流水线并行
![]()
概述
近年来,神经网络的规模几乎是呈指数型增长。受单卡内存的限制,训练这些大模型用到的设备数量也在不断增加。受server间通信带宽低的影响,传统数据并行叠加模型并行的这种混合并行模式的性能表现欠佳,需要引入流水线并行。流水线并行能够将模型在空间上按阶段(Stage)进行切分,每个Stage只需执行网络的一部分,大大节省了内存开销,同时缩小了通信域,缩短了通信时间。MindSpore能够根据用户的配置,将单机模型自动地转换成流水线并行模式去执行。
流水线并行模型支持的硬件平台包括Ascend、GPU,需要在Graph模式下运行。
相关接口:
mindspore.set_auto_parallel_context(parallel_mode=ParallelMode.SEMI_AUTO_PARALLEL, pipeline_stages=NUM, pipeline_result_broadcast=True):设置半自动并行模式,且设置pipeline_stages用来表明Stage的总数为NUM,必须在初始化网络之前调用。pipeline_result_broadcast表示流水线并行推理时,最后一个stage的结果是否广播给其余stage。nn.PipelineCell(loss_cell, micro_size):流水线并行需要在LossCell外再包一层PipelineCell,并指定MicroBatch的size。为了提升机器的利用率,MindSpore将MiniBatch切分成了更细粒度的MicroBatch,最终的loss则是所有MicroBatch计算的loss值累加。其中,MicroBatch的size必须大于等于Stage的数量。nn.PipelineGradReducer(parameters):流水线并行需要使用PipelineGradReducer来完成梯度聚合。这是因为流水线并行中,其输出是由多个micro-batch的结果相加得到,因此其梯度也需要进行累加。mindspore.parallel.sync_pipeline_shared_parameters(net): 在推理场景下,用于同步不同stage之间共享权重。
基本原理
流水线(Pipeline)并行是将神经网络中的算子切分成多个Stage,再把Stage映射到不同的设备上,使得不同设备去计算神经网络的不同部分。流水线并行适用于模型是线性的图结构。如图1所示,将4层MatMul的网络切分成4个Stage,分布到4台设备上。正向计算时,每台机器在算完本台机器上的MatMul之后将结果通过通信算子发送(Send)给下一台机器,同时,下一台机器通过通信算子接收(Receive)上一台机器的MatMul结果,同时开始计算本台机器上的MatMul;反向计算时,最后一台机器的梯度算完之后,将结果发送给上一台机器,同时,上一台机器接收最后一台机器的梯度结果,并开始计算本台机器的反向。
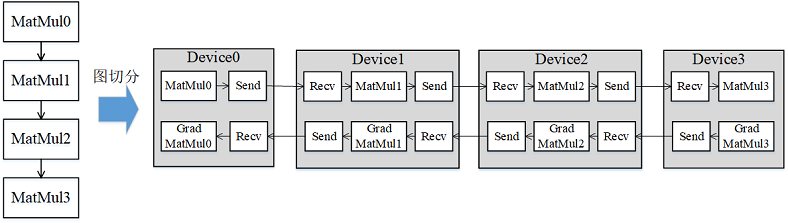
图1:流水线并行的图切分示意图
Gpipe流水线并行调度
