Autoformer模型论文解读,并基于MindSpore NLP推理复现
Autoformer模型论文解读,并基于MindSpore NLP推理复现
Autoformer模型是一种处理时间序列预测任务的深度学习模型,它创新性地结合了深度分解架构(Decomposition Architecture)和自相关机制(Auto-Correlation Mechanism),通过渐进式(progressively)分解和序列级(series-wise)连接来捕捉时间序列的周期性特征,有效地提高了模型对具有明显周期性的时间序列数据的预测能力,尤其适用于处理长时间序列的依赖关系。原文《Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting》由清华大学吴海旭等于2021年发表在NeurIPS顶会。
Autoformer被用于高效且准确地解决长期时间序列预测问题,该类问题极具挑战性,因为其待预测的序列长度远远大于输入的历史序列长度,即需要在有限的历史信息基础上预测更长远的未来时间序列。所谓长时间时序预测,实质上就是利用已知的一段相对较短的历史时间序列数据来预测未来一段相对更长的序列。
若干类似的时间序列预测方法简要对比
在时间序列预测领域涌现了许多模型,有传统统计模型(自回归模型AR、移动平均模型MA、自回归移动平均模型ARMA等)、机器学习模型(随机森林RF、支持向量机SVM等)、深度学习模型(循环神经网络RNN、门控循环单元GRU、时间卷积网络TCN等)和组合(混合)模型。不同的模型适用于不同的时间序列预测任务,选择合适的模型需要考虑数据的特性、预测任务的复杂性、计算资源等因素。Autoformer是一类基于Transformer的深度学习模型,针对长期时间序列预测问题进行设计。我列举了与之类似的若干模型,如表1所示,并对他们的特点、创新点和适用场景进行分析。
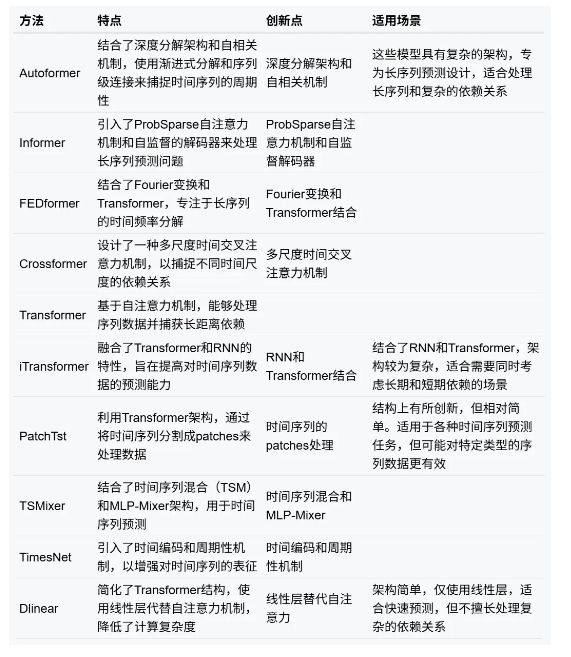
如上表所示,该类模型皆源自于Transformer架构,(除了Dlinear)都采用了注意力机制来捕捉序列中的依赖关系,本身就能够处理序列数据并捕获长距离依赖。比较常用的LSTM模型多步预测效果不尽理想,误差累积是造成该问题的一部分原因,Transformer-based模型是一步产生所有预测结果,在处理长时序问题上有一定优势。从改进策略上来看,Autoformer针对长时间序列预测问题提出了深度分解架构和自相关机制的策略,**Informer和Crossformer等模型则是提出了自注意力机制的变种,iTransformer融合了Transformer和RNN的特性,PatchTst将时间序列分割成patches来处理数据,FEDformer引入了Fourier变换。**将较于其他模型,Autoformer结构较为复杂,并未加入其他模型(RNN、线性结构),也未改动自注意力机制,而是提出了一种自相关机制和深度分解架构,适合处理长序列和复杂的依赖关系的问题。考虑到原始时序数据中各种趋势信息比较混乱,无法提供有效的时间依赖,和传统的Transformer模型在自注意力计算时的二次复杂度较高的问题。
# 01 论文创新点
Autoformer模型的创新点在原论文标题中有明确体现,“Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting”。“Decomposition”,指的是将传统时序分解可以将原始序列分解为更容易预测、更稳定的内容,由于仅在预处理阶段进行分解无法提取序列的内在依赖,因此将分解模块集成到模型中。“Auto-Correlation”提出了一种新的计算机制,将多头注意力机制的“自注意(self-attention)”对节点的计算转化为计算子序列(sub-series)间的相似度。具体工作如下:
