昇思MindSpore 2.2,提升大模型编译效率,支持更多热门预训练大模型
昇思MindSpore 2.2,提升大模型编译效率,支持更多热门预训练大模型
经过昇思社区开发者们2个月的辛勤耕耘,现正式发布昇思MindSpore2.2版本,持续提升大模型相关能力,包含提供Lazy inline模式提高大模型编译效率、大模型开发套件MindSpore Transformers支持20+热门预训练大模型和52+典型规格开箱即用,同时在生成式领域发布套件MindSpore One集成易用接口和前沿算法模型,在科学智能领域发布AI4Science高频模型套件MindSpore SciAI和地球科学套件MindSpore Earth,提供高效易用的AI4Science通用计算平台以及更多应用场景,下面就带大家详细了解下2.2版本的关键特性。
1. Lazy inline:显著提升大模型静态图编译效率
在神经网络模型(特别是LLM)的流水线并行场景下,对于被重复多次调用的计算单元,传统编译过程会将层级的代码表达inline成一张扁平图,Lazy inline模式则不执行inline或只在执行前的最后阶段inline,从而显著降低了图的规模,实现了编译性能倍数级的提升。我们通过盘古13B网络对Lazy inline的编译效率提升效果进行了验证:计算图编译节点从13万+下降到2万+,编译时间从3小时下降到20分钟,效率提升900%+。
