BEIT模型论文解读,并基于MindSpore NLP推理复现
BEIT模型论文解读,并基于MindSpore NLP推理复现
作者:四顾
来源:开源实习
昇思MindSpore开源实习模型论文解读任务已顺利完成,共收到高质量模型论文解读稿件10+篇。欢迎开发者积极参与昇思MindSpore开源实习活动,开源实习暑期活动已开启,更多新任务等你来挑战!

开源实习官网
# 01
引言
视觉Transformer在计算机视觉领域中取得了重大突破。然而,相比于卷积神经网络,它们通常需要大量数据才能发挥出最佳性能。为了解决这一问题,微软的研究人员提出一种名为BEiT(Bidirectional Encoder representation from Image Transformers)的自监督视觉表征模型,将自然语言处理的成功经验BERT引入到视觉领域,并取得了不错的效果。
# 02
论文创新点
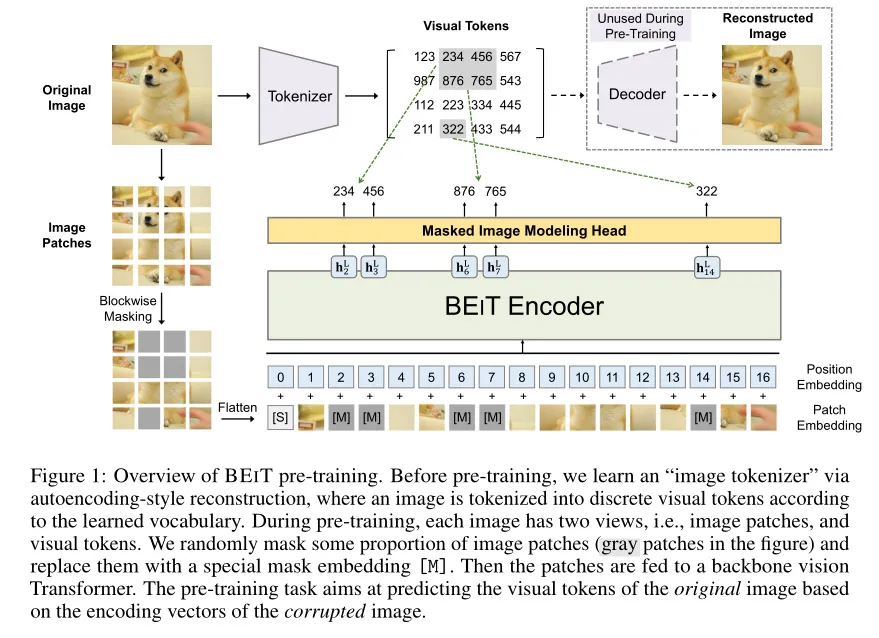
**1、**图像表示
本文中,图像有两个视图的表示,分别是图像块和视觉token。这两种类型分别作为预训练过程中的输入和输出表示。
**图像块:**将二维图像分割成一系列图像块序列,以便标准 Transformer 能够直接接收图像数据。例如,将 224×224 的图像分割成 14×14 的网格,每个图像块为 16×16。
**视觉token:**类似于自然语言中的词,将图像表示为由“图像标记器”获得的离散token序列。视觉token是通过离散变分自编码器(dVAE)学习得到的,每个图像被标记为一系列离散的token,如将 224×224 的图像标记为 14×14 的视觉token网格,使用大小为 8192 的词汇表。
**2、**掩码图像建模 (Masked Image Modeling, MIM)
BEIT模型的核心创新点就是提出了掩码图像建模MIM,是一种自监督学习任务,旨在通过预测图像中被随机掩码遮盖的部分来学习图像的特征表示。具体而言,先将图像分割成图像块(如 16×16 像素)并将其“标记化”为离散的视觉token,然后随机掩码一定比例的图像块,将这些损坏的图像块输入到 Transformer 中,预训练目标是基于损坏的图像块恢复原始的视觉token。
在实际应用过程中,采用块状掩码(blockwise masking)而非随机选择掩码位置。每次掩码一个图像块区域,设置每个块的最小掩码数为 16,然后随机选择掩码块的宽高比,重复此过程直到获得足够的掩码块(如占总图像块的 40%)。这种块状掩码方式有助于模型更好地学习图像的局部结构和全局语义信息。对于每个被掩码的位置,使用 softmax 分类器来预测对应的视觉token。预训练的目标是最大化给定损坏图像下正确视觉token的对数似然。
**3、**预训练和微调
在预训练阶段,BEiT模型使用掩码图像建模任务进行训练,以学习图像的特征表示。在微调阶段,使用预训练模型的权重进行初始化,并使用下游任务的标注数据进行微调。并进行大量实验,验证本文提出的方法的有效性。
# 03
数据集上的评价指标得分
1、图像分类
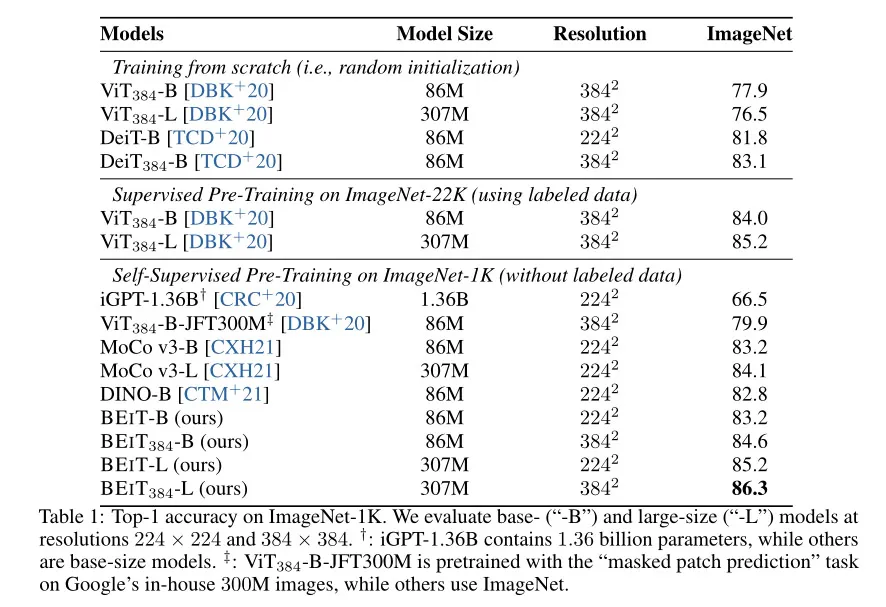
