MindSpore 2.7 Is Officially Released to Support ZeroBubbleV Pipeline Parallel Scheduler, Improving Training Efficiency, Adapting to the vLLM V1 Architecture, and Improving DeepSeek-V3 Inference Performance Through Combination Optimization
MindSpore 2.7 Is Officially Released to Support ZeroBubbleV Pipeline Parallel Scheduler, Improving Training Efficiency, Adapting to the vLLM V1 Architecture, and Improving DeepSeek-V3 Inference Performance Through Combination Optimization
After months of development and contributions from the MindSpore open-source community, the MindSpore 2.7 framework is now available.
In terms of improving the training performance of LLMs, the ZeroBubbleV pipeline parallel scheduler is added to further reduce the bubble time, and the recomputing communication masking technology is innovatively implemented to improve the training efficiency of the LLM recomputing.
In terms of ecosystem compatibility and expansion, the upgrade adapts to vLLM v0.8.3 and the V1 architecture, and multiple combination optimizations are used to significantly improve the DeepSeek-V3 inference performance.
In terms of reinforcement learning training and inference performance improvement, even inference sampling and dynamic packing training are supported to improve throughput efficiency. In addition, the 6D parallel weight rearrangement technology is supported to implement weight rearrangement under any model parallelism policy, and reinforcement learning resumable training is supported to implement flexible training, debugging, and deployment.
In terms of tool efficiency improvement, the online monitoring platform (msMonitor) is provided to implement quick performance diagnosis. In addition, the msprobe tool supports module-level dump and automatic comparison of static graphs, improving problem locating efficiency.
Now, let's delve into the key features of MindSpore 2.7.
-- Higher LLM Training Performance --
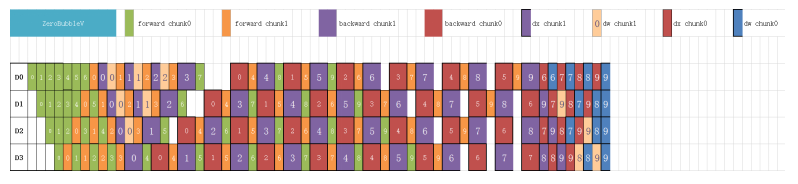
1 ZeroBubbleV Pipeline Parallel Scheduler Further Reducing the Bubble Time and Achieving a Higher Proportion of Computing Communication Overlapping
Pipeline parallelism is a common parallel mode for large-scale distributed training. However, pipeline parallelism inevitably introduces bubbles, reducing equipment utilization. MindSpore 2.7 supports the ZeroBubbleV pipeline scheduler. As shown in the following figure, the computing of dx and dw is separated, and dw is filled into the bubble for computing. This further reduces the idle time of the machine and supports 1B1F (that is, one backward and one forward) fusion masking in the forward and backward alternating execution phase, improving training efficiency.
Reference link: https://www.mindspore.cn/docs/en/master/features/parallel/pipeline_parallel.html
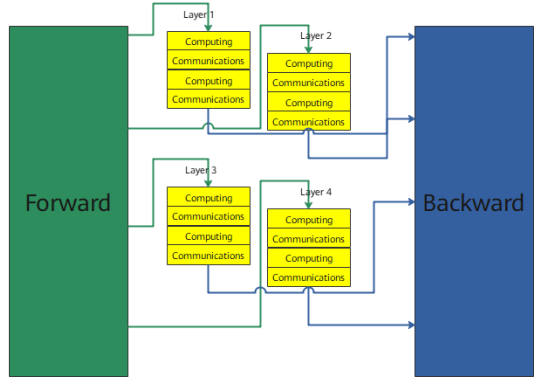
2 Implementing the Recomputing Communication Masking Technology to Improve the Training Efficiency of LLM Recomputing
As the number of Transformer model layers exceeds 1,000, the traditional training mode faces two core challenges: (1) Explosive graphics memory usage: Intermediate activation values need to be stored during backpropagation. The cache usage of a network with hundreds of layer exceeds 400 GB. (2) Communication blocking: In distributed training, the communication accounts for more than 50%, and the computing utilization is less than 60%.