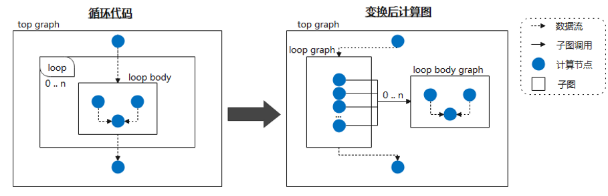
子图 loop body graph 仅有一份,使用Lazy inline方式多次调用子图
2. MindSpore Transformers:20+热门预训练大模型支持,52+典型规格开箱即用
MindSpore Transformers的目标是构建一个大模型生命周期内,训练、微调、评估、推理、部署的全流程的开发套件,覆盖CV、NLP、AIGC等热门领域,提供快速开发能力,支持20+ 热门预训练大模型、52+典型规格开箱即用,支持AICC计算中心大规模集群训练部署,支持昇思MindSpore多维存储优化和多维混合分布式并行特性配置化开发方式。
2.1 热门预训练模型支持
MindSpore Transformers新增了对LLama2、Baichuan2、GLM2、Internlm、Ziya、SAM、CodeGeex2以及BILIP2预训练模型的支持,详细的支持列表如下:
模型
规格
支持模式
glm2_6b glm2_6b_lora
预训练、微调、评测、推理/MSLite推理
llama2_7b llama2_13b
预训练、微调、评测、推理/MSLite推理
baichuan2_7b baichuan2_13b
预训练、微调、评测、推理
codegeex2_6b
预训练、微调、推理
