昇思MindSpore 1.9,不断提升易用性和效率!
昇思MindSpore 1.9,不断提升易用性和效率!
经过社区开发者们1个多月来的不断努力,昇思MindSpore1.9版本现已发布。在此版本中,我们提供了函数式+面向对象融合编程能力,不断提升易用性,发布了高效的分布式表格数据分析框架—MindPandas,同时提供AI大规模训练性能可视化模块,提升并行训练性能分析效率,下面就带大家详细了解下1.9版本的关键特性。
1 函数式+面向对象融合编程,降低上手难度,提升易用性
昇思MindSpore1.9版本采用了融合编程的形式,结合函数式和面向对象编程范式的优势,既可以保留面向对象编程的易用性和较低的学习成本,又可以引入函数式编程的数学表达优势,同时避免纯函数式编程陡峭的学习曲线。在框架设计上将AI与科学计算视作同等重要,而不是采用核心框架+二次开发库的形态。
整个训练流程优化如下:
1. 网络构造:满足面向对象编程习惯,昇思MindSpore提供与PyTorch完全一致的Layer构造方式,两者使用方法几乎完全相同。
2. 前向计算和反向传播:使用函数式自动微分,更符合数学语义。将前向计算构造成function,然后通过函数变换获得grad function,最后通过执行grad function获得权重对应的梯度。
3. 保留纯函数式编程的支持,可以像Jax一样构造科学计算算法。
优化后与优化前用户脚本对比如下图所示:
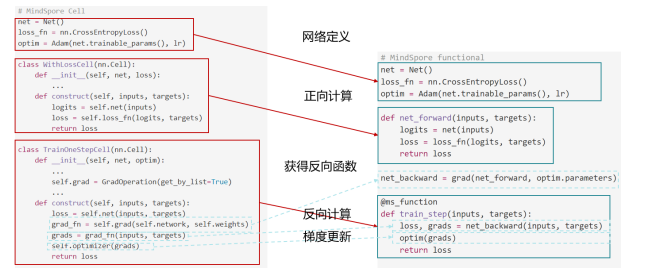
图 优化前后脚本对比图
优化后流程省略了基于框架代码的二次开发,且更加符合数学语义,在使代码更加简洁易懂的同时,提高了框架易用性,降低了上手难度。
参考文档:https://www.mindspore.cn/tutorials/zh-CN/master/beginner/quick_start.html
2 MindPandas,高效的分布式表格数据分析框架
数据处理及分析是深度学习流程中很重要的一环,其中表格数据类型是常用的数据表示形式。当前业界主流的数据分析框架Pandas提供了易用、丰富的接口,但由于其单线程的运行方式,导致在处理大数据量时性能较差,同时因为内存限制导致其无法处理大于本机内存的数据量,因此在实际应用中,针对不同的数据量,数据分析人员往往会在不同框架间切换,由此带来多语言学习及多框架管理的成本。同时由于数据分析框架与昇思MindSpore等AI框架是割裂的,数据需要落盘、格式转换等,极大影响了效率。
MindPandas是一款兼容Pandas接口,同时提供分布式处理能力的数据分析平台,致力于提供高性能、大数据量的处理能力,又能与训练无缝结合,使得昇思MindSpore支持完整AI模型训练全流程的能力。
2.1 易用的数据处理接口
MindPandas API兼容Pandas接口,用户存量脚本只需要修改少量代码即可切换到MindPandas,如下图所示:

当前MindPandas已支持分布式的DataFrame、Series等接口100+,更多接口正在持续补充,敬请期待!
2.2 高效的分布式数据处理能力
MindPandas通过将表格数据切分,实现了不同切片数据的并行计算,以充分发挥多核的CPU算力,从而实现计算性能的倍数提升;切分细节用户无需感知,简化了用户的使用。下图以DataFrame.sum接口为例,描述了该接口并行计算的过程。
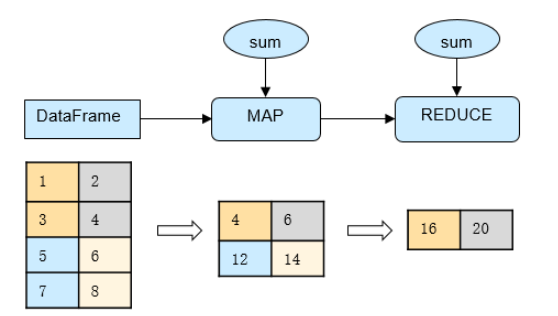
图 sum接口并行计算流程图
当处理的数据量较大,超过单机内存时,MindPandas提供了易扩展的多机分布式能力,利用多机的共享内存,解决了Pandas无法处理大数据的限制。同时,MindPandas支持一次开发,同时支持单机&分布式运行,降低了用户的使用成本。
2.3 统一、高效的数据流转
MindPandas的计算结果无需落盘,通过共享内存,即可将数据以统一的格式直接提供给MindSpore进行训练。用户无需关心具体的数据格式,真正打通了数据分析与训练的通路,解决了数据分析框架与训练框架割裂的痛点。该功能将在近期开放,敬请期待!
