昇思MindSpore论文 | 一种用于文本分类的双向上下文感知测试时学习方法
昇思MindSpore论文 | 一种用于文本分类的双向上下文感知测试时学习方法
论文标题
A Dual-Directional Context-Aware Test-Time Learning for Text Classification
论文来源
arXiv
论文链接
https://arxiv.org/abs/2503.15469
代码链接
https://github.com/Bearisbug/Bi-Elman
昇思MindSpore作为开源的AI框架,为开发人员带来端边云全场景协同、极简开发、极致性能的体验,支持国内高校/科研机构发表1700+篇AI顶会论文。为鼓励基于昇思MindSpore进行创新,昇思开源社区转载、解读系列arXiv论文,本文为昇思MindSpore AI arXiv论文系列第9篇。
作者:徐东
感谢各位专家教授与同学的投稿,更多精彩的论文精读文章和开源代码实现请访问Models。更多内容请访问: https://gitee.com/mindspore/community/issues/I9W2Z3

研究背景
文本分类作为自然语言处理中的核心任务,广泛应用于舆情分析、新闻推荐、智能问答等领域,具有重要的研究与应用价值。传统方法如朴素贝叶斯(Naïve Bayes)和支持向量机(SVM)通过统计特征进行分类,虽然实现简单,但在处理语义依赖、长距离上下文时表现有限。深度学习方法则利用循环神经网络(RNN)、长短时记忆网络(LSTM)以及近年来广泛应用的Transformer架构显著提升了模型的上下文建模能力,在多个基准任务中取得了领先性能。
