science Agent preview版本内置6个sub-agent与科学实验workflow,并提供了化学领域的科研案例。MindSpore Science Agent preview主要特性:
- 集成业界开源假设生成、实验设计、实验执行等sub-agent,并基于多智能体架构,实现科学实验全流程workflow编排;
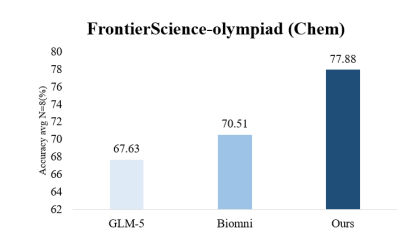
- 重点优化实验相关sub-agent的prompt与skills,提升实验执行sub-agent自我纠错能力,减少报错信息带来的上下文污染; MindSpore Science Agent在Frontier Science化学测试集准确率为77.88%,超越斯坦福大学研究团队发布的Biomni平台(70.51%),并在湿实验与计算仿真两大科研路径上均完成了案例验证:如OER催化剂高通量合成与测试的完整电催化湿实验流程,以及以钙钛矿掺杂结构优化为代表的高精度计算仿真任务。
参考链接:https://gitcode.com/mindspore-lab/mindscience/tree/master/MindScienceAgent
本次发布的化学、生物等领域专业技能库等特性,与中国科学技术大学江俊教授团队、四川大学曹洋教授团队联合构建,昇思、昇腾模型类skills集成了诸多合作团队的原创成果和生态贡献,感谢所有共创团队在专业领域的深度指导与合作。