2.4 性能对比
基于Linux Ubuntu 56核,4G数据量下,默认切片数(用户可通过set_partition_shape调整),部分API性能与Pandas对比效果如下图所示,性能提高10倍以上!
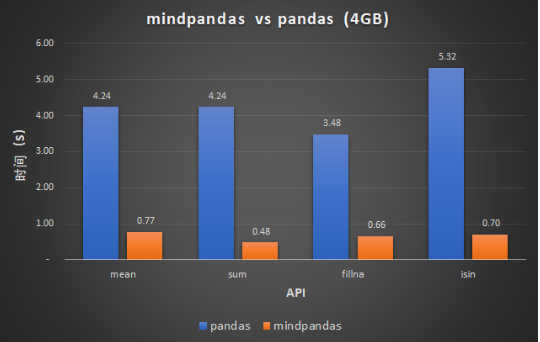
图 API性能对比图
如下图所示,随着数据量的增加,性能优势体现的更加明显。
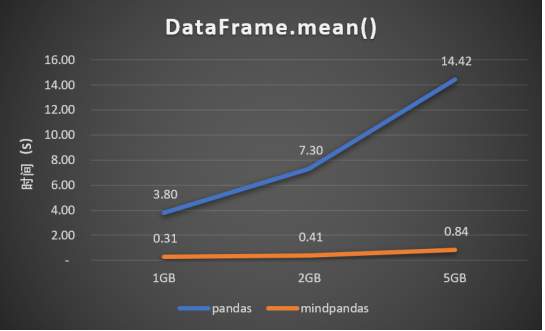
图 不同数据量下API性能趋势对比图
以上结果均在默认并发数下测试,用户可根据实际环境设置并发数,可获得更高性能优势。
仓库地址:https://gitee.com/mindspore/mindpandas
3 AI大规模训练性能可视化模块,提升并行训练性能分析效率
随着神经网络模型参数量和数据集规模的指数级增长,训练所需要的集群规模越来越大。其中多设备的并行策略选择和组合多样,性能瓶颈及其根因复杂。昇思MindSpore和浙江大学可视分析与智能小组陈为教授团队合作研发,推出AI大规模训练性能可视化模块,帮助提升集群并行训练的性能分析效率。
具体使用方法请参考:https://www.mindspore.cn/mindinsight/docs/zh-CN/master/performance_profiling_of_cluster.html
3.1 并行训练策略分析:
1.9版本中,我们提出了计算-通信二部图方案。计算图中所有的通信算子被抽出至画布顶层。计算图中同时展示了并行策略信息。用户能够清晰地观察并行策略相关算子及计算图的执行序,从而确认通信算子存在的合理性。如下图所示,清晰地展示了使用K级集群并行训练的盘古模型,其中绿色底色代表重排布算子,不同分支的计算-通信节点展现了相应的并行策略。
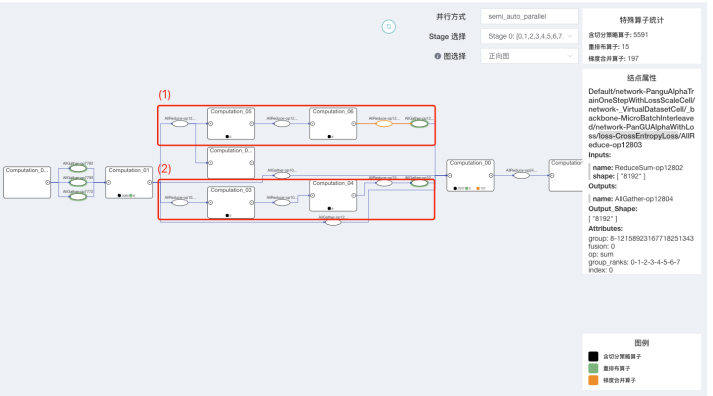
图 盘古模型并行训练策略分析示例