简单地将模型切分到多设备上并不会带来性能的提升,因为模型的线性结构在同一时刻只有一台设备在工作,而其它设备在等待,造成了资源的浪费。为了提升效率,流水线并行进一步将小批次(MiniBatch)切分成更细粒度的微批次(MicroBatch),在微批次中采用流水线式的调度,从而达到提升效率的目的,如图2所示。将小批次切分成4个微批次,4个微批次在4个组上执行形成流水线。微批次的梯度汇聚后用来更新参数,其中每台设备只存有并更新对应组的参数。其中白色序号代表微批次的索引。
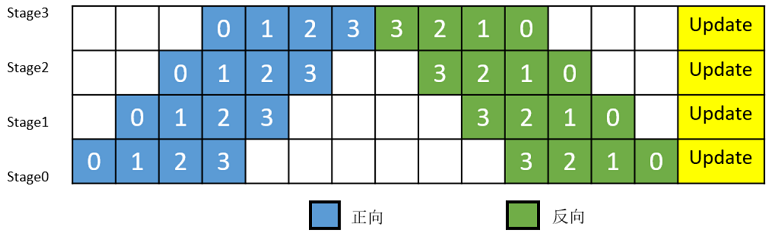
图2:带MicroBatch的流水线并行执行时间线示意图
1F1B流水线并行调度
MindSpore的流水线并行实现中对执行序进行了调整,来达到更优的内存管理。如图3所示,在编号为0的MicroBatch的正向执行完后立即执行其反向,这样做使得编号为0的MicroBatch的中间结果的内存得以更早地(相较于图2)释放,进而确保内存使用的峰值比图2的方式更低。
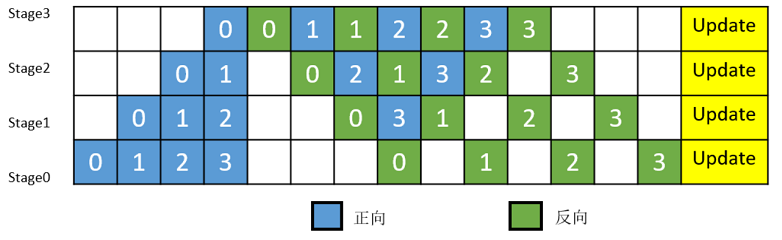
图3:MindSpore流水线并行执行时间线示意图
interleaved pipeline调度
为了提升流水线并行的效率,减少Bubble的占比,Megatron-LM提出了一种新的流水线并行调度:“interleaved pipeline”。传统的流水线并行通常会在一个stage上放置几个连续的模型层(如:Transformer层),如图3所示。而在interleaved pipeline调度中,每个stage会对非连续的模型层进行交错式的计算,以更多的通信量来进一步降低Bubble的占比,如图4所示。例如:传统流水线并行每个stage有2个模型层,即:stage0有第0-1层,stage1有第2-3层,stage3有第4-5层,stage4有第6-7层;在interleaved pipeline中,stage0有第0层和第4层,stage1有第1层和第5层,stage2有第2层和第6层,stage3有第3层和第7层。

图4: interleaved pipeline调度
MindSpore中的interleaved pipeline调度
MindSpore在Megatron-LM的interleaved pipeline调度的基础上做了内存优化,具体做法是将部分前向的执行序往后移动,如图5所示,这样可以使得在内存峰值时刻,累积更少的MicroBatch内存。

图5: MindSpore的interleaved pipeline调度
训练操作实践
下面以Ascend或者GPU单机8卡为例,进行流水线并行操作说明:
样例代码说明
下载完整的样例代码:distributed_pipeline_parallel。
目录结构如下:
└─ sample_code
├─ distributed_pipeline_parallel
├── distributed_pipeline_parallel.py
└── run.sh
...