然而,尽管这些模型在准确率上不断突破,但在模型可解释性、计算效率与上下文感知能力之间仍存在权衡,如何实现高效、可部署的上下文感知文本分类仍是一个尚未被充分探索的方向。一方面,Transformer 模型虽然具备强大的特征提取能力,但其自注意力机制带来的高计算复杂度限制了其在资源受限环境中的应用;另一方面,传统双向RNN结构如Bi-Elman网络在建模效率与双向语义融合方面尚有不足,且缺乏动态特征选择能力,难以应对真实场景下的高噪声与长序列输入。
针对上述挑战,本文提出了一种动态双向上下文感知的测试时学习方法——Dynamic Bidirectional Elman Attention Network(DBEAN),用于在资源受限场景下实现高效、准确的文本分类。该方法结合了双向Elman循环网络的结构优势与轻量级自注意力机制的动态建模能力,在保持参数效率的同时提升了语义表达的精度和可解释性。依托MindSpore深度学习框架提供的动态图机制与高效的Ascend算子支持,DBEAN能够在推理阶段执行低开销的测试时更新策略,进一步增强模型对输入样本的适应性。该方法在多个主流数据集上超过现有主流方法,体现出融合建模、轻量执行和平台适配的综合优势。
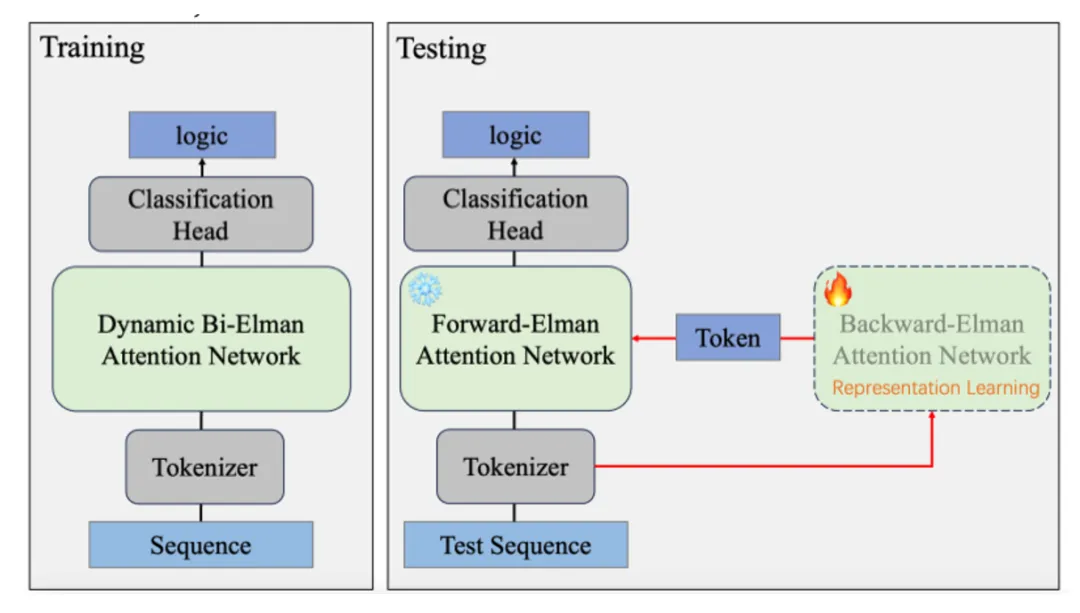
图 1 DBEAN的框架图
作者介绍
论文第一作者徐东,研究兴趣为Ai for science与大模型,发表中科院一区一篇,CCF C一篇,熟悉深度学习,曾获学术科技竞赛国家级奖项6项,省级奖项10项。
论文第二作者廖梦瑶,曾任华为智能基座高校社团副社长,研究方向为大模型安全和智能体开发。
论文第三作者赖正麟,热爱游玩 Minecraft ,熟悉基本编程。
论文简介
在文本分类任务中,情感分类是一项应用广泛且技术挑战突出的分支,常用于社交媒体分析、产品评论识别与用户反馈理解等场景。然而,情感分类面临两个关键难题:一是复杂句法结构带来的上下文依赖建模困难,尤其是长句或包含反转情绪的句子;二是模型可解释性与计算效率之间的性能权衡问题。