开发者说 | 基于昇思MindSpore实现CFG扩散模型
开发者说 | 基于昇思MindSpore实现CFG扩散模型
作者:Adream
来源:昇思论坛
昇思MindSpore2024年技术帖分享大会圆满结束!全年收获80+高质量技术帖, 2025年全新升级,推出“2025年昇思干货小卖部,你投我就收!”,活动继续每月征集技术帖。本期技术文章由社区开发者Adrem输出并投稿。如果您对活动感兴趣,欢迎在昇思论坛投稿。
# 01
概述
Classifier-Free Guidance(无分类器引导,简称 CFG) 是谷歌于 2022 年提出的扩散模型优化技术,旨在增强生成样本的质量与条件契合度。该方法通过联合训练无条件与有条件生成模型,避免了传统Classifier Guidance中显式分类器的依赖,无需额外训练噪声图像分类器。推理阶段,通过线性组合两种生成模式的预测结果,实现灵活的条件引导,显著提升文本生成图像、图像修复等任务的性能。值得强调的是,CFG 是一种推理优化技术,不改变模型训练目标。本文将详细讲述CFG的原理及如何用昇思MindSpore实现它,并附上代码。
Classifier-Free Guidance 的主要特点包括:
1、**无分类器依赖:**无需额外训练和维护分类器,减少了模型复杂性和计算资源消耗。
2、**联合训练策略:**通过随机丢弃条件信息,使同一网络同时学习无条件与有条件生成;
3、**灵活的引导强度:**引入引导强度超参数 $w$,可灵活调节生成结果对条件的依赖程度。
# 02
主要步骤
CFG的实现分为训练阶段与推理阶段,通过巧妙的参数共享与结果融合达成高效引导。
1、训练阶段
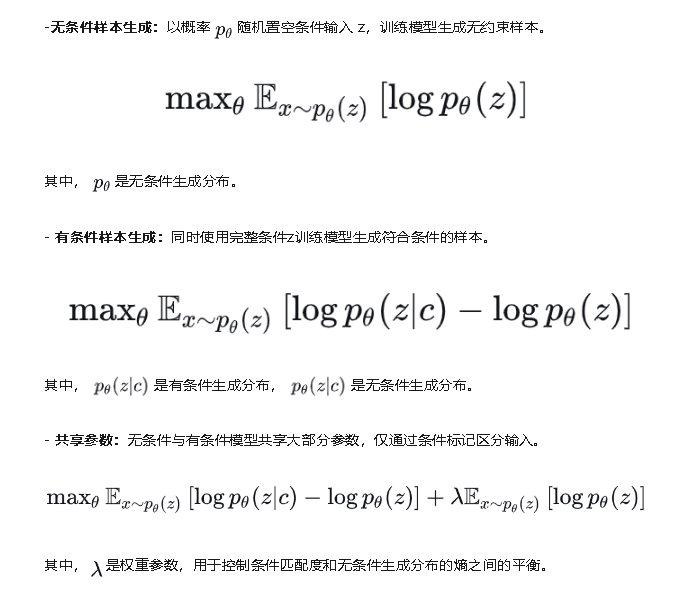

- w=1:标准条件生成(如文本对齐图像)。
- w>1:增强条件契合度(如更鲜艳的颜色)。
- w<1:提升多样性(如抽象艺术风格)。
3、联合训练范式
**随机条件丢弃:**训练时以50%概率随机屏蔽条件输入,强制模型学习数据分布的共性与条件特化;
**参数共享:**无条件与有条件生成共享U-Net网络参数,仅通过条件标记区分输入,避免冗余训练。
# 04
模型结构
Classifier-Free Guidance 通常基于DDPM、DDIM等扩散模型,核心设计围绕共享架构与双路径训练展开:
1、共享网络架构
模型共享UNet结构,通过条件标记区分输入,负责预测噪声或数据分布梯度。
使用Transformer或Embedding层将条件信息(如文本、标签)编码为向量,与时间步嵌入融合后输入网络。
2、双路径训练机制
在条件训练路径中,输入条件编码与噪声图像,再训练模型预测条件去噪目标。
在无条件训练路径中,会以一定概率丢弃条件信息,训练模型预测无条件去噪目标。此设计使模型同时学习条件依赖与无条件生成能力。
3、线性插值策略
在推理阶段,通过超参数w对无条件预测与有条件预测进行线性组合,实现逼真性与多样性的权衡引导。
当w=0时,仅生成无条件预测;当w=1时,仅生成有条件预测;当w>1时,增强条件匹配度;当w<1时,提升生成多样性。
# 05
MindSpo****re代码实现
import mindspore as ms
from mindspore import nn, ops, Tensor
import numpy as np
# 设置随机种子确保可重复性
ms.set_seed(42)
# 定义U-Net扩散模型
class UNet(nn.Cell):
def __init__(self, in_channels=3, out_channels=3, channels=128, time_dim=256):
super().__init__()
# 时间步嵌入
self.time_mlp = nn.SequentialCell(
nn.Dense(time_dim, time_dim * 2),
nn.SiLU(),
nn.Dense(time_dim * 2, time_dim)
)
# 编码器
self.enc1 = nn.SequentialCell(
nn.Conv2d(in_channels + time_dim, channels, 3, padding=1),
nn.GroupNorm(4, channels),
nn.SiLU()
)
self.enc2 = nn.SequentialCell(
nn.Conv2d(channels, channels * 2, 3, padding=1, stride=2),
nn.GroupNorm(8, channels * 2),
nn.SiLU()
)
# 中间层
self.mid = nn.SequentialCell(