其中,distributed_pipeline_parallel.py是定义网络结构和训练过程的脚本。run.sh是执行脚本。
配置分布式环境
通过context接口指定运行模式、运行设备、运行卡号等,与单卡脚本不同,并行脚本还需指定并行模式parallel_mode为半自动并行模式,并通过init初始化HCCL或NCCL通信。此外,还需配置pipeline_stages=2指定Stage的总数。此处不设置device_target会自动指定为MindSpore包对应的后端硬件设备。
import mindspore as ms
from mindspore.communication import init
ms.set_context(mode=ms.GRAPH_MODE)
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.SEMI_AUTO_PARALLEL, pipeline_stages=2)
init()
ms.set_seed(1)
如果需要跑interleaved pipeline调度,还需要配置:pipeline_config={'pipeline_scheduler':'1f1b', 'pipeline_interleave':True},需要注意的是,MindSpore的interleaved pipeline调度还在完善阶段,目前在O0或者O1模式下表现会更好。
import mindspore as ms
ms.set_auto_parallel_context(pipeline_config={'pipeline_scheduler':'1f1b', 'pipeline_interleave':True})
数据集加载
在流水线并行场景下,数据集加载方式与单卡加载方式一致,代码如下:
import os
import mindspore.dataset as ds
def create_dataset(batch_size):
dataset_path = os.getenv("DATA_PATH")
dataset = ds.MnistDataset(dataset_path)
image_transforms = [
ds.vision.Rescale(1.0 / 255.0, 0),
ds.vision.Normalize(mean=(0.1307,), std=(0.3081,)),
ds.vision.HWC2CHW()
]
label_transform = ds.transforms.TypeCast(ms.int32)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
data_set = create_dataset(32)
定义网络
流水线并行网络结构与单卡网络结构基本一致,区别在于增加了流水线并行策略配置。流水线并行需要用户去定义并行的策略,通过调用pipeline_stage接口来指定每个layer要在哪个stage上去执行。pipeline_stage接口的粒度为Cell。所有包含训练参数的Cell都需要配置pipeline_stage,并且pipeline_stage要按照网络执行的先后顺序,从小到大进行配置。如果要使能interleaved pipeline调度,pipeline_stage要按照前面章节中介绍的非连续模型层进行交错式配置。在单卡模型基础上,增加pipeline_stage配置后如下:
在pipeline并行下,使能Print/Summary/TensorDump相关算子时,需要把该算子放到有pipeline_stage属性的Cell中使用,否则有概率由pipeline并行切分导致算子不生效。
from mindspore import nn, ops, Parameter
from mindspore.common.initializer import initializer, HeUniform
import math
class MatMulCell(nn.Cell):
"""
MatMulCell definition.
"""
def __init__(self, param=None, shape=None):
super().__init__()
if shape is None:
shape = [28 * 28, 512]
weight_init = HeUniform(math.sqrt(5))
self.param = Parameter(initializer(weight_init, shape), name="param")
if param is not None:
self.param = param
self.print = ops.Print()
self.matmul = ops.MatMul()
def construct(self, x):
out = self.matmul(x, self.param)
self.print("out is:", out)
return out
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.layer1 = MatMulCell()
self.relu1 = nn.ReLU()
self.layer2 = nn.Dense(512, 512)
self.relu2 = nn.ReLU()
self.layer3 = nn.Dense(512, 10)
def construct(self, x):
x = self.flatten(x)
x = self.layer1(x)
x = self.relu1(x)
x = self.layer2(x)
x = self.relu2(x)
logits = self.layer3(x)
return logits
net = Network()
net.layer1.pipeline_stage = 0
net.relu1.pipeline_stage = 0
net.layer2.pipeline_stage = 0
net.relu2.pipeline_stage = 1
net.layer3.pipeline_stage = 1
训练网络
在这一步,我们需要定义损失函数、优化器以及训练过程,与单卡模型不同,在这部分需要调用两个接口来配置流水线并行:
首先需要定义LossCell,本例中调用了
nn.WithLossCell接口封装网络和损失函数。然后需要在LossCell外包一层
nn.PipelineCell,并指定MicroBatch的size。详细请参考本章概述中的相关接口。
除此之外, 还需要增加 nn.PipelineGradReducer 接口,用于处理流水线并行下的梯度,该接口的第一个参数为需要更新的网络参数。
import mindspore as ms
