MindSpore新版本v0.6.0-beta解读
MindSpore新版本v0.6.0-beta解读
大家好,又到了MindSpore每月更新跟大家见面的时间,这次发布新版本的是v0.6.0-beta(后简称v0.6)版本。
Follow小编的版本解读来品品,经过一个月的开发后,MindSpore又有了什么新的关键特性呢。、

老规矩先上视频,看视频发现MindSporev0.6版本新特性
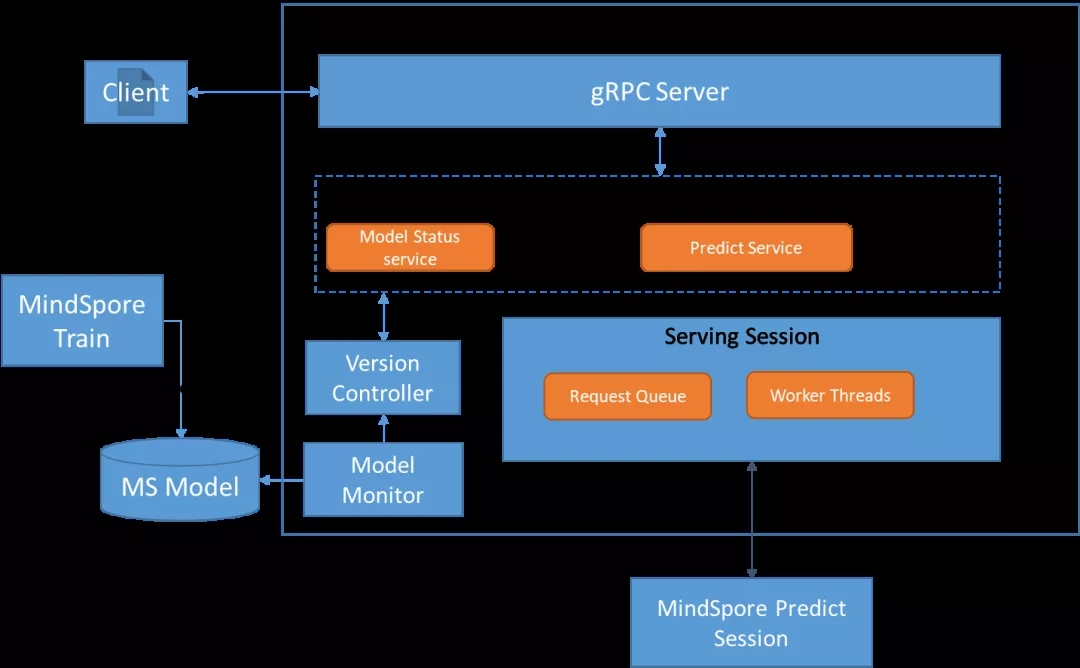
MindSpore Serving
- 训练完成后无缝对接推理服务
- 支持推理模型的预加载,获得更佳性能的推理服务
官网教程:
https://www.mindspore.cn/tutorial/zh-CN/r0.6/advanced_use/serving.html
PS分布式训练
分布式训练作为MindSpore最受瞩目的特性之一,MindSpore团队在v0.6版本里又添加了新的内容——PS分布式训练。
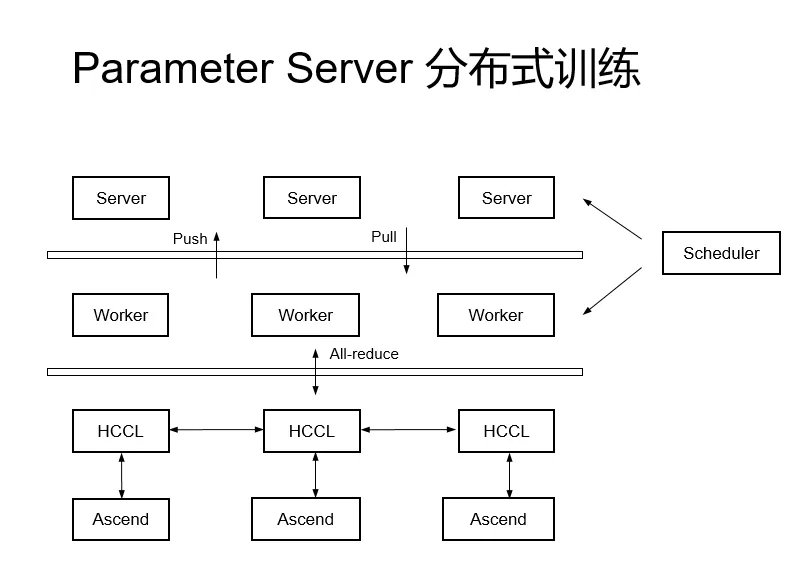
Parameter Server(参数服务器)是分布式训练中一种广泛使用的架构,既支持同步SGD,也支持异步SGD的训练算法。在扩展性上,将模型的计算与模型的更新分别部署在Worker和Server两类进程中,使得Worker和Server的资源可以独立地横向扩缩。
另外,在大规模数据中心的环境下,计算设备、网络以及存储经常会出现各种故障而导致部分节点异常,而在参数服务器的架构下,能够较为容易地处理此类的故障而不会对训练中的任务产生影响。
在MindSpore的参数服务器一共包含三个独立的组件,分别是Server、Worker和Scheduler,作用分别是:
- Server:保存模型的权重和反向计算的梯度值,并使用优化器通过Worker上传的梯度值对模型进行更新(当前版本仅支持单Server);
- Worker:执行网络的正反向计算,正向计算的梯度值通过Push接口上传至Server中,通过Pull接口把Server更新好的模型下载到Worker本地;
- Scheduler:用于建立Server和Worker的通信关系;
- 相较于同步的AllReduce训练方法,Parameter Server具备着很好的灵活性、可扩展性以及节点容灾的能力。