nn.Conv2d(channels * 2, channels * 2, 3, padding=1),
nn.GroupNorm(8, channels * 2),
nn.SiLU()
)
# 解码器
self.dec1 = nn.SequentialCell(
nn.Conv2dTranspose(channels * 2, channels, 3, padding=1, stride=2),
nn.GroupNorm(4, channels),
nn.SiLU()
)
self.dec2 = nn.SequentialCell(
nn.Conv2d(channels + time_dim, channels, 3, padding=1),
nn.GroupNorm(4, channels),
nn.SiLU()
)
self.final_conv = nn.Conv2d(channels, out_channels, 3, padding=1)
def construct(self, x, t):
# 时间步嵌入
t_emb = self.time_mlp(t)
t_emb = ops.tile(t_emb.unsqueeze(1).unsqueeze(2), (1, x.shape[1], x.shape[2], 1)).transpose(0, 3, 1, 2)
# 编码
x = ops.concat([x, t_emb], axis=1)
x = self.enc1(x)
x = self.enc2(x)
# 中间层
x = self.mid(x)
# 解码
x = self.dec1(x)
x = ops.concat([x, t_emb], axis=1)
x = self.dec2(x)
# 输出噪声预测
return self.final_conv(x)
# 定义Classifier-Free Guidance训练器
class CFGDiffusion(nn.Cell):
def __init__(self, model, guidance_scale=5.0):
super().__init__()
self.model = model
self.guidance_scale = guidance_scale
self.loss_fn = nn.MSELoss()
self.beta_schedule = self._linear_beta_schedule(timesteps=1000)
self.alpha_cumprod = np.cumprod(1 - self.beta_schedule)
def _linear_beta_schedule(self, timesteps):
beta_start = 1e-4
beta_end = 0.02
return np.linspace(beta_start, beta_end, timesteps)
def construct(self, x0, t, noise=None, y=None):
# 添加噪声
if noise is None:
noise = ops.randn_like(x0)
# 前向过程
sqrt_alpha_cumprod = ops.sqrt(Tensor(self.alpha_cumprod[t], ms.float32))
sqrt_one_minus_alpha_cumprod = ops.sqrt(1 - Tensor(self.alpha_cumprod[t], ms.float32))
xt = sqrt_alpha_cumprod * x0 + sqrt_one_minus_alpha_cumprod * noise
# 条件丢弃(50%概率)
if y is not None and ops.rand(1) > 0.5:
y = None
# 预测噪声
if y is None:
pred_noise = self.model(xt, t)
else:
pred_noise_cond = self.model(xt, t)
pred_noise_uncond = self.model(xt, t) # 无条件路径复用模型
pred_noise = pred_noise_uncond + self.guidance_scale * (pred_noise_cond - pred_noise_uncond)
# 计算损失
loss = self.loss_fn(pred_noise, noise)
return loss
参考链接
[1] 论文地址:https://arxiv.org/pdf/2207.12598