开发者说 | 基于昇思MindSpore实现DDPM扩散模型
2025/07/07开发者说
开发者说 | 基于昇思MindSpore实现DDPM扩散模型
作者:Adream
来源:昇思论坛
昇思MindSpore2024年技术帖分享大会圆满结束!全年收获80+高质量技术帖, 2025年全新升级,推出“2025年昇思干货小卖部,你投我就收!”,活动继续每月征集技术帖。本期技术文章由社区开发者Adrem输出并投稿。如果您对活动感兴趣,欢迎在昇思论坛投稿。
# 01
概述
DDPM 是基于扩散过程的生成模型,通过逐步去除图像中的噪声来生成高质量的样本。其核心思想是将数据分布转换为更容易处理的简单高斯噪声分布,然后使用神经网络学习从该噪声分布中恢复原始数据的映射关系并通过优化变分下界简化训练,最终实现对复杂数据分布的建模。
DDPM 的主要特点包括:
- **双向马尔可夫链:**正向过程固定(可解析求解),反向过程参数化(神经网络学习);
- **噪声预测机制:**通过预测正向过程中添加的噪声间接恢复数据,避免显式估计复杂分布;
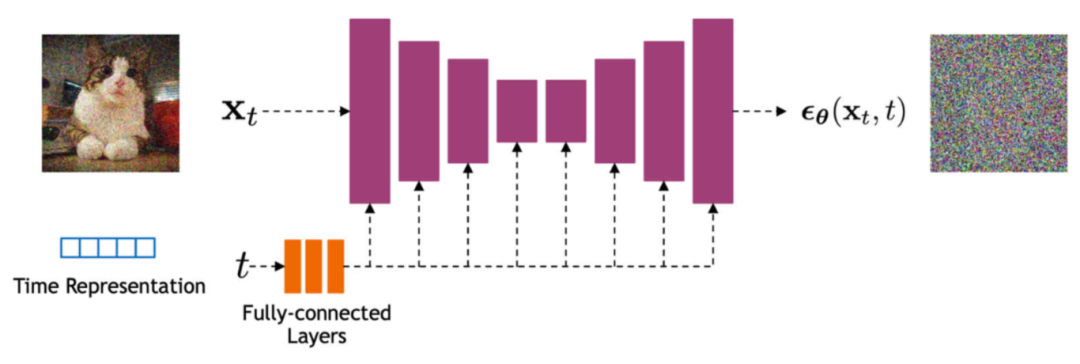
- **U-Net 架构:**利用多尺度特征和跳跃连接捕捉图像细节,结合时间嵌入感知扩散阶段。
# 02
主要步骤
**1、**正向扩散过程