**1、**深度分解架构——从预测的隐藏变量中提取复杂的长期趋势信息
Autoformer仍然沿用残差和编解码器结构,同时由Auto-Correlation、Series Decomp、Feed Forward三个模块组成每一层,为了对复杂的时间模式进行推理,作者尝试采用时序数据预处理中常用的分解的思想,将Transformer改造为分解预测结构,在模型的输入部分先用到Series Decomp Block。
时间序列分解是指将时间序列分解为几个组分,每个组分表示一类潜在的时间模式,如周期项(seasonal),趋势项(trend-cyclical)。由于预测问题中未来的不可知性,通常先对过去序列进行分解,再对每个组分分别预测。但这会造成预测结果受限于分解效果,并且忽视了未来各个组分之间的相互作用。Autoformer突破地将作为预处理传统方法的序列分解加入深度模型,提出的深度分解架构,将序列分解作为一个内部单元,嵌入到深度模型的编-解码器中。在预测过程中,模型交替进行预测结果优化和序列分解,即从隐变量中逐步分离趋势项与周期项,实现渐进式地预测,能够从复杂时间模式中分解出可预测性更强的项。
这种设计允许模型在预测过程中交替进行预测结果优化和序列分解,进而实现两者相互促进。深度分解架构如图1所示。
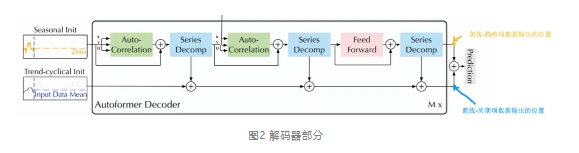
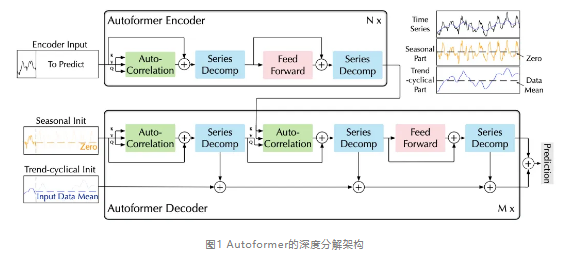 上面表示编码器(Encoder)部分,模型对输入的原始时序数据进行编码;右上角,黑色折线表示原始时序数据(Time Series),黄色线表示周期性数据部分(Seasonal Part),蓝色线表示趋势项部分(Trend-cyclical Part);在解码器部分将周期项初始化传入自相关机制等一些列操作,将趋势项传递给分解模块处理后的结果,得到结果(如下如图所示)并进行加和得到预测结果。
上面表示编码器(Encoder)部分,模型对输入的原始时序数据进行编码;右上角,黑色折线表示原始时序数据(Time Series),黄色线表示周期性数据部分(Seasonal Part),蓝色线表示趋势项部分(Trend-cyclical Part);在解码器部分将周期项初始化传入自相关机制等一些列操作,将趋势项传递给分解模块处理后的结果,得到结果(如下如图所示)并进行加和得到预测结果。
 序列分解单元(series decomposition block)使用传统的decomposition操作,基于滑动平均思想,将序列分解为趋势项和周期项两部分,平滑周期项(反应长期趋势)、突出趋势项(反应短期的波动)。对于长度为L的序列
序列分解单元(series decomposition block)使用传统的decomposition操作,基于滑动平均思想,将序列分解为趋势项和周期项两部分,平滑周期项(反应长期趋势)、突出趋势项(反应短期的波动)。对于长度为L的序列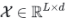 ,做如下处理:
,做如下处理:
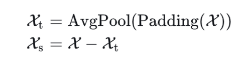
其中, X为待分解的隐变量,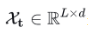 存储着每个滑动窗口的均值,即序列的短期波动,为趋势项,对原输入数据先进行填充然后再进行平均池化;
存储着每个滑动窗口的均值,即序列的短期波动,为趋势项,对原输入数据先进行填充然后再进行平均池化;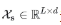 为周期项,是减去短期波动后保留周期性的平滑序列,即原始时序数据减掉趋势项数据。Series Decomp Block可以记为