blip2_stage1_vit_g blip2_stage1_classification itt_blip2_stage2_vit_g_baichuan_7b itt_blip2_stage2_vit_g_llama_7b
预训练、微调、评测、推理
glm_6b glm_6b_lora
预训练、微调、评测、推理/MSLite推理
baichuan_7b baichuan_13b
预训练、微调、评测、推理
llama_7b llama_13b llama_7b_lora
预训练、微调、评测、推理/MSLite推理
bloom_560m bloom_7.1b bloom_65b bloom_176b
预训练、微调、评测、推理/MSLite推理
Internlm_7b Internlm_7b_lora
预训练、微调、评测、推理
ziya-13b
预训练、微调、评测、推理
gpt2 gpt2_lora gpt2_txtcls gpt2_xl gpt2_xl_lora gpt2_13b gpt2_52b
预训练、微调、评测、推理
pangualpha_2_6_b pangualpha_13b
预训练、微调、评测、推理
bert_base_uncased txtcls_bert_base_uncased txtcls_bert_base_uncased_mnli tokcls_bert_base_chinese tokcls_bert_base_chinese_cluener qa_bert_base_uncased qa_bert_base_chinese_uncased
预训练、微调、评测、推理
t5_small
预训练、微调、推理
mae_vit_base_p16
预训练、推理
vit_base_p16
预训练、微调、评测、推理
swin_base_p4w7
预训练、微调、评测、推理
clip_vit_b_32 clip_vit_b_16 clip_vit_l_14 clip_vit_l_14@336
微调、评测、推理
sam_vit_b sam_vit_l sam_vit_h
推理
2.2 Pipeline在线推理体验
此外MindSpore Transformers提供了便捷的pipeine推理接口,指定任务和模型规格,即可完成大模型推理。
import mindspore as ms
from mindformers import pipeline
ms.set_context(mode=0)
pipeline_task = pipeline(task='text_generation', model='glm2_6b',max_length=193)
pipeline_task("你好")
# [{'text_generation_text': [你好!我是人工智能助手ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。']}]
以上为单卡单batch推理,如果需要多batch/分布式并行/MSLite推理等操作,可参考教程GLM2官方推理教程