In this case, for graphics memory overheads, the industry usually uses the recomputing solution to greatly reduce the activation value overhead. Full recomputing can minimize the activation value overhead, but the overhead of recomputing is also large.
MindSpore 2.7 innovatively implements the recomputing communication overlapping architecture. The pipeline mechanism is used to improve the efficiency of recomputing. As shown in the following figure, the recomputing layers are dynamically divided into two groups (for example, layers 1 and 2 are group A, and layers 3 and 4 are group B). The recomputing communication overlapping between two layers are implemented in each group, improving the performance of the recomputing module by 15%.
-- Ecosystem Compatibility and Extension --
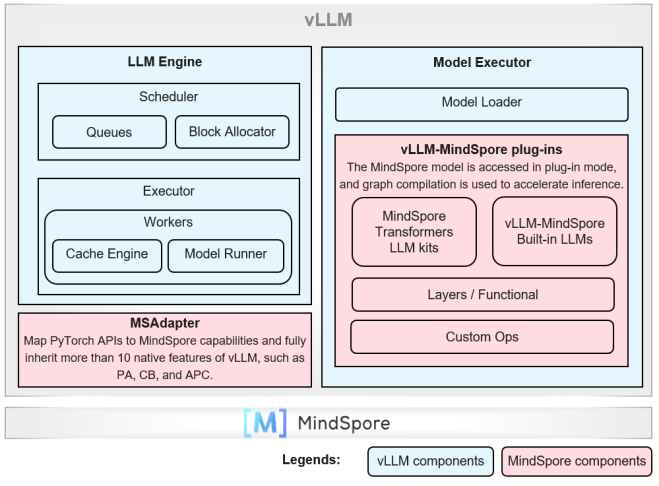
3 Upgrade Adapting to vLLM v0.8.3 and the V1 Architecture, and Combination Optimization Significantly Improving the Inference Performance of DeepSeek-V3
The vLLM-MindSpore plug-in of MindSpore 2.7 is upgraded to adapt to vLLM v0.8.3 and supports the V0 and V1 architectures. Service features such as prefix caching, chunked prefill, multi-step scheduling, MTP, and multi-LoRA are added. In addition, the dynamic graph (PyNative) and Just-In-Time (JIT) compilation are used to connect the MindSpore LLM to the vLLM backend, significantly improving the inference postprocessing performance.
MindSpore also uses multiple optimization combinations to significantly improve the inference performance of sparse MoE LLMs represented by DeepSeek-V3/R1.
1. Hybrid parallelism: Tensor parallelism (TP), data parallelism (DP), and expert parallelism (EP) are deployed for the attention and MoE units, improving the multi-request throughput of DeepSeek-V3/R1 by more than 35%.
2. Inference fusion operators: Fusion operators oriented to sparse MoE computing, such as MoeInitRoutingQuant and MultiLatentAttention, and communication optimization operators, such as Combine and Dispatch, are added to reduce the operator delivery and waiting latency.
3. Model quantization: W8A8 static quantization is improved to reduce the runtime overhead of quantization inference and improve the precision in scenarios such as function call. W4A16 quantization inference is supported, and the DeepSeek-V3/R1 model can be deployed on a single Atlas 800I A2 (64 GB) server.
With the preceding performance optimization technologies, two Atlas 800I A2 (64 GB) servers can be deployed to perform DeepSeek-R1/V3 W8A8 quantization inference. When the decoding latency is restricted to less than or equal to 100 ms, the throughput of 256-sequence input/output non-first tokens can reach 2600 tokens/s or higher, entering the first echelon of open-source inference solutions.