为周期项,是减去短期波动后保留周期性的平滑序列,即原始时序数据减掉趋势项数据。Series Decomp Block可以记为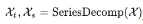 。
。
**编码器:**主要进行周期项建模,逐步消除趋势项,得到周期项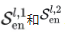 。而基于这种周期性,设计自相关机制,聚合不同周期的相似子过程,假设具有N层编码器,第l层编码层可以总结为
。而基于这种周期性,设计自相关机制,聚合不同周期的相似子过程,假设具有N层编码器,第l层编码层可以总结为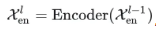 ,每一层处理如下:
,每一层处理如下:

其中,“_”表示消除的趋势部分,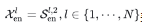 表示第l层编码器的输出,
表示第l层编码器的输出,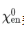 表示经过嵌入的
表示经过嵌入的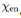 。
。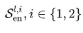 分别表示第l层中经过i个序列分解模块后获得的季节性部分。Auto-Correlation表示自相关性机制,下文对其展开具体介绍。
分别表示第l层中经过i个序列分解模块后获得的季节性部分。Auto-Correlation表示自相关性机制,下文对其展开具体介绍。
解码器: 采用双路处理模式,对趋势项与周期项分别建模,包含趋势周期分量的累积结构和周期性分量的叠加自相关机制成分。上分支处理seasonal part,使用自相关机制AutoCorrelation,基于序列的周期性质来挖掘未来预测状态内的时间依赖,聚合不同周期中具有相似过程的子序列;下分支处理trend-cyclical part,采用带权加法逐步从上分支每一子层预测的隐变量中提取出趋势信息加和。

其中,“_”表示消除的趋势部分,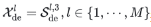 表示第l层解码器的输出,
表示第l层解码器的输出,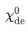 表示经过嵌入的
表示经过嵌入的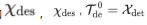 用于加速。
用于加速。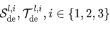 表示分别经过第l层解码层中第i个序列分解模块处理后的季节性部分和趋势循环部分。
表示分别经过第l层解码层中第i个序列分解模块处理后的季节性部分和趋势循环部分。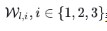 表示第i个提取趋势的
表示第i个提取趋势的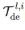 权重。基于上述渐进式分解架构,模型可以在预测过程中逐步分解隐变量,并通过自相关机制、累积的方式分别得到周期、趋势组分的预测结果,实现分解、预测结果优化的交替进行、相互促进。
权重。基于上述渐进式分解架构,模型可以在预测过程中逐步分解隐变量,并通过自相关机制、累积的方式分别得到周期、趋势组分的预测结果,实现分解、预测结果优化的交替进行、相互促进。
2、自相关机制——扩大信息利用效率