BEiT的预训练在ImageNet-1K数据集上进行,并在下游任务上进行了微调,并使用ImageNet-1K数据集进行了评估。从评估结果中可以看出,BEiT基础模型在224×224分辨率的图像上达到了83.2%的top-1准确率,在384×384分辨率的图像上达到了84.6%的top-1准确率。.参数更多的模型在224×224分辨率的图像上达到了85.2%的top-1准确率,在384×384分辨率的图像上达到了86.3%的top-1准确率。在相同条件下BEiT的效果由于其他模型。
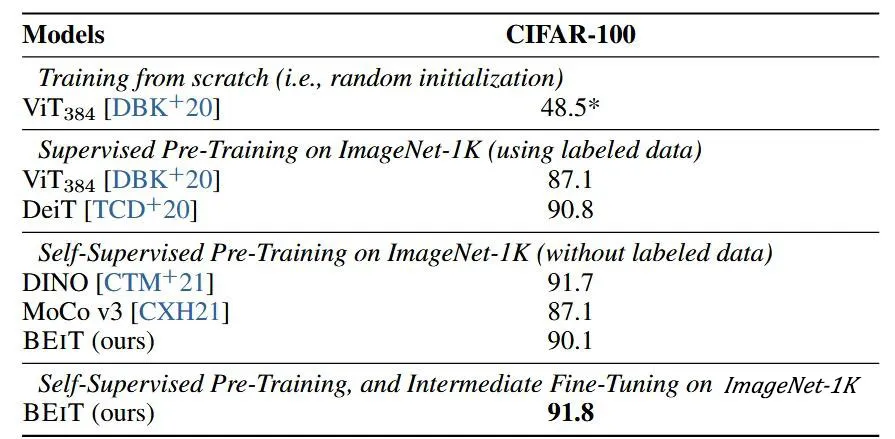
本文也正在CIFAR-100数据集上进行微调和实验评估,微调后推理准确率为91.8%。
2、图像分割
语义分割任务的目标是为输入图像的每个像素预测一个对应的类别,在ADE20K数据集上进行了图像分割任务的评估,该数据集包含 25,000 张图像和 150 个语义类别。同时在该数据集上进行微调和测试。最终测试得分为47.7。

# 04
创新点相比于其他工作的优势
**性能提升:**在图像分类和语义分割等下游任务中,BEiT相较于从头训练和之前的自监督模型取得了更好的性能。例如,在ImageNet数据集上,BEiT-B的top-1准确率达到83.2%,BEIT384-L的准确率达到86.3%,超过了其他自监督方法以及一些监督预训练方法。
**收敛速度和稳定性:**与从头训练相比,BEiT预训练后再微调在训练过程中的收敛速度更快且更稳定。这意味着在实际应用中,使用BEiT可以减少训练时间和资源消耗,同时获得更好的模型性能。
**学习语义区域的能力:**尽管BEiT的预训练过程不使用任何人类标注数据,但其自注意力机制能够学习到区分语义区域和对象边界的能力。这表明BEiT在预训练过程中自动获取了图像的语义信息,从而为下游任务提供了更丰富的特征表示。
**模型扩展性:**对于更大规模的模型,BEiT的优势更加显著。当扩展到大型模型时,BEiT在性能上的提升超过了仅使用监督预训练的大型模型,显示出更好的扩展性。例如,BEIT-L在ImageNet384上的准确率比ViT384-L高1.2%,这表明BEiT的预训练方法对于大规模模型更为有效。
**减少标注数据依赖:**在与监督预训练的比较中发现,BEiT与监督预训练是互补的。通过中间微调,BEiT在使用较少标注数据的情况下能够进一步提升性能,降低了对大规模标注数据的依赖,这对于标注数据获取困难的场景具有重要意义。
# 05
MindSpore NLP推理移植
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
import mindspore as ms
from mindspore import context, Tensor, ops
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
from mindspore.dataset.vision import Inter
from mindnlp.transformers import BeitForImageClassification, BeitImageProcessor
import numpy as np