Reference: https://www.mindspore.cn/vllm_mindspore/docs/en/master/index.html
-- Reinforcement Learning Training and Inference Performance Improvement --
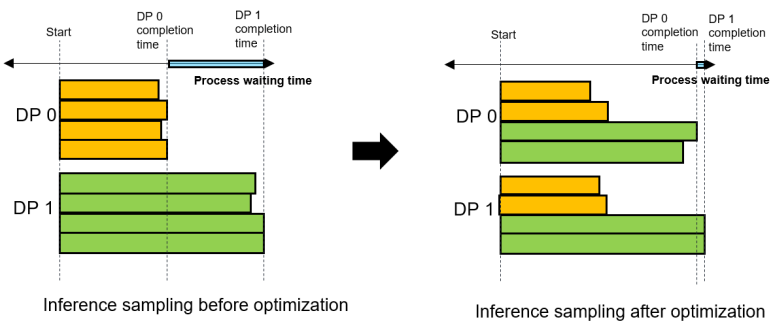
4 Even Inference Sampling, Improving the End-to-End Throughput of Data Generation
In the traditional reinforcement learning experience collection process, different DPs process their own problems. However, the answer lengths of different problems are severely unbalanced, which causes large "waiting bubbles" and leads to poor end-to-end performance. As a result, the process may be interrupted due to long waiting time. In the latest version of MindSpore RLHF, the even inference sampling technology is used. As shown in the following figure, different problems are evenly allocated to each DP. The load of each inference instance is balanced as much as possible to greatly reduce the waiting time between different DPs, ensuring the stable system running and improving the inference performance by about 5% to 10%.
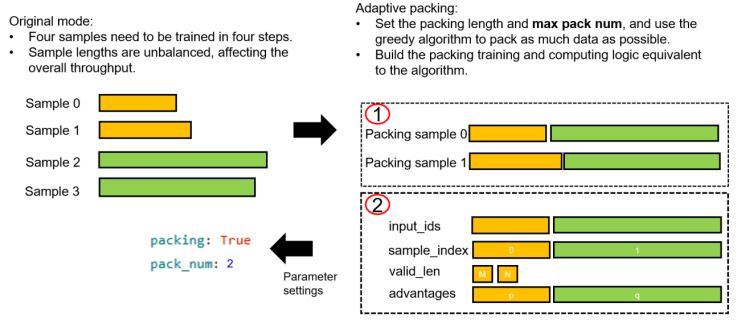
5 Dynamic Packing Training with Reinforcement Learning, Doubling the Training Throughput
In the pre-training and fine-tuning phases, packing training has been proven to improve the end-to-end training speed quickly with little impact on the training effect. In the latest version of MindSpore RLHF, an algorithmically equivalent dynamic packing training solution is proposed. As shown in the following figure, its main function is to dynamically combine samples based on the preset maximum pack length and maximum pack quantity on the premise that the loss function is equivalent, thereby maximizing the reduction of the number of samples without truncating the samples (which may affect the sample quality). In actual tests, dynamic packing can reduce the training time by about 40% without degrading the training effect.
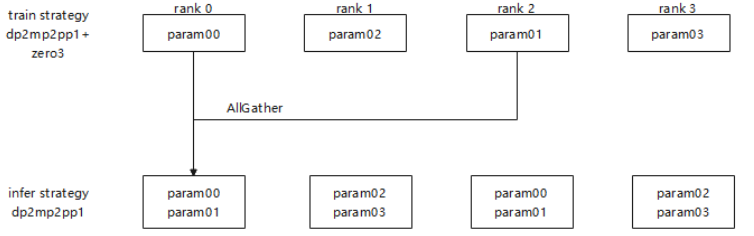
6 6D Parallel Weight Rearrangement Technology, Implementing Weight Rearrangement Under Any Model Parallelism Policy
MindSpore RLHF weight rearrangement derives the rearrangement operator list based on the layout information of the MindSpore training network and inference network. Layout information is a way to express tensor layout in MindSpore. The device matrix and tensor map the dimensions in which the current weight is sharded and the ranks to which each shard is distributed. Layout information can express existing general parallel policies with 6D parallelism, such as DP, TP, CP, PP, optimizer parallelism, and EP.
