图像何必要卷积,Attention也能玩转,基于Mindspore利用ViT完成图像分类的简单实践
图像何必要卷积,Attention也能玩转,基于Mindspore利用ViT完成图像分类的简单实践
作者:Seasonmay
来源:昇思论坛
Vision Transformer(ViT)是一种将自然语言处理领域的Transformer架构成功迁移至计算机视觉任务的开创性模型,它突破了传统卷积神经网络(CNN)依赖局部感受野和层级抽象的范式,通过将输入图像分割为非重叠的图像块(patches)并线性嵌入为序列向量,直接模拟自然语言中的“词元”处理方式,再结合Transformer的自注意力机制捕捉全局空间关系,使得模型能够在不依赖卷积操作的情况下,通过多头注意力计算图像块间的长程依赖,从而实现对复杂视觉模式的建模;ViT的核心优势在于其参数共享的注意力机制能够灵活适应不同尺度的视觉特征,且通过预训练-微调策略在大规模数据集(如JFT-300M)上展现出超越传统CNN的迁移学习能力,尤其在数据量充足时,其性能随模型规模扩大呈现显著提升,为视觉任务提供了一种可扩展性更强、全局信息捕捉能力更优的全新范式。
基于MindSpore框架,可以很容易上手ViT的实践,首先准备数据集:
from download import download
这里使用部分ImageNet的数据集进行实验:
import os
然后构建Multi-Head Attention模块,这是ViT中最核心的一部分,代码如下:
from mindspore import nn, ops
然后构建Encoder模块:
from typing import Optional, Dict
然后构建输入的patch Embedding模块,通过将输入图像在每个channel上划分成大小为16 x 16的patch,这一步是通过卷积操作来完成的,当然也可以人工进行划分,但卷积操作也可以达到目的同时还可以进行一次额外的数据处理;例如一幅输入224 x 224的图像,首先经过卷积处理得到14 x 14个patch,那么每一个patch的大小就是16 x 16**。**再将每一个patch的矩阵拉伸成为一个一维向量,从而获得了近似词向量堆叠的效果。上一步得到的一系列大小为16 x 16的patch就转换为长度为196的向量。
class PatchEmbedding(nn.Cell):
随后就可以搭建完整的ViT模型:
from mindspore.common.initializer import Normal
搭完模型架构后,就可以基于数据集训练推理,训练代码如下,模型开始训练前,需要设定损失函数,优化器,回调函数等完整训练ViT模型需要很长的时间,实际应用时根据需要调整epoch_size,当正常输出每个Epoch的step信息时,意味着训练正在进行,通过模型输出可以查看当前训练的loss值和时间等指标。
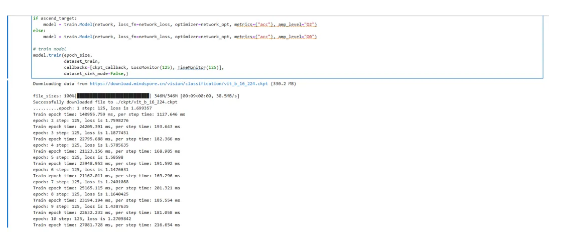
from mindspore.nn import LossBase
训练完成后,可以基于训练好的模型进行评估,看看训练效果如何。
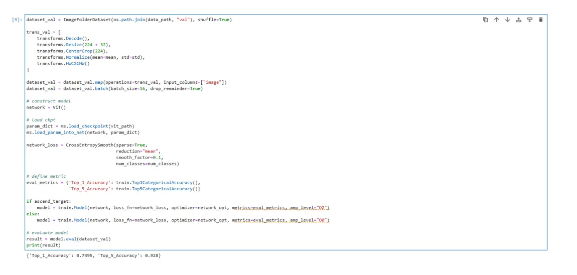
最后,利用模型进行推理,完成实践的最后一步。

import os
推理结果与标签一致,效果还可以,圆满结束。