不同周期的相似相位之间通常表现出相似的子过程,利用这种序列固有的周期性来设计自相关机制,代替点向连接的注意力机制,实现高效的序列级(series-wise)连接和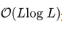 复杂度,打破信息利用瓶颈。其中,包含基于周期的依赖发现(Period-based dependencies)和时延信息聚合(Time delay aggregation)。
复杂度,打破信息利用瓶颈。其中,包含基于周期的依赖发现(Period-based dependencies)和时延信息聚合(Time delay aggregation)。
自相关机制的高效计算:如图所示,自相关机制依然使用query、key、value的多头形式(可以无缝替换自注意力机制),Q、K、V和Transformer一样通过映射输入得到,对Q和K分别执行快速傅里叶变换操作 (FFT),而K还执行了共轭操作。
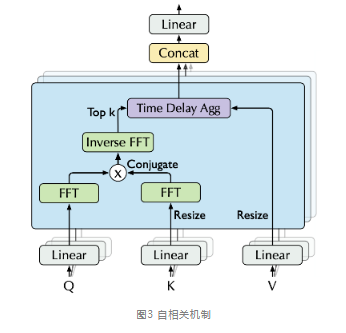
基于周期的依赖发现:周期之间相同的相位位置自然会产生相似的子过程,为找到相似子过程,需要估计序列的周期。Autoformer提出了一种周期依赖(Period-based dependencies)自相关系数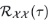 ,对于一个实际离散的时间过程
,对于一个实际离散的时间过程 延迟t个周期的序列
延迟t个周期的序列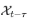 ,基于随机过程理论,可以计算其自相关系数:
,基于随机过程理论,可以计算其自相关系数:
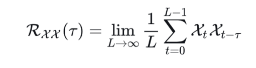
其中,自相关系数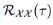 表示离散时间序列
表示离散时间序列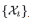 与它的t延迟滞后序列
与它的t延迟滞后序列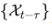 之间的时延相似性,这种时延相似性被看作估计周期长度的非归一化置信度,即周期长度为t的置信度为
之间的时延相似性,这种时延相似性被看作估计周期长度的非归一化置信度,即周期长度为t的置信度为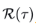 。接着,选择最可能的k个周期长度
。接着,选择最可能的k个周期长度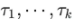 。基于周期的依赖关系由上述估计的周期导出,并可以通过相应的自相关来加权。
。基于周期的依赖关系由上述估计的周期导出,并可以通过相应的自相关来加权。
基于Wiener-Khinchin理论,可以使用快速傅立叶变换(FFT)得到,因此引出对于周期的依赖发现。计算过程如下:

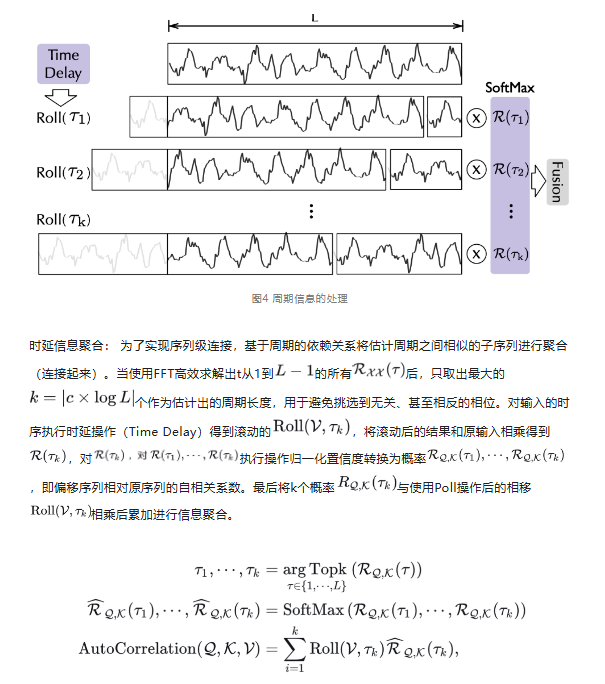
# 02 数据集上的评价指标得分
1、主要实验结果
Autoformer在处理长时间序列问题上表现出色,在涵盖能源、交通、经济、气象、疾病五大领域的6个数据集上进行了模型验证均取得了当时的最优(SOTA)效果。该实验部分来自Autoformer原文的实验。
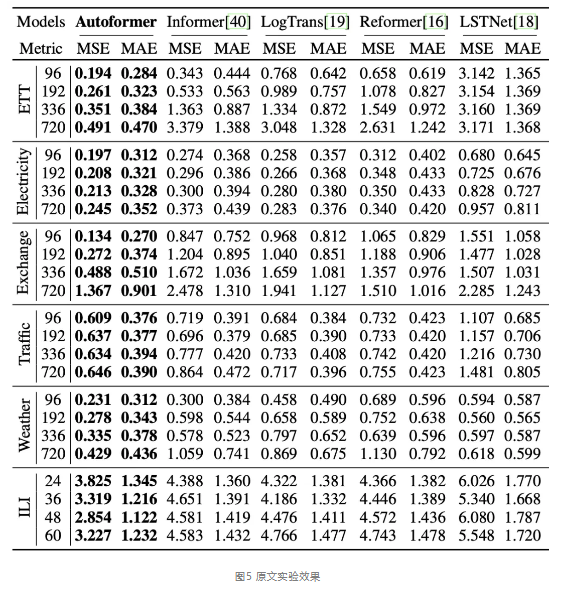 Autoformer在上述的多个领域数据集数据集、各种输入-输出长度的设置下,取得了当时的最优(SOTA)结果。
Autoformer在上述的多个领域数据集数据集、各种输入-输出长度的设置下,取得了当时的最优(SOTA)结果。
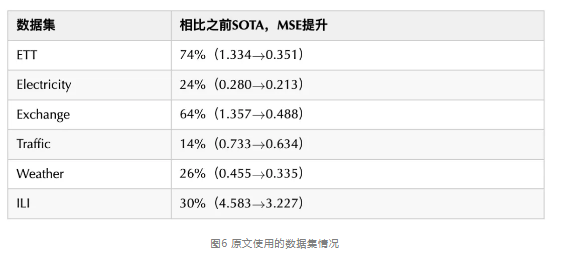