As shown in the following figure, the current weight rearrangement solution with 6D parallelism has a great advantage in generalization compared with the case-by-case manual rearrangement in the industry. As long as the sharding policy can be expressed by the layout provided by MindSpore, the rearrangement list can be derived and executed using a unified code to complete online rearrangement.
7 Resumable Training of Reinforcement Learning for Flexible Training, Debugging, and Deployment
In reinforcement learning, as the model scale and cluster scale increase, training may be interrupted like that in fine-tuning and pre-training. Resumable training is essential for reinforcement learning. In the latest version of MindSpore RLHF, resumable training is implemented for reinforcement learning scenarios. In the loading of the inference, training, and reference models, load the training weights and optimizer weights to ensure that the training status is consistent. Then, use the training weight and 6D weight rearrangement technology to arrange the weights on the inference and ref models, greatly reducing the I/O time for model loading. Currently, you can fully interconnect with the loss and training status before the interrupt to implement resumable training.
Reference link: https://gitee.com/mindspore/mindrlhf
-- Higher Tool Efficiency --
8 Online Monitoring Platform msMonitor for Fast Performance Diagnosis
In the AI computing field, as the model scale continues to expand, training performance optimization has become a key challenge faced by developers. In particular, in large-scale distributed training scenarios, the traditional performance monitoring solution has obvious shortcomings. First, the passive monitoring policy is adopted. Data collection can be triggered only after performance jitter occurs, causing significant delay in problem locating. Second, the parsing and dumping efficiency of the traditional solution is low when massive performance data (usually hundreds of GB) is generated during training, further prolonging the problem diagnosis period. These defects not only affect the troubleshooting efficiency, but also cause a waste of computing resources.
MindSpore 2.7 adds the function of connecting MindSpore Profiler to the online monitoring platform. You can use the monitor function of the online monitoring platform to observe the performance deterioration points of training in real time when using the MindSpore Profiler framework cluster training scenario, and preliminarily locate performance problems. Subsequently, users can use the Profiler trace dump function (precise collection) of the online monitoring platform to collect complete performance data, analyze and locate performance bottlenecks, and help developers optimize model performance more efficiently.
With the combination of routine monitoring and precise collection, msMonitor can meet the real-time monitoring requirements during long-term stable training of clusters and perform targeted analysis on performance bottlenecks, significantly improving model training efficiency.
Reference: https://gitee.com/ascend/mstt/tree/master/msmonitor
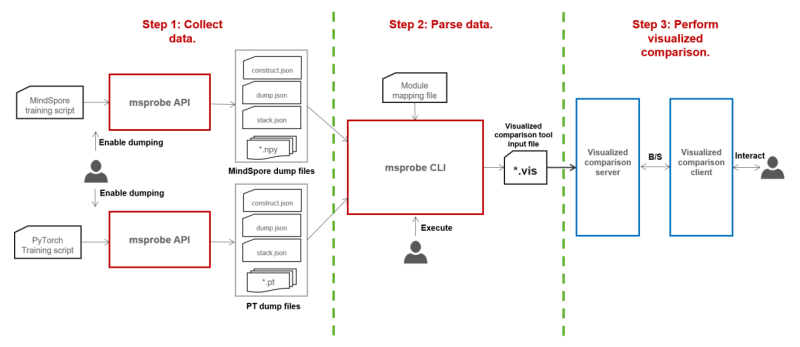
9 msprobe Supports Module-Level Dump and Automatic Comparison of Static Graphs, Improving Fault Locating Efficiency
msprobe supports module-level dump and automatic comparison of static graphs, which is useful for locating precision issues in LLMs. As shown in the following figure, the msprobe tool can be used to dump the forward and backward input and output data of network modules or dump the max, min, mean, and l2norm statistics. Then, the mapping file is used to establish the mapping between MindSpore Transformers and Megatron network modules. Finally, the visualization tool is used to display the network hierarchy and compute the precision against the benchmark data, so as to quickly locate the module where the precision issue occurs. This effectively improves the efficiency of locating intra- and cross-framework precision issues in MindSpore static graphs.