MindSpore Transformers还提供了便捷的在线LLM大模型聊天界面,用户可参考官方教程体验业界SOTA大模型聊天能力,支持多种参数调节、多种Prompt模版定义、流式推理展示等。
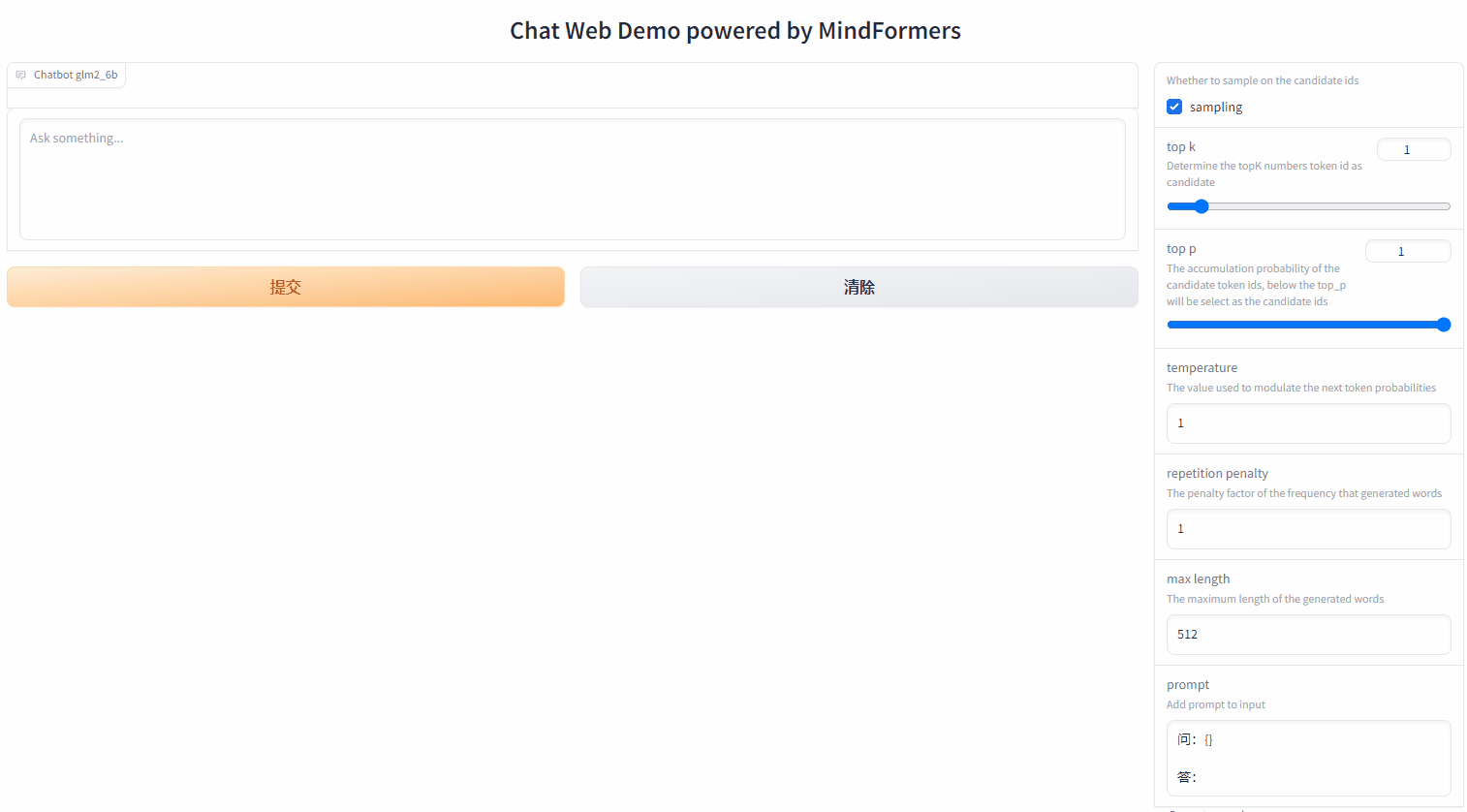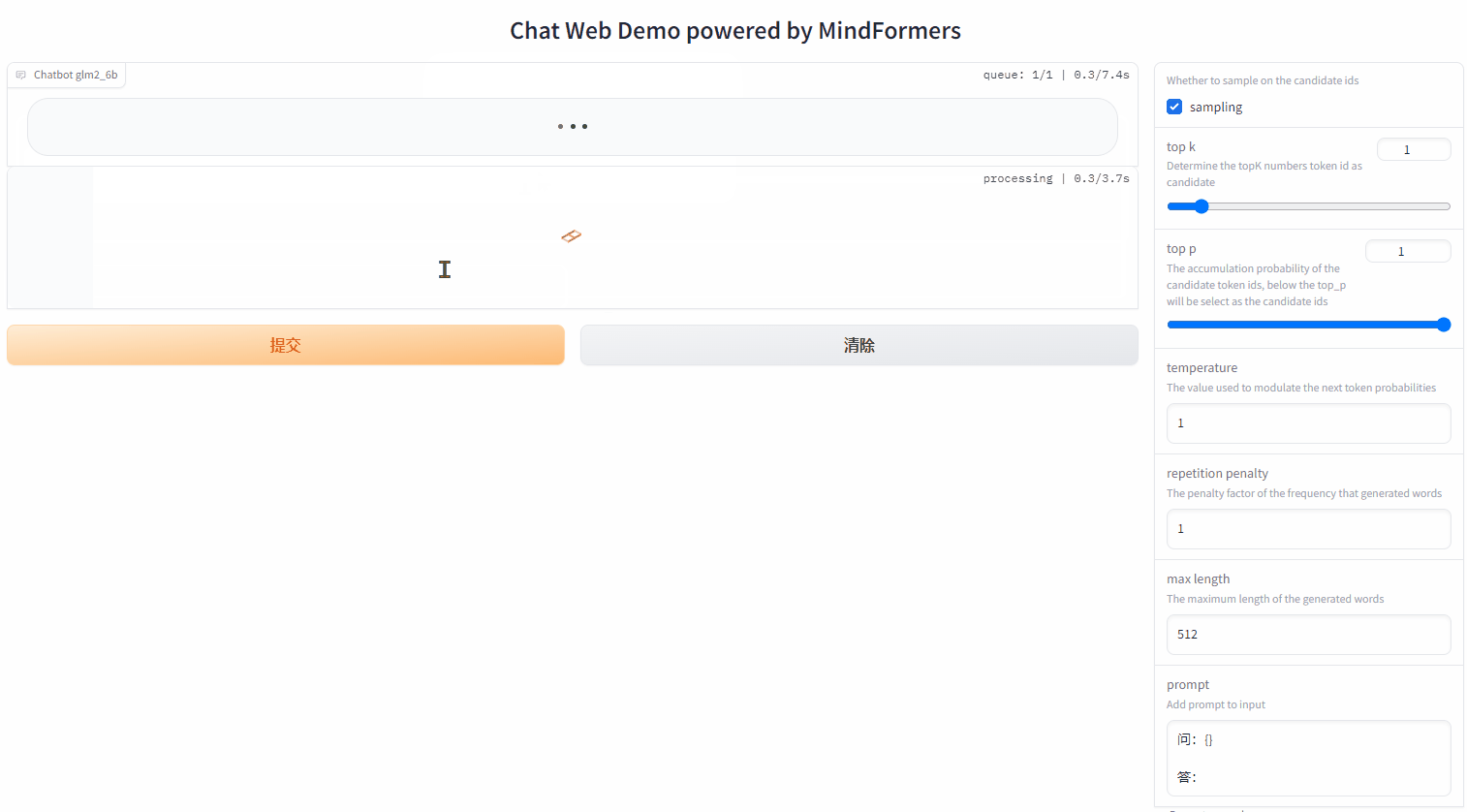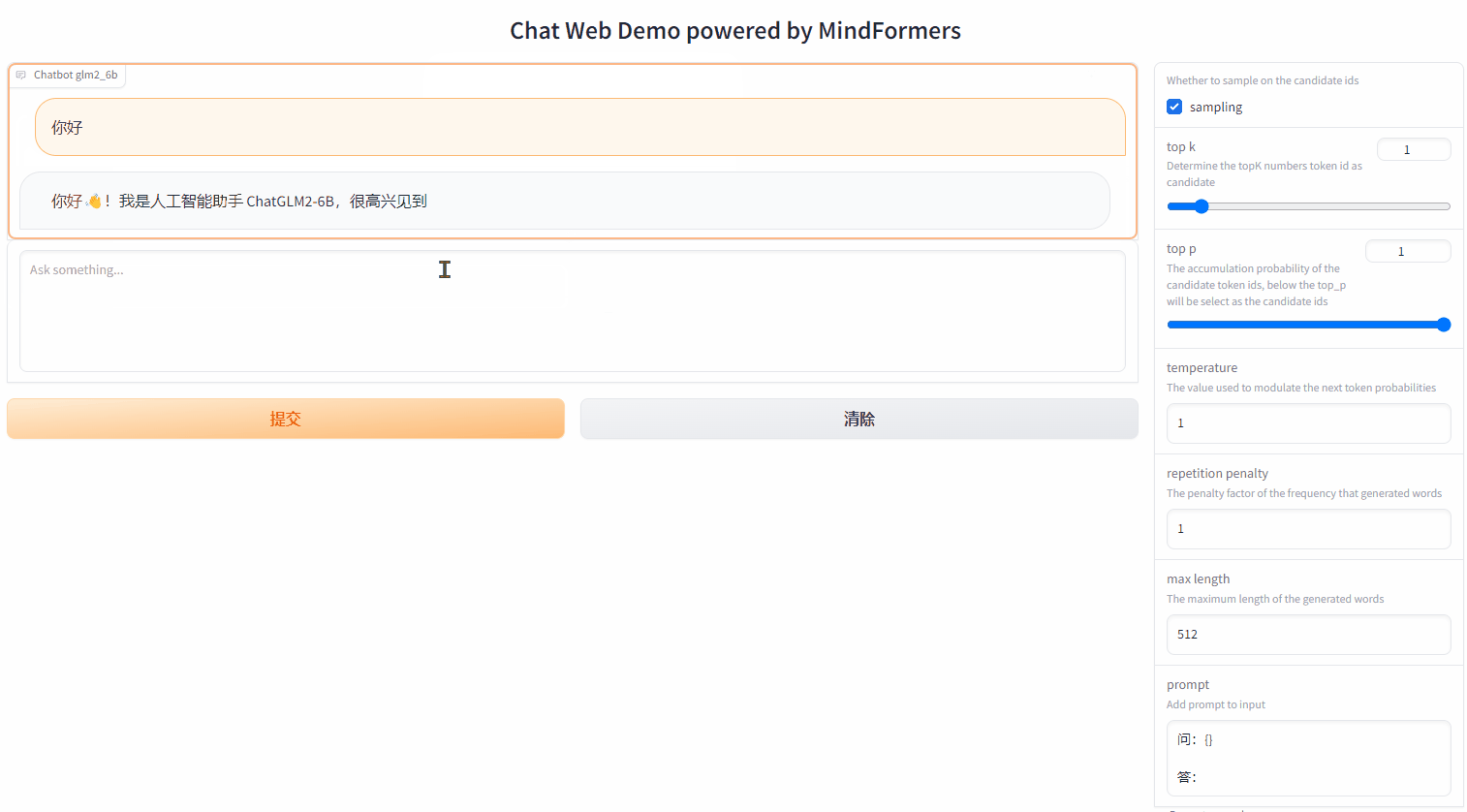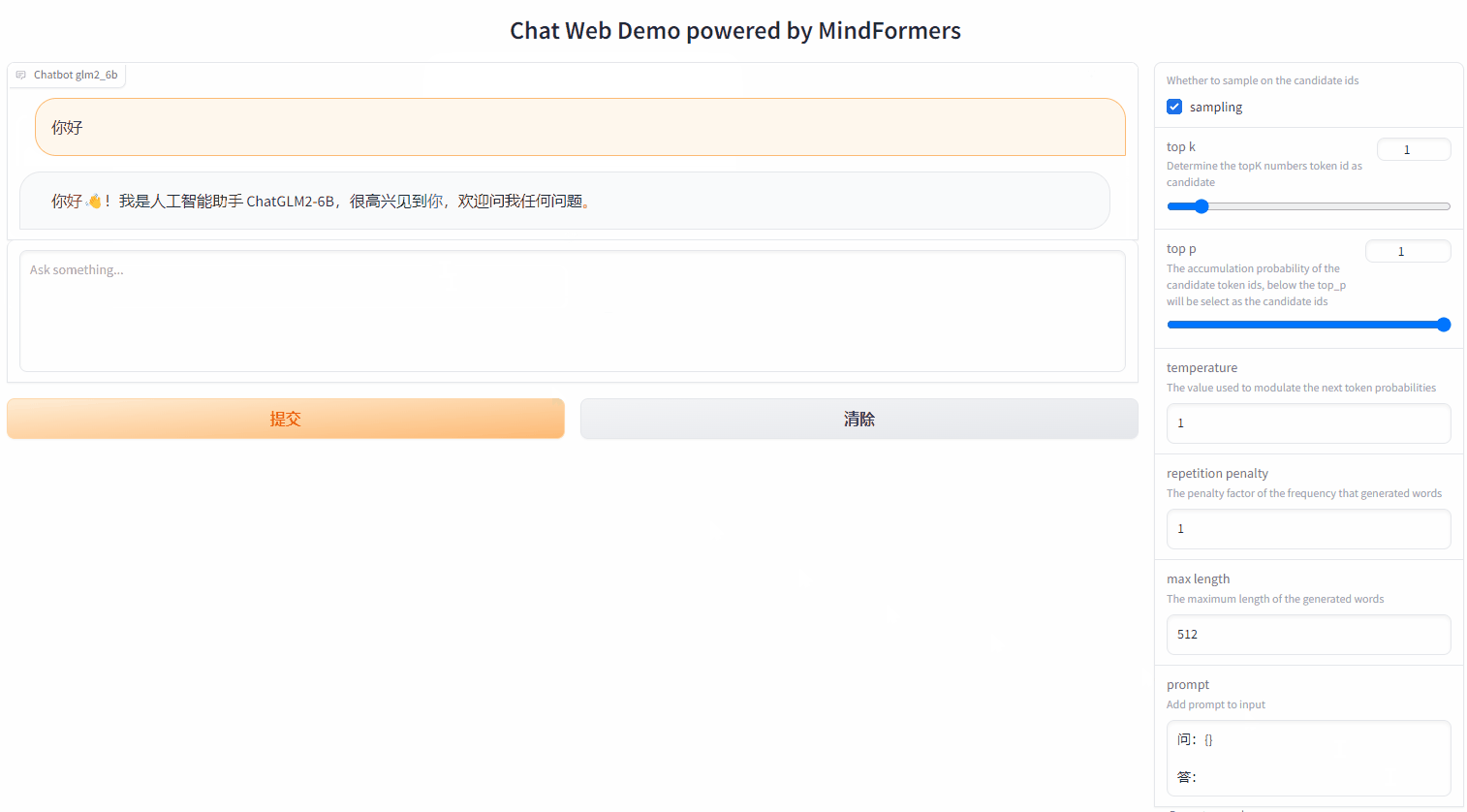
2.3 Trainer便捷任务调度
MindSpore Transformers提供Trainer高阶调度和开发接口,帮助用户轻松调度MindFormers已集成大模型或自定义开发的大模型,同时支持超参数自定义、边训练边评估、恢复训练、低参微调等特性。
from mindspore as ms
from mindspore.dataset import GeneratorDataset
from mindformers import Trainer, TrainingArguments
# 指定运行模式为图模式,运行设备为昇腾芯片
ms.set_context(mode=0, device_target="Ascend")
def train_data():
"""train dataset generator."""