# 03
数学理论
**1、**变分推断框架

# 04
模型结构

**1、**网络架构
- **编码器(下采样):**通过卷积和池化层提取多尺度特征,捕捉图像的全局结构。
- **解码器(上采样):**通过转置卷积和跳跃连接恢复空间分辨率,融合编码器对应尺度的特征,保留细节信息。
- 时间嵌入(Time Embedding): 将时间步 t编码为高维向量(如正弦位置编码或可学习嵌入),通过线性层映射后与各层特征相加或拼接,使模型感知当前扩散阶段。
**2、**关键组件
- **跳跃连接:**直接传递编码器特征到解码器,避免下采样导致的信息丢失,增强细节恢复能力。
- **自注意力机制:**在中等分辨率层级(如 32×32 像素)引入自注意力层,建模长距离依赖关系,提升生成样本的全局一致性。
# 05
MindSpo****re代码实现
import mindspore
from mindspore import nn, ops
import numpy as np
# 时间嵌入模块
class TimestepEmbedding(nn.Cell):
"""将时间步t编码为高维向量"""
def __init__(self, embed_dim=128):
super(TimestepEmbedding, self).__init__()
self.embed_dim = embed_dim
# 使用可学习的Embedding(替代正弦编码,简化实现)
self.time_embed = nn.Embedding(1000, embed_dim) # 假设最大时间步为1000
def construct(self, t):
# 输入t为形状(batch_size,)的整数张量
return self.time_embed(t).view(-1, self.embed_dim, 1, 1) # 扩展为(batch, dim, 1, 1)用于特征融合
# U-Net 模型(含时间嵌入)
class UNet(nn.Cell):
"""带跳跃连接和时间嵌入的U-Net,用于预测噪声ε_θ(x_t, t)"""
def __init__(self, in_channels=1, out_channels=1, time_embed_dim=128):
super(UNet, self).__init__()
self.time_embedding = TimestepEmbedding(time_embed_dim)
# 编码器(下采样路径)
self.enc_conv1 = nn.Conv2d(in_channels, 64, 3, padding=1, pad_mode='pad')
self.enc_conv2 = nn.Conv2d(64, 64, 3, padding=1, pad_mode='pad')
self.enc_pool = nn.MaxPool2d(2)
self.enc_conv3 = nn.Conv2d(64, 128, 3, padding=1, pad_mode='pad')
self.enc_conv4 = nn.Conv2d(128, 128, 3, padding=1, pad_mode='pad')
# 解码器(上采样路径)
self.dec_transconv1 = nn.Conv2dTranspose(128, 64, 2, stride=2) # 上采样到编码器第一层尺度
self.dec_conv1 = nn.SequentialCell(
nn.Conv2d(128, 64, 3, padding=1, pad_mode='pad'), # 拼接后通道数64+64=128→64
nn.ReLU()
)
self.dec_transconv2 = nn.Conv2dTranspose(64, 32, 2, stride=2) # 上采样到输入尺度
self.dec_conv2 = nn.SequentialCell(
nn.Conv2d(33, 32, 3, padding=1, pad_mode='pad'), # 输入通道数:32(上采样)+1(输入x)=33→32
nn.ReLU()
)
self.final_conv = nn.Conv2d(32, out_channels, 3, padding=1, pad_mode='pad') # 输出噪声预测
self.relu = nn.ReLU()
def construct(self, x, t):
# 时间嵌入
t_emb = self.time_embedding(t)
# 编码器前向传播
h1 = self.relu(self.enc_conv1(x))
h1 = self.relu(self.enc_conv2(h1)) # (batch, 64, H, W)
h1_pool = self.enc_pool(h1) # (batch, 64, H/2, W/2)
h2 = self.relu(self.enc_conv3(h1_pool))
h2 = self.relu(self.enc_conv4(h2)) # (batch, 128, H/4, W/4)
# 解码器反向传播
h3 = self.dec_transconv1(h2) # (batch, 64, H/2, W/2)
h3 = ops.concat((h3, h1), axis=1) # 跳跃连接:拼接编码器同尺度特征(64+64=128通道)
h3 = self.dec_conv1(h3) # (batch, 64, H/2, W/2)
h4 = self.dec_transconv2(h3) # (batch, 32, H, W)
h4 = ops.concat((h4, x), axis=1) # 拼接原始输入x(示例简化,实际应匹配尺度,此处假设输入为单通道)
h4 = self.dec_conv2(h4) # (batch, 32, H, W)
out = self.final_conv(h4) # 输出预测噪声,形状与输入x一致
return out
# DDPM 模型主体
class DDPM(nn.Cell):
"""DDPM主类,管理扩散过程和损失计算"""
def __init__(self, unet, num_timesteps=1000, beta_start=0.0001, beta_end=0.02):
super(DDPM, self).__init__()
self.unet = unet
self.num_timesteps = num_timesteps
# 计算扩散参数(使用MindSpore张量,支持自动微分)
self.betas = mindspore.Tensor(
np.linspace(beta_start, beta_end, num_timesteps, dtype=np.float32)
)
self.alphas = 1. - self.betas
self.alphas_cumprod = ops.cumprod(self.alphas, 0) # 累积乘积,形状(num_timesteps,)
self.sqrt_alphas_cumprod = ops.sqrt(self.alphas_cumprod)
self.sqrt_one_minus_alphas_cumprod = ops.sqrt(1. - self.alphas_cumprod)
def q_sample(self, x_start, t):
"""根据正向过程生成x_t = sqrt(α_t^bar)x0 + sqrt(1-α_t^bar)ε"""
sqrt_alpha_prod = ops.gather(self.sqrt_alphas_cumprod, t, 0) # 提取批次对应的α累积根
sqrt_one_minus_alpha_prod = ops.gather(self.sqrt_one_minus_alphas_cumprod, t, 0)
noise = ops.randn_like(x_start) # 生成随机噪声
return (sqrt_alpha_prod.view(-1, 1, 1, 1) * x_start +
sqrt_one_minus_alpha_prod.view(-1, 1, 1, 1) * noise)
def p_losses(self, x_start, t):
"""计算噪声预测损失:MSE(ε_θ(x_t, t), ε)"""
noise = ops.randn_like(x_start) # 真实噪声ε
x_noisy = self.q_sample(x_start, t) # 生成含噪数据x_t
predicted_noise = self.unet(x_noisy, t) # 模型预测噪声
return nn.MSELoss()(predicted_noise, noise)
def construct(self, x):
"""训练时的前向传播:随机采样时间步t,计算损失"""
batch_size = x.shape[0]
t = ops.randint(0, self.num_timesteps, (batch_size,), dtype=mindspore.int32)
return self.p_losses(x, t)
参考链接
[1] 论文地址:https://arxiv.org/pdf/2006.11239