传统的朴素贝叶斯、支持向量机等方法无法捕捉上下文语义,导致在复杂表达中表现不稳定。尽管近年来基于深度学习的 LSTM 和 Transformer 模型显著提升了分类精度,但它们计算资源消耗大、推理速度慢,且难以解释模型为何做出某一预测,这些都限制了它们在情感分类的实际部署,尤其是在移动端和边缘设备上。
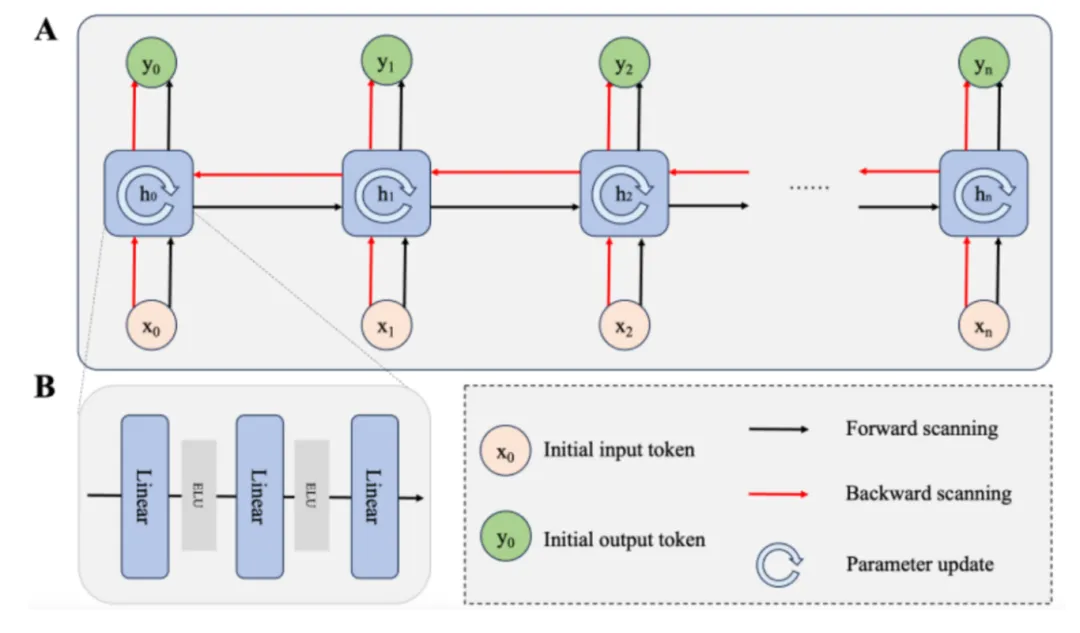
图 2 DBEAN的流程图
针对当前情感分类任务中建模深度不足与计算资源受限之间的矛盾,本文从底层机制出发,对双向循环建模与注意力机制进行了结构层级的重新整合与优化。传统的双向 RNN 虽然具备双向语义提取能力,但它们的特征融合策略通常是静态的,无法根据任务需求动态调整信息权重,容易在长文本中掩盖关键情感片段。另一方面,完整的 Transformer 虽然引入了自注意力机制,但其高昂的计算代价与参数规模,限制了在轻量化部署场景中的应用。本文认为,这两类方法在结构上仍存在融合空白:即缺乏一种既能保留序列建模特性,又具备动态上下文重构能力、同时保持计算效率的统一架构。因此,我们从 Elman 网络出发,提出一种结构简洁、表达灵活的全新路径,突破了以往循环与注意力“松散对接”的技术瓶颈。
为融合上下文建模与动态特征聚焦能力,本文提出了动态双向 Elman 注意力网络(DBEAN),在轻量计算下提升情感识别表现。模型首先通过共享权重的双向 Elman 网络提取前后时序信息,再通过融合层整合双向语义。随后引入轻量级自注意力机制,对融合表示进行动态加权,突出情感相关的关键信息。如图2所示,DBEAN 包含输入编码、双向建模、注意力加权和分类输出四个模块,整体结构紧凑高效。该设计在保持模型可部署性的同时,增强了对语义反转与情感细节的适应能力。
实验结果