seq_len = 128
input_ids = np.random.randint(low=0, high=15, size=(seq_len,)).astype(np.int32)
labels = np.random.randint(low=0, high=15, size=(seq_len,)).astype(np.int32)
train_data = (input_ids, labels)
for _ in range(32):
yield train_data
def eval_data():
"""eval dataset generator."""
seq_len = 127
input_ids = np.random.randint(low=0, high=15, size=(seq_len,)).astype(np.int32)
labels = np.random.randint(low=0, high=15, size=(seq_len,)).astype(np.int32)
eval_data = (input_ids, labels)
for _ in range(8):
yield eval_data
def main(run_mode="finetune", task='text_generation',model_type='glm2_6b',pet_method='lora'):
# 微调超参数定义
training_args = TrainingArguments(num_train_epochs=1, batch_size=2, learning_rate=0.001, warmup_steps=100,sink_mode=True, sink_size=2)
# 数据准备
train_dataset = GeneratorDataset(train_data, column_names=["input_ids", "labels"])
eval_dataset = GeneratorDataset(eval_data, column_names=["input_ids", "labels"])
train_dataset = train_dataset.batch(batch_size=2)
eval_dataset = eval_dataset.batch(batch_size=2)
# Trainer 任务便捷定义
task = Trainer(task=task,
model=model_type,
pet_method=pet_method,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset)
# 一键调度训练、微调、评估、推理
if run_mode == train:
task.train()
elif run_mode == finetune:
task.fintune()
elif run_mode == eval:
task.evaluate()
elif run_mode == predict:
predict_result = task.predict(input_data="你好")
print(predict_result)
#[{'text_generation_text': ['你好,我是 ChatGLM2-6B, 一个人工智能助手。我背后使用的模型是 GLM2-6B,是一种大型语言模型, 具有超过 2000亿参数,支持多种任务。']}]
if __name__=='__main__':
# 执行GLM2-6B大模型Lora低参微调,另外还可支持一键评估、推理
main(run_mode="finetune", task='text_generation',model_type='glm2_6b',pet_method='lora')
以上是Trainer单卡启动大模型的训练、微调、评估、推理流程,如果需要分布式并行运行,可参考GLM2官方教程进行使用。