# Ascend 设备配置
context.set_context(mode=context.GRAPH_MODE, device_target="Ascend")
# 加载模型(float16)
model = BeitForImageClassification.from_pretrained(
pretrained_model_name_or_path='microsoft/beit-large-patch16-224',
num_labels=10,
ignore_mismatched_sizes=True
)
model.set_train(False)
for param in model.get_parameters():
param.set_dtype(ms.float16)
# 图像预处理
processor = BeitImageProcessor.from_pretrained('microsoft/beit-large-patch16-224')
size = processor.size["height"]
transform_ops = [
vision.Resize((size, size), interpolation=Inter.BICUBIC),
vision.Normalize(mean=processor.image_mean, std=processor.image_std),
vision.HWC2CHW(),
lambda x: x.astype(np.float16)
]
# 加载测试集
cifar10_ds = ds.Cifar10Dataset(dataset_dir='./cifar10_data_bin', usage='test', shuffle=False)
cifar10_ds = cifar10_ds.map(operations=transform_ops, input_columns="image", num_parallel_workers=8)
cifar10_ds = cifar10_ds.batch(64, drop_remainder=False)
# 预热模型
_ = model(Tensor(np.random.randn(1, 3, size, size), dtype=ms.float16))
# 推理与准确率计算
total_correct, total_samples = 0, 0
for data in cifar10_ds.create_tuple_iterator():
images, labels = data
logits = model(images).logits
preds = ops.argmax(logits, 1).astype(ms.int64)
labels = labels.astype(ms.int64)
correct = ops.equal(preds, labels).sum().asnumpy()
total_correct += correct
total_samples += images.shape[0]
# 输出准确率
accuracy = total_correct / total_samples
print(f"{accuracy * 100:.2f}%")