官网教程:
https://www.mindspore.cn/tutorial/zh-CN/r0.6/advanced_use/parameter_server_training.html
超大规模稀疏特征训练
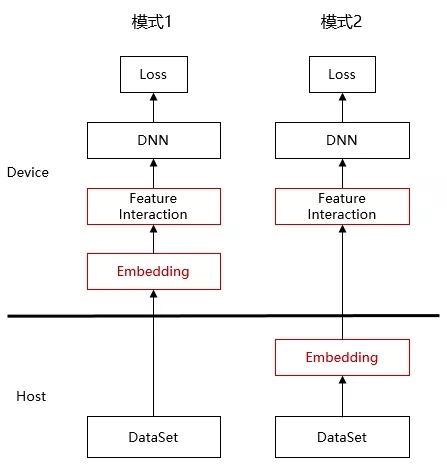
像wide&Deep的推荐网络,根据场景不同特征数量可能是千万到百亿的规模,Embedding参数量是GB级到TB级。这么大的参数量,远远超过了设备内存容量,无法直接在设备卡上进行训练。
为此,MindSpore在全下沉模式(所有计算都在Device上)之外,提供了Host-Device混合执行模式,即Embedding部署在host测,DNN和通信下沉到Device侧,来解决embedding容量的问题,发挥昇腾芯片算力;并在此基础上实现了混合并行(Embedding模型并行,DNN数据并行)实现超大规模Embedding的高性能训练。
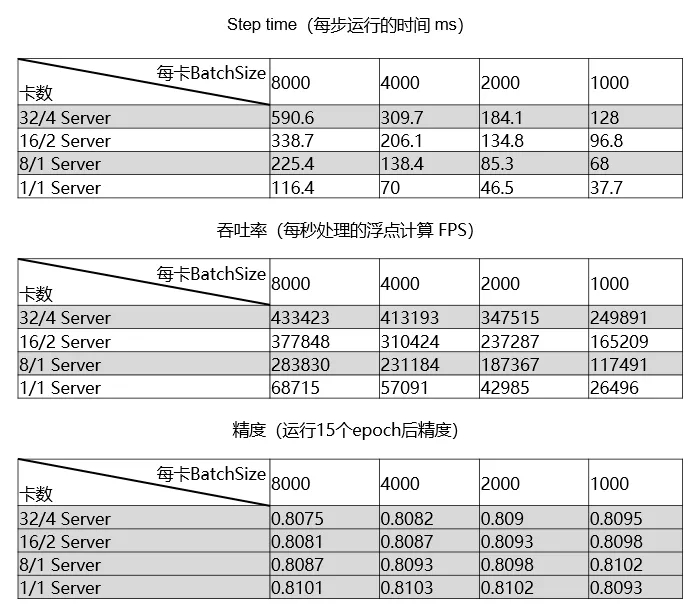
对于第二种模式,目前可以支持500GB的模型,使用creteo数据集训练的性能和精度测试结果如下表:
总结
以上就是MindSpore v0.6版本关键特性。当然新版本还有不少特性,详细的特性,可以参考下方RELEASE.md文档:
https://gitee.com/mindspore/mindspore/blob/r0.6/RELEASE.md
MindSpore保持持续的更新完善,未来会有更多实用的特性发布,非常欢迎大家下载并体验MindSpore,参与到MindSpore开源社区建设中来。
官方网站:
Gitee:
https://gitee.com/mindspore/mindspore
GitHub:
https://github.com/mindspore-ai

接下来隆重介绍即将和大家见面的
第三期MindSpore 两日集训营
集训时间为:8月8日-8月9日两天
报名从今天(7月31日)开始
长按下方图片添加小助手微信
*备注:集训
即可报名

MindSpore官方资料
GitHub:https://github.com/mindspore-ai/mindspore
Gitee:https://gitee.com/mindspore/mindspore
官方QQ群: 871543426