2.4 AutoClass一键索引实例
MindSpore Transformers预置了多种SOTA大模型规格的Tokenizer、Processor、ModelConfig、ModelClass,使用提供的AutoClass接口的from_pretrained可以轻松完成API的实例化,并获取到对应的词表、权重等文件,帮助用户便捷自定义开发创新大模型。
from mindformers import AutoConfig, AutoModel, AutoTokenizer
# 获取GLM2-6B的Tokenizer
tokenizer = AutoTokenizer.from_pretrained('glm2_6b')
# 使用GLM2-6B的Tokenizer进行提词
inputs = tokenizer("你好")["input_ids"]
# 方式1:获取加载了GLM2-6B模型权重的模型实例,同时开启增量推理功能
model1 = AutoModel.from_pretrained('glm2_6b', use_past=True)
# 方式2:获取GLM2-6B的模型配置,同时开启增量推理功能
config = AutoConfig.from_pretrained('glm2_6b', use_past=True)
model2 = AutoModel.from_config(config)
# 使用generate生成推理结果,同时支持多种生成参数配置
outputs = model1.generate(inputs, max_new_tokens=20, do_sample=True, top_k=3)
response = tokenizer.decode(outputs)
print(response)
#['你好,作为一名人工智能助手,我欢迎您随时向我提问。']
更多功能和文档请参考:https://gitee.com/mindspore/mindformers
3. MindSpore One:生成式领域套件,集成易用接口和前沿算法模型,助力AI开发与创新
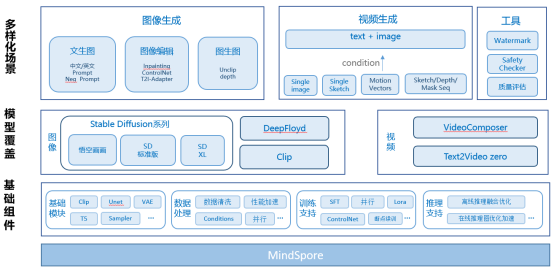
MindSpore One是基于昇思MindSpore的高质量生成式领域系列算法模型库,提供了简单易用的模块接口,内置了悟空画画/SD1.5/SD2.0/SDXL/VideoComposer等最新的图像视频生成模型,高效支持用户训推一体化部署,具有简单易用、高效微调、性能领先等特性。
1)简单易用:接口简洁,内置CLIP/OpenCLIP/VAE/UNet等基础模块及多种扩散模型,用户可以轻松地构建自己的数据处理流程和模型,开箱即用;
2)高效微调:支持LoRA、DreamBooth等个性化微调方法,适应不同领域的生成任务,帮助用户构建个性化生成模型;
3)性能领先:支持全场景推理,离线推理使用 MindSpore Lite,图像生成时间平均3秒。
详情参考:https://github.com/mindspore-lab/mindone
4. MindSpore SciAI 0.1版本:AI4Science高频模型套件,模型覆盖度全球第一
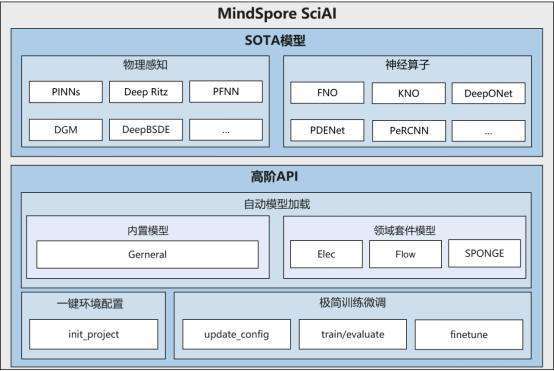
MindSpore SciAI是基于昇思MindSpore打造的AI4Science(科学智能)高频模型套件,内置了60+高频SOTA模型,覆盖物理感知(如PINNs、DeepRitz以及PFNN)和神经算子(如FNO、DeepONet、PDENet)等主流模型,覆盖度全球第一;提供了高阶API(一键环境配置、自动模型加载、极简训练微调等),开发者和用户开箱即用。 MindSpore SciAI为广大开发者和用户提供了高效、易用的AI4Science通用计算平台。MindSpore SciAI架构图如下:
4.1 物理感知模型:
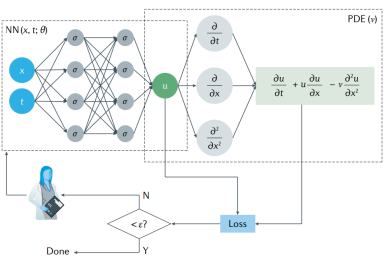