from mindspore import nn, ops
optimizer = nn.SGD(net.trainable_params(), 1e-2)
loss_fn = nn.CrossEntropyLoss()
net_with_loss = nn.PipelineCell(nn.WithLossCell(net, loss_fn), 4)
net_with_loss.set_train()
def forward_fn(inputs, target):
loss = net_with_loss(inputs, target)
return loss
grad_fn = ops.value_and_grad(forward_fn, None, optimizer.parameters)
pp_grad_reducer = nn.PipelineGradReducer(optimizer.parameters)
@ms.jit
def train_one_step(inputs, target):
loss, grads = grad_fn(inputs, target)
grads = pp_grad_reducer(grads)
optimizer(grads)
return loss, grads
for epoch in range(10):
i = 0
for data, label in data_set:
loss, grads = train_one_step(data, label)
if i % 10 == 0:
print("epoch: %s, step: %s, loss is %s" % (epoch, i, loss))
i += 1
目前流水线并行不支持自动混合精度特性。
流水线并行训练更适合用
model.train的方式,这是因为流水线并行下的TrainOneStep逻辑复杂,而model.train内部封装了针对流水线并行的TrainOneStepCell,易用性更好。
运行单机8卡脚本
接下来通过命令调用对应的脚本,以mpirun启动方式,8卡的分布式训练脚本为例,进行分布式训练:
bash run.sh
训练完后,日志文件保存到log_output目录下,其中部分文件目录结构如下:
└─ log_output
└─ 1
├─ rank.0
| └─ stdout
├─ rank.1
| └─ stdout
...
结果保存在log_output/1/rank.*/stdout中,示例如下:
epoch: 0 step: 0, loss is 9.137518
epoch: 0 step: 10, loss is 8.826559
epoch: 0 step: 20, loss is 8.675843
epoch: 0 step: 30, loss is 8.307994
epoch: 0 step: 40, loss is 7.856993
epoch: 0 step: 50, loss is 7.0662785
...
Print 算子的结果为:
out is:
Tensor(shape=[8, 512], dtype=Float32, value=
[[ 4.61914062e-01 5.78613281e-01 1.34995094e-01 ... 8.54492188e-02 7.91992188e-01 2.13378906e-01]
...
[ 4.89746094e-01 3.56689453e-01 -4.90966797e-01 ... -3.30078125e-e01 -2.38525391e-01 7.33398438e-01]])
其他启动方式如动态组网、rank table的启动可参考启动方式。
推理操作实践
下面以Ascend或者GPU单机8卡为例,进行流水线并行操作说明:
样例代码说明
下载完整的样例代码:distributed_pipeline_parallel。
目录结构如下:
└─ sample_code
├─ distributed_pipeline_parallel
├── distributed_pipeline_parallel_inference.py
└── run_inference.sh
...
其中,distributed_pipeline_parallel_inference.py是定义网络结构和推理过程的脚本。run_inference.sh是执行脚本。
配置分布式环境
通过context接口指定运行模式、运行设备、运行卡号等,与单卡脚本不同,并行脚本还需指定并行模式parallel_mode为半自动并行模式,并通过init初始化HCCL或NCCL通信。此外,还需配置pipeline_stages=4指定Stage的总数。此处不设置device_target会自动指定为MindSpore包对应的后端硬件设备。pipeline_result_broadcast=True表示流水线并行推理时,将最后一个stage的结果广播给其余stage,可以用于自回归推理场景。
import mindspore as ms
from mindspore.communication import init
ms.set_context(mode=ms.GRAPH_MODE)
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.SEMI_AUTO_PARALLEL, dataset_strategy="full_batch",
pipeline_stages=4, pipeline_result_broadcast=True)
init()
ms.set_seed(1)
定义网络
流水线并行需要用户去定义并行的策略,通过调用pipeline_stage接口来指定每个layer要在哪个stage上去执行。pipeline_stage接口的粒度为Cell。所有包含训练参数的Cell都需要配置pipeline_stage,并且pipeline_stage要按照网络执行的先后顺序,从小到大进行配置。在单卡模型基础上,增加pipeline_stage配置后如下:
import numpy as np
from mindspore import lazy_inline, nn, ops, Tensor, Parameter, sync_pipeline_shared_parameters
class VocabEmbedding(nn.Cell):
"""Vocab Embedding"""
def __init__(self, vocab_size, embedding_size):
super().__init__()
self.embedding_table = Parameter(Tensor(np.ones([vocab_size, embedding_size]), ms.float32),
