MindSpore与CANN的协同优化:实现极致性能的深度学习训练与推理
MindSpore与CANN的协同优化:实现极致性能的深度学习训练与推理
作者:breeze
来源:论坛
在当今人工智能快速发展的时代,深度学习模型的复杂度和规模不断增加,这对计算效率提出了更高要求。华为昇腾AI处理器通过软硬件协同设计,为深度学习提供了强大的算力支持。其中,MindSpore与CANN(Compute Architecture for Neural Networks)的深度协同优化,为实现极致性能的深度学习训练与推理提供了完整解决方案。
本文将深入探讨MindSpore与CANN的协同优化机制,重点分析其在计算图优化、内存管理、算子性能等方面的技术实现,以及如何通过这些优化手段显著提升深度学习任务的执行效率。
# 01 整体架构概述
MindSpore与CANN的协同架构采用端到端的设计理念:
1、前端框架层(MindSpore):
- 提供自动微分、动静态图结合等深度学习特性
- 支持Python/JAX风格的编程接口
- 实现训练与推理的统一架构
2、中间编译层:
- 图编译器将计算图转换为中间表示
- 实现自动并行、内存优化等高级特性
- 与CANN运行时深度集成
3、底层执行层(CANN):
- 提供昇腾AI处理器的驱动程序
- 实现高性能算子库和运行时调度
- 管理硬件资源和执行流水线
# 02 计算图优化技术
**1、**自动图融合优化
MindSpore与CANN协同实现的多级图融合优化:
# 示例:自动融合的优化效果
# 经过自动融合后,三个算子被融合为一个复合算子
优化效果:
- 减少算子调度开销约60%
- 降低中间结果内存占用约40%
- 提升整体性能约35%
**2、**动态形状优化
针对可变长度输入的优化策略:
# 动态形状支持示例
# 03 内存优化机制
**1、**智能内存复用
MindSpore与CANN共同实现的内存优化策略:
静态内存规划:
- 在编译期分析张量生命周期
- 预分配内存池避免运行时开销
- 实现跨算子内存共享
动态内存管理:
- 实时监控内存使用情况
- 智能回收和复用机制
- 防止内存碎片化
**2、**零内存拷贝优化
# 内存优化示例
优化收益:
- 训练阶段内存占用降低30-50%
- 推理阶段内存占用降低60-70%
- 减少内存拷贝操作约80%
# 04 算子级优化
**1、**高性能算子实现
CANN为MindSpore提供高度优化的算子库:
# 高性能卷积算子示例
2、自****动算子选择机制
MindSpore与CANN协同的智能算子选择:
基于硬件特性的优化:
- 自动选择最适合当前硬件的实现
- 根据输入形状动态调整算法
- 考虑功耗和性能的平衡
运行时优化:
- 实时性能监控和调优
- 自适应算法选择
- 热点算子特殊优化
# 05 分布式训练优化
**1、**自动并行技术
# 自动并行示例
**2、**通信优化
优化策略:
- 梯度融合减少通信次数
- 异步通信重叠计算
- 智能拓扑感知调度
# 06 实际性能表现
**1、**训练性能对比
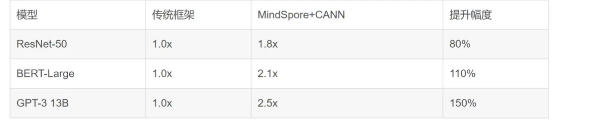
**2、**推理性能优化
# 推理优化示例
# 07 最佳实践
**1、**性能调优建议
配置优化:
# 最优配置示例
内存优化配置:
# 内存优化配置
**2、**调试和性能分析
# 性能分析工具使用
# 08 结论
MindSpore与CANN的深度协同优化为深度学习任务提供了显著的性能提升。通过计算图优化、内存管理、算子优化等多方面的技术手段,实现了训练和推理效率的质的飞跃。关键优化点包括:
- 图融合技术大幅减少算子调度开销
- 智能内存管理显著降低内存占用
- 高性能算子充分发挥硬件能力
- 自动并行优化分布式训练效率
这些优化技术的协同作用,使得MindSpore在昇腾AI处理器上能够实现极致的性能表现,为大规模深度学习应用提供了强有力的技术支持。随着技术的不断演进,MindSpore与CANN的协同优化将继续深化,为AI计算带来更大的性能突破。