物理感知模型是指将物理学中的先验知识(如方程/初边界条件等)融入到神经网络中的一类模型,较为典型的有PINNs(如下述所示)、Deep Ritz以及PFNN等。该类模型的优势:无需生成离散网格;可基于AI框架的自动微分能力进行导数计算,避免数值微分离散误差;天然适用于反问题及数据同化问题;相比数据驱动具有更强的外插能力和更少的样本量。劣势:缺乏网络结构设计指引,奇异性问题学习困难;损失函数包含多项约束,训练难以收敛;物理约束变化时需要重新训练,缺乏泛化性;计算精度和收敛缺乏理论保证。
针对上述问题,学术界和昇思MindSpore提出了一系列改进方案,如自适应激活函数、时间&空间分解、多尺度优化以及自适应加权等。MindSpore SciAI内置了SOTA物理感知模型,应用领域也涵盖了流体、电磁、声、热、固体等众多领域。
4.2 神经算子
PINNs等物理感知模型主要求解特定方程,神经算子模型则能够学习无限维函数空间的映射,一次求解整个PDEs族。较为典型的有FNO(如下述所示)、DeepONet以及PDENet等。FNO主要利用傅里叶变换的性质,在傅里叶空间中学习函数之间的映射,然后再将结果转回至物理空间。DeepONet通过“branch net”和“trunk net”两个子网络学习函数之间的映射。神经算子模型在流体、气象、电磁等领域有较好的表现,MindSpore SciAI因此也内置了SOTA神经算子模型。
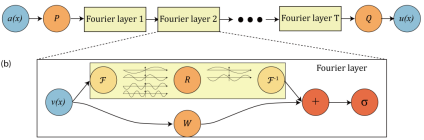
详情参考:https://gitee.com/mindspore/mindscience/tree/master/SciAI
5. MindSpore Earth 0.1版本:地球科学套件,涵盖中期天气预报、短临降水等多时空尺度预报场景
气象预报与人们的工作生活息息相关,也是AI4Science(科学智能)领域受到最广泛关注的应用场景之一。昇思MindSpore发布了MindSpore Earth地球科学套件0.1版本。该套件集成了多时空尺度下的AI气象预报SOTA模型,提供了数据前处理、预报可视化等工具,并集成了ERA5再分析、雷达回波、高分辨率DEM数据集,致力于高效使能AI+气象和海洋预报的融合研究。
MindSpore Earth架构规划如下图所示,涵盖气象预报短临降水、中期预报、超分辨率等多个场景的业界SOTA模型,包括GraphCast、ViT-KNO、FourCastNet、DGMR等,模型覆盖度业界领先,预报精度超越传统数值模式,预报速度较传统数值模式提升千倍以上。
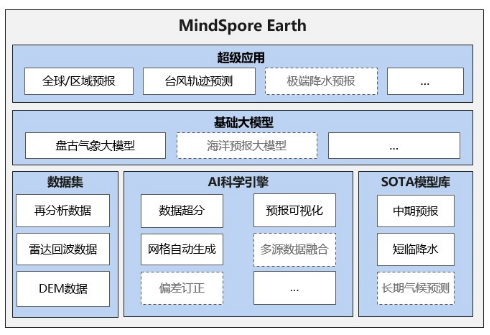
• 中期气象预报:MindSpore Earth提供了多个SOTA AI中期预报模型,包括FourCastNet、GraphCast以及华为先进计算与存储实验室与清华大学合作推出的ViT-KNO模型,可实现一周内气温、风速、湿度等要素秒级推理;
• 短临降水预报:MindSpore Earth提供了DGMR降水模型,基于MindSpore Earth+昇腾可以进行对降水强度与空间分布进行高效训练与推理。
• 数据前处理:昇思MindSpore团队、AI4Sci Lab与清华大学联合推出适用于全球区域的DEM超分模型,该模型在RMSE指标、清晰度、细节等方面均优于目前广泛采用的超分模型。
详情参考:https://gitee.com/mindspore/mindscience/tree/master/MindEarth
6. 支持BF16数据类型
BF16一种相对较新的浮点数格式,又叫BFloat16或Brain Float16,在通过降低少量精度的前提下,来获得更大的数值空间,提升性能、并减少内存的消耗。
昇思MindSpore2.2版本支持使用BF16数据类型训练网络,同时混合精度训练也支持配置BF16类型,达到自定义配置参数类型的效果。
注意:当前部分算子还不支持BF16类型,后续会逐步补齐算子能力,敬请期待!