name='embedding_table')
self.gather = ops.Gather()
def construct(self, x):
output = self.gather(self.embedding_table, x, 0)
output = output.squeeze(1)
return output, self.embedding_table.value()
class Head(nn.Cell):
def __init__(self):
super().__init__()
self.matmul = ops.MatMul(transpose_b=True)
def construct(self, state, embed):
return self.matmul(state, embed)
class Network(nn.Cell):
"""Network"""
@lazy_inline
def __init__(self):
super().__init__()
self.word_embedding = VocabEmbedding(vocab_size=32, embedding_size=32)
self.layer1 = nn.Dense(32, 32)
self.layer2 = nn.Dense(32, 32)
self.head = Head()
def construct(self, x):
x, embed = self.word_embedding(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.head(x, embed)
return x
# Define network and set pipeline stage
net = Network()
net.word_embedding.pipeline_stage = 0
net.layer1.pipeline_stage = 1
net.layer2.pipeline_stage = 2
net.head.pipeline_stage = 3
推理网络
在network外包一层PipelineCellInference,并指定MicroBatch的size。PipelineCellInference中将输入切分为若干个micro batch,执行推理网络,最后将若干个micro batch推理结果通过ops.Concat算子沿batch轴拼接后返回。
在上一步中,embed被self.word_embedding和self.head两层共享,并且这两层被切分到了不同的stage上。在执行推理前,先编译计算图inference_network.compile(),再调用sync_pipeline_shared_parameters(inference_network)接口,框架自动同步stage间的共享权重。
from mindspore import nn, ops
class PipelineCellInference(nn.Cell):
"""Pipeline Cell Inference wrapper"""
def __init__(self, network, micro_batch_num):
super().__init__()
self.network = network
self.micro_batch_num = micro_batch_num
self.concat = ops.Concat()
def construct(self, x):
"""Apply the pipeline inference"""
ret = ()
for i in range(self.micro_batch_num):
micro_batch_size = x.shape[0] // self.micro_batch_num
start = micro_batch_size * i
end = micro_batch_size * (i + 1)
micro_input = x[start:end]
micro_output = self.network(micro_input)
ret = ret + (micro_output,)
ret = self.concat(ret)
return ret
inference_network = PipelineCellInference(network=net, micro_batch_num=4)
inference_network.set_train(False)
# Compile and synchronize shared parameter.
input_ids = Tensor(np.random.randint(low=0, high=32, size=(8, 1)), ms.int32)
inference_network.compile(input_ids)
sync_pipeline_shared_parameters(inference_network)
# Execute the inference network
logits = inference_network(input_ids)
print(logits.asnumpy())
运行单机8卡脚本
接下来通过命令调用对应的脚本,以msrun启动方式,8卡的分布式推理脚本为例,进行分布式训练:
bash run_inference.sh
训练完后,日志文件保存到pipeline_inference_logs目录下,其中部分文件目录结构如下:
└─ pipeline_inference_logs
├── scheduler.log
├── worker_0.log
├── worker_1.log
├── worker_2.log
...
结果保存在pipeline_inference_logs/worker_0.log中,示例如下:
[[0.01181556 0.01181556 0.01181556 0.01181556 0.01181556 0.01181556 0.01181556
0.01181556 0.01181556 0.01181556 0.01181556 0.01181556 0.01181556 0.01181556
0.01181556 0.01181556 0.01181556 0.01181556 0.01181556 0.01181556 0.01181556
0.01181556 0.01181556 0.01181556 0.01181556 0.01181556 0.01181556 0.01181556
0.01181556 0.01181556 0.01181556 0.01181556 0.01181556 0.01181556 0.01181556
0.01181556 0.01181556]
...]