为了验证所提出的 DBEAN 方法在文本分类任务中的性能,我们基于国产深度学习框架 MindSpore 搭建模型,在公开数据集 AG News 上进行了实验。AG News 是一个典型的新闻文本分类数据集,共包含四个主题类别:World(国际)、Sports(体育)、Business(商业)和 Sci/Tech(科技)。实验使用的MindSpore框架版本为 2.4.0,具备良好的动态图支持和国产硬件适配能力。
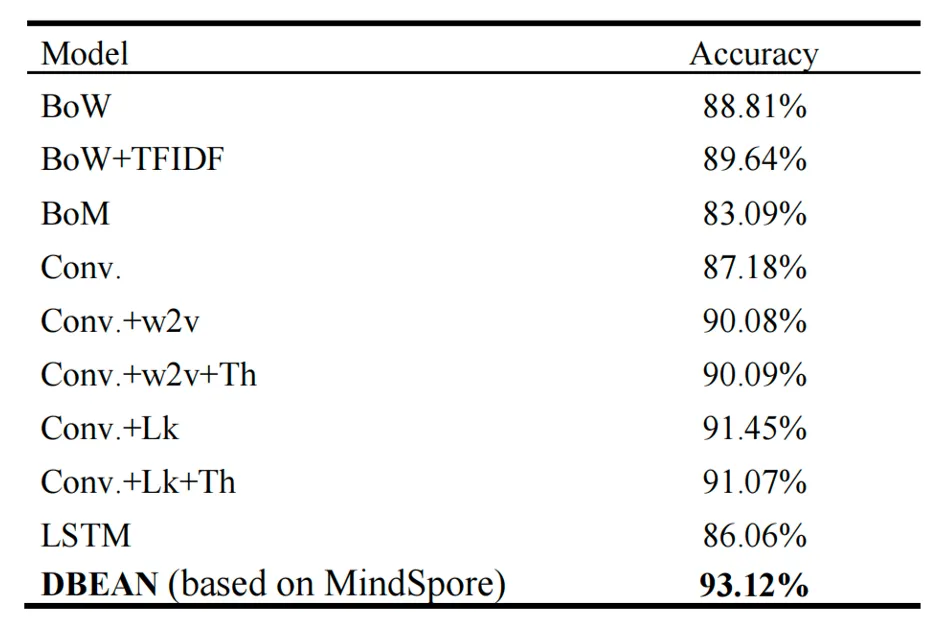
表 1 DBEAN与经典方法的对比
从表1 可以看出,传统方法(如 BoW 和 TF-IDF)虽然结构简单,但性能受限,准确率均低于 90%。卷积模型和 LSTM 在引入预训练词向量后略有提升,但仍不及 DBEAN。在相似计算资源下,DBEAN 凭借自适应注意力机制和双向建模策略,准确率达到 93.12%,相较最优卷积基线提升了 1.67 个百分点,充分体现了其在特征选择与上下文建模方面的优势。
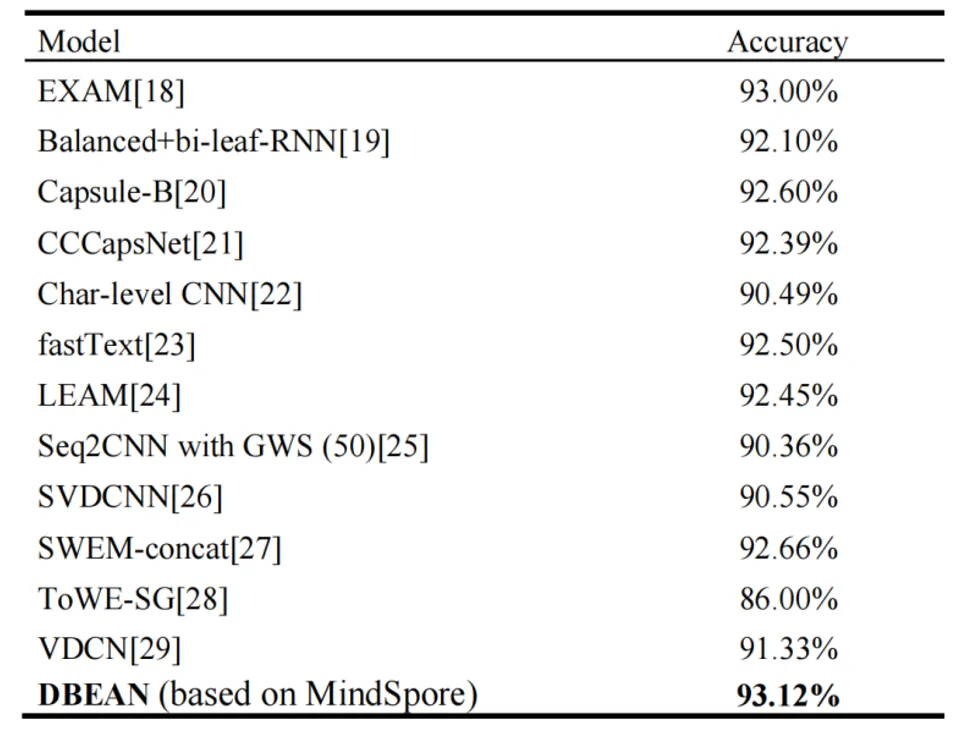
表 2 DBEAN与与参数量相当的当前最佳(SOTA)方法的对比
表2 进一步对比了多个参数规模相当的先进模型。尽管如 EXAM、fastText 等方法已具备较高精度,但它们大多依赖静态结构或复杂计算模块,难以兼顾效率与适应性。DBEAN 在保留表达能力的同时,通过结构简洁的 Elman 网络与线性复杂度注意力模块,有效提升了模型的泛化能力与部署灵活性,显示出良好的实用价值和扩展潜力。
总结与展望
本文提出的 DBEAN 模型有效解决了传统文本分类方法在上下文建模不足与计算效率低下之间的矛盾,实现了准确性与部署效率的平衡。借助 MindSpore 深度学习框架的强大支持,DBEAN 在运行速度与功耗开销方面具备明显优势;此外,MindSpore 对动态图机制与昇腾AI硬件的良好适配,为模型的实时推理与边缘部署提供了坚实基础。