如下图所示,展开命名空间结点,结合策略矩阵,我们可以看到具体算子的切分策略。结合结点属性面板,我们发现Load-op2输入的张量(参数)没有做切分,StridedSlice-op10856输入的张量(数据)第一维切分了两份。盘古模型混合并行解析一文中指出,在词表范围较大时,建议对word_embedding使用模型并行策略,即切分参数。当前训练切分了数据,若改为模型并行,可提升训练效率。
文档参考:https://mindspore.cn/tutorials/experts/zh-CN/master/parallel/pangu_alpha.html
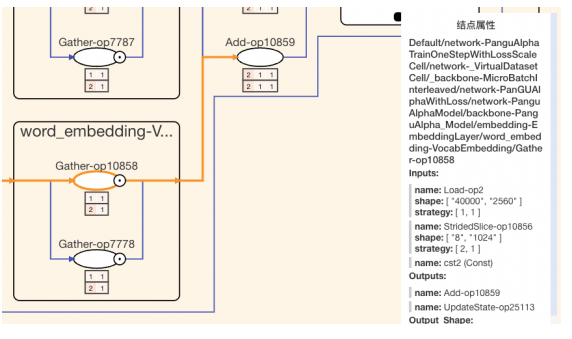
图 算子策略矩阵示例
3.2 集群性能分析
1.9版本中,我们将性能数据与计算图并行策略相结合,提供包含集群层次、卡层次、算子层次等多层次分析的性能可视分析链路,能够帮助用户发现大模型并行训练过程中的常见异常、理解并行训练执行过程。
以对4卡ResNet-50模型并行训练的调优为例,如下图所示,该模型运行过程中2、3两个设备的通信时间相对较长。在通信图中圈选2、3这两个设备,在弹出的邻接矩阵中,观察到allReduce_237_245这一异常通信结点占据了该通信链路的大部分带宽。
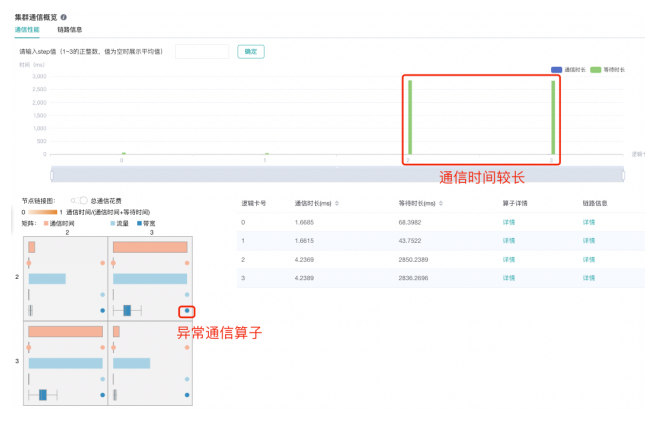
图 集群通信面板
来到执行总览界面,如下图所示,查看执行总览中的Marey图,发现2,3号设备包含在stage1中,刷选算子密集区域,可以发现用时较长的通信算子。这可能是由于通信算子融合切分策略设置不合理导致的,用户可尝试调节all_reduce_fusion_config参数,提升模型的训练效率。在执行总览的并行策略视图中,我们还可以观察到该次训练采用了流水线并行的方案。结合该视图下方缩略图及Marey图,可以进一步分析流水线并行bubble的情况。
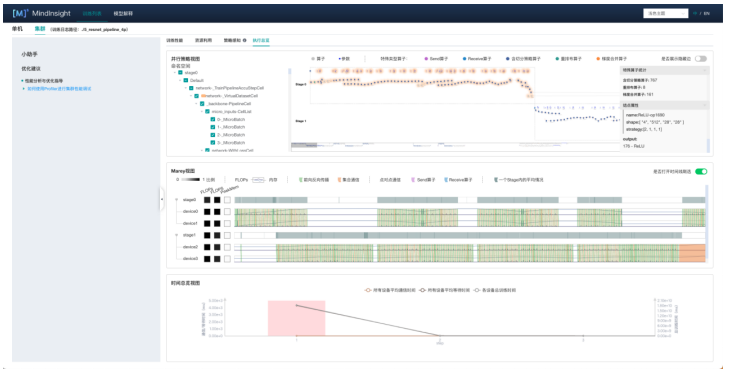
图 执行总览界面