其中,前五个数据集指标为input-96-predict-336设置,ILI数据集为input-24-predict-60设置。相比于之前的SOTA结果,Autoformer实现了ETT能源数据集74%的MSE提升,Electricity能源数据集MSE提升24%,Exchange经济数据集提升64%,Traffic交通数据集提升14%,Weather气象数据集提升26%,在input-24-predict-60设置下,ILI疾病数据集提升30%。在上述6个数据集,Autoformer在MSE指标上平均提升38%。
2、对比实验
深度分解架构的通用性实验部分:
将Autoformer提出的深度分解架构应用于其他Transformer-based模型,均可以得到明显提升,且随着预测时效的延长,效果提升更明显,具有较好通用性。在ETT数据集上的MSE指标对比如表4所示。
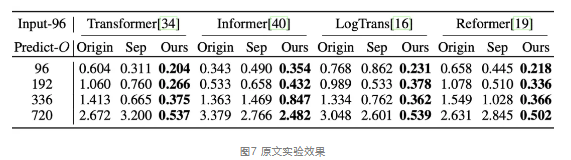
Origin表示直接预测,Sep表示先分解后预测(用模块进行预处理,得到s和t序列分别预测,最后加和),Ours表示深度分解架构。
自相关机制与自注意力机制的对比实验部分:
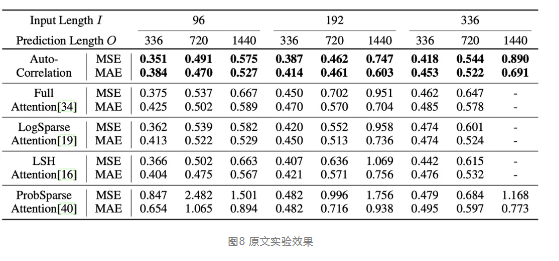
同样基于深度分解架构,在多种输入-输出设置下,对比了自相关机制与经典Transformer中Full Attention、Informer中PropSparse Attention等自注意力机制及其变体,Autoformer中提出的自相关机制依然取得了最优的结果。在ETT数据集上对比实验如表5所示。
# 03 针对MindSpore NLP实现的评估
对于MindSpore NLP的Autoformer实现,我们使用了官方相同的“Traffic”基准来评估Autoformer模型的长时间序列预测性能,输入长度为48,预测长度为24。Traffic描述了道路占用率。它包含 2015 年至 2016 年旧金山高速公路传感器记录的每小时数据。是非常标准的时间序列常用数据集。主要的评价指标包括Univariate-MASE。整个数据加载与模型测试流程均与huggingface中提供的官方样例相同。
本次测试训练集的长度为862,测试集的长度为6034,模型为每个时间序列生成了 100 个不同的预测样本,每个预测样本的预测时间步长为24。根据测试结果,MindNLP实现与官方实现的误差在1%以内。
测试结果如下:
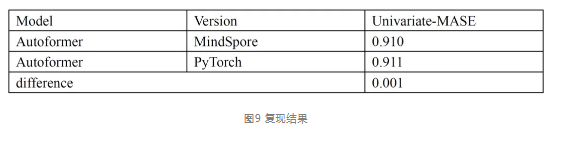
实验结果表明,Autoformer在MindNLP的实现其精度比官方实现还要高,误差均低于1%。
完整推理代码:https://github.com/4everImmortality/autoformer_mindnlp_test
# 04 总结
Autoformer模型凭借深度分解架构和自相关机制在长时序列预测、复杂时间模式难以处理、运算效率高的问题上表现优异,通过渐进式分解和序列级连接,大幅提高了长时预测效率。
建议各位开发者利用MindSpore NLP等工具来加载并复现该模型的实验成果。MindSpore NLP提供了一套与PyTorch风格一致的简洁接口,加载和评估预训练模型非常直接和高效。
参考链接
[1]arXiv:2106.13008v5:
https://arxiv.org/abs/2106.13008v5
[2] Autoformer:基于深度分解架构和自相关机制的长期序列预测模型:
https://zhuanlan.zhihu.com/p/385066440
[3] 革新Transformer!清华大学提出全新Autoformer骨干网络,长时序预测达到SOTA: