昇思创新训练营优秀创新案例系列分享第一期:新闻稿情感播报
昇思创新训练营优秀创新案例系列分享第一期:新闻稿情感播报
1、前言
昇思MindSpore作为开源的AI框架,为开发人员带来端边云全场景协同、极简开发、极致性能的体验。为鼓励基于昇思MindSpore进行创新,昇思开源社区对昇思创新训练营优秀创新案例进行转载及解读。本篇文章主要介绍了开发者如何基于昇思MindSpore进行大模型微调及调用模型API服务,完成新闻检索-新闻稿内容情感分类-新闻稿带感情语音播报的全流程实践。项目代码已开源,欢迎各位开发者体验。
2、项目意义和价值
驾驶、通勤等“伴随式”场景,“听新闻”已成主流,但现有机器播报普遍存在一个核心缺陷:情感表达的缺失。无论是报道英雄事迹的振奋,还是播报自然灾害的沉重,现有系统均采用单一中立的语调,极大削弱了新闻的感染力,并阻碍了用户对信息背后完整意图的感知。
本项目通过新闻检索-情感分类-语音播报的端到端流程实现带有感情语调的新闻播报,提升新闻的感染力,同时应用场景也可扩展至新媒体与有声读物、智能座舱与车载助手、教育与陪伴机器人、舆情监控与品牌管理等多种领域。
本项目的创新性体现在从信息获取到情感表达的全流程覆盖。整个系统采用清晰的模块化架构(包括检索、理解和表达),确保了其高效性、可扩展性,并具备了未来端云部署的灵活性。
- 项目名称:新闻情感播报
- 团队成员:徐日晞(上海交通大学)、李子晗(上海应用技术大学)、任思宇(上海工程技术大学)
- 项目代码链接: https://github.com/sunnyxrxrx/Emotional-News-Anchor
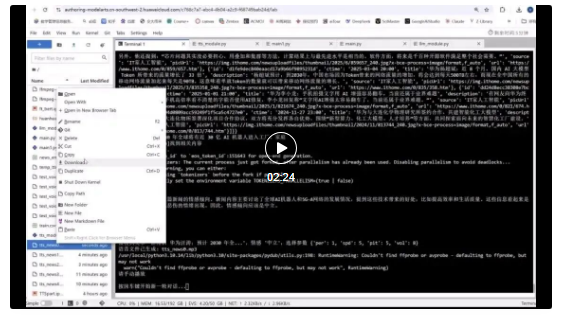
1、运行效果
参见如下视频,可实现连续文字检索、情感分类、语音播报。
1、环境准备
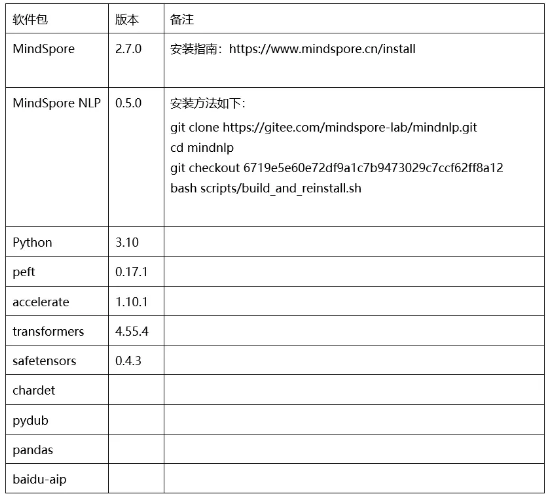
安装环境:
bash setup.sh
2、数据集准备
本项目选择DeepSeek-R1-Distill-Qwen-1.5B模型进行微调,可参考如下命令进行预训练权重的下载:
- 数据集下载:https://figshare.com/articles/dataset/THUCNews\_Chinese\_News\_Text\_Classification\_Dataset/28279964?file=51924092
- 申请数据处理相关API(详情请参考项目仓库代码)
- 数据集处理
python create_label_dataset.py --llm_api_key xxx
# --llm_api_key:你的大模型api_key
# --input_dir:下载数据集的存放位置,默认"./datasets"
# --output_dir:数据标注文件的存放位置,默认"./datasets"
# --csv_name:标注文件名,默认"news_emotion_labeled.csv"
3、模型微调
python ft_deepseek_distill.py
# --model:使用的基座模型,默认"models/DeepSeek-R1-Distill-Qwen-1.5B"
# --input_dir:数据标注文件,默认"./datasets/news_emotion_labeled.csv"
# --save_path:微调模型存放位置,默认"./models/ft_model"
4、启动交互
- 申请新闻检索和语音播报相关API(详情请参考项目仓库代码)
- 启动交互
python main.py --news_search_api_key xxx --speaker_app_id xxx --speaker_api_key xxx --speaker_secret_key xxx --lora_adapter_path xxx
# --news_search_api_key:新闻检索api key,需提供
# --speaker_app_id,--speaker_api_key,--speaker_secret_key为语音播报api相关参数,需提供
# --model:使用的基座模型,默认"models/DeepSeek-R1-Distill-Qwen-1.5B"
# --lora_adapter_path:使用微调模型的权重路径,需提供
# --output_dir:输入语音的存放位置,默认'output'
1、方案流程设计
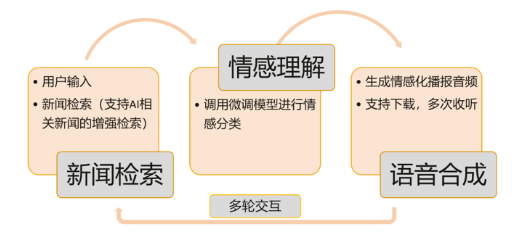
- 新闻检索:系统具备主动信息获取能力,可以根据用户指令,通过API实时检索网络新闻。
- 情感理解:获取新闻后,系统会基于昇思MindSpore微调后的模型,对文本进行深度的多维度情感分析,精准识别出喜悦、悲伤等九种复杂情绪。
- 语音生成:分析得到的情感标签将驱动情感化TTS引擎,自动调整内容的音色、语速和语调,实现从“读稿”到“演绎新闻”的全新体验。
2、情感理解模块架构解析
新闻检索和语音合成主要通过调用API完成,情感理解模块中,我们基于MindSpore进行模型微调,使得模型具备分辨新闻文本情感的能力,在此我们着重介绍下在情感理解模块的架构。
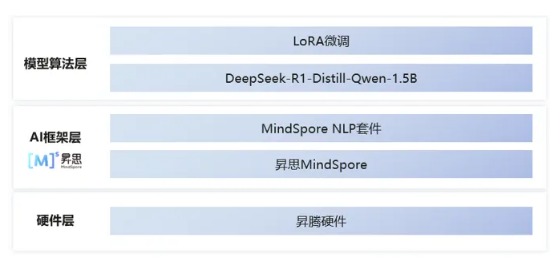
- 硬件层:依托华为云ModelArts平台昇腾算力。
- AI框架层:昇思MindSpore框架提供了函数式+面向对象融合编程、动静统一、高效数据引擎、自动并行等能力, MindSpore NLP套件将这些优势特性与实际需求匹配,实现简便的模型开发,高效的数据预处理,以及预训练模型的快速调用。
- 模型算法层:通过MindSpore NLP套件调用DeepSeek-R1-Distill-Qwen-1.5B模型,并基于标注好的新闻数据实现LoRA微调。
**1、**数据准备(create_label_dataset.py)
采用THUCNews(清华大学中文新闻数据集)作为原始语料库,保障了数据的规模、多样性和高质量。,并利用大模型对更大规模的新闻高效率情感标注(推荐使用deepseek的api)。

下图为数据标注的代码实现,如果开发者准备了其他领域的数据集,也可参考下方逻辑,自行设计prompt和模型解码的超参。因为我们的目标是生成简短的情感分类标签,所以我们的想法是将max_tokens设置成了5,限制输出长度,使模型只输出分类结果,减少意外输出;并将temperature设置成0,让输出更确定。

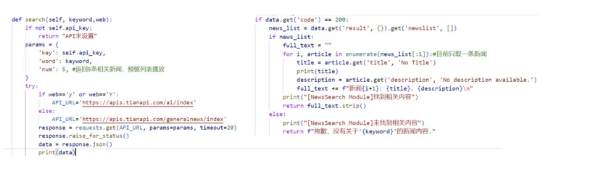
**2、新闻检索功****能实现(**main.py)
为了优化流程,方便用户自主搜索感兴趣的新闻,我们通过以下代码实现了根据用户输入的文字自动检索相关新闻,并支持AI相关新闻的重点搜索。例如,用户输入关键词“华为”后,可以进一步选择是否聚焦与“华为+AI”相关的新闻(建议使用天行数据API进行检索)。
**3、模型微****调(**ft_deepseek_distill.py)
在模型微调部分我们选择了LoRA微调,通过向特定层注入低秩矩阵来实现参数更新,从而节省计算资源和内存。
如下是预训练模型实例化的代码,考虑到算力资源和显存占用,我们选择了一个轻量级的中文模型,如果开发者们有其他的偏好,可以更改model_name进行不同模型的实例化,但需要注意:
- 确保模型的规格适合需求。
- 通常情况下,模型的权重会默认从Hugging Face下载,但由于网络原因,下载可能不成功。建议开发者提前从国内平台下载权重,并在本地加载。

下图是LoRA微调相关的超参配置,开发者可自行调整。参数说明:
- r=8: r是LoRA矩阵的秩。它定义了我们下图里旁路适配器中的矩阵维度,A的维度将是d*r,矩阵B的维度将是r*d。
- lora_alpha=32:它是一个缩放参数,控制LoRA模块中权重更新的缩放比例。
- lora_dropout=0.1:表示在LoRA模块中以10%的概率随机“关闭”某些神经元连接,以减少过拟合的风险。
- target_modules定义了将适配器应用到模型中的哪些层,这里将其应用到了主要的权重层:Q,K,V,投影层O,还有前馈网络的线性层。

**4、情感****化语音生成(**tts_module.py)
我们使用了语音合成技术(Text-to-Speech, TTS)将书面文本转换成人类可以听懂的口头语言。通过调用API,根据情感设置不同的语速、语调等。如下是不同情感的参数参考,我们通过预先定义不同情感所对应的声学参数组合(如语速、语调、音量、发音人等),在调用API时动态传入这些参数,从而生成富含情感。

在这里,我们一共调出了9种不同情感的语调。从调试经验来看,调高语调值(pit)可以模拟兴奋或愉快时的上扬语调,调高音量值(vol)则能模拟外向的情绪,而调整语速(spd)时需要平衡清晰度。同时,配置情感模型(emo)可以进一步提升效果。欢迎开发者们进行尝试,探索更多不同的语调情感。
通过该项目,我们深入了解了国产化AI开发的全流程闭环。我们基于昇思MindSpore框架微调了DeepSeek-R1的蒸馏模型,最终实现了各个交互环节的整合。 在开发过程中,我们也在考虑,DeepSeek-R1-Distill-Qwen这个模型是否是最合适的选择。实际上,这个模型更侧重于文本生成任务,而对于相对简单的情感分类任务,是否会有点“杀鸡用牛刀”?相比之下,像BERT模型可能会更合适一些。不过,这个项目实践本身是一次非常有价值的收获。 后续我们将进一步优化模型的微调,接入语音交互,实现语音输入和输出。同时,我们计划在香橙派上进行部署,探索端云结合或完全在端侧进行推理的方案。