昇思MindSpore原生论文 | 基于GRPO的图像描述算法
昇思MindSpore原生论文 | 基于GRPO的图像描述算法
论文标题
Group Relative Policy Optimization for Image Captioning
论文来源
arXiv
论文链接
https://arxiv.org/abs/2503.01333
代码链接
https://github.com/mindspore-lab/models/tree/master/research/arxiv\_papers/Image\_Caption\_GRPO
昇思MindSpore作为开源的AI框架,为开发人员带来端边云全场景协同、极简开发、极致性能的体验,支持国内高校/科研机构发表1700+篇AI顶会论文。为鼓励基于昇思MindSpore进行原生创新,昇思开源社区转载、解读系列原生arXiv论文,本文为昇思MindSpore AI arXiv论文系列第7篇。
作者:梁旭
感谢各位专家教授与同学的投稿,更多精彩的论文精读文章和开源代码实现请访问Models。更多内容请访问: https://gitee.com/mindspore/community/issues/I9W2Z3

研究背景
图像描述是结合计算机视觉与自然语言处理的多模态任务,旨在为图像生成自然语言描述。图像描述方法受机器翻译的启发,采用编码器-解码器架构。早期方法使用CNN(如ResNet)编码图像特征,使用LSTM自回归解码,但由于LSTM的顺序性限制了并行效率。随着Transformer在NLP的成功,其自注意力机制支持并行训练,现已成为解码器主流。目前图像描述算法的训练通常分两阶段,首阶段使用交叉熵损失,第二阶段采用SCST强化学习方法解决暴露偏差问题(训练与测试输入不一致)。
但SCST算法目前存在一定的局限性,其仅依赖单一贪心解码作为基线,可能导致优势估计方差高,并且仅参考贪心解码,生成多样性受限,而缺乏KL散度的约束也容易导致训练崩溃。
为了解决上述问题,本研究提出了一种基于GRPO强化学习的图像描述方法,利用MindSpore框架,为输入图像生成多个候选描述,计算每个描述的组内优势,结合KL散度,在保证准确性和稳定性的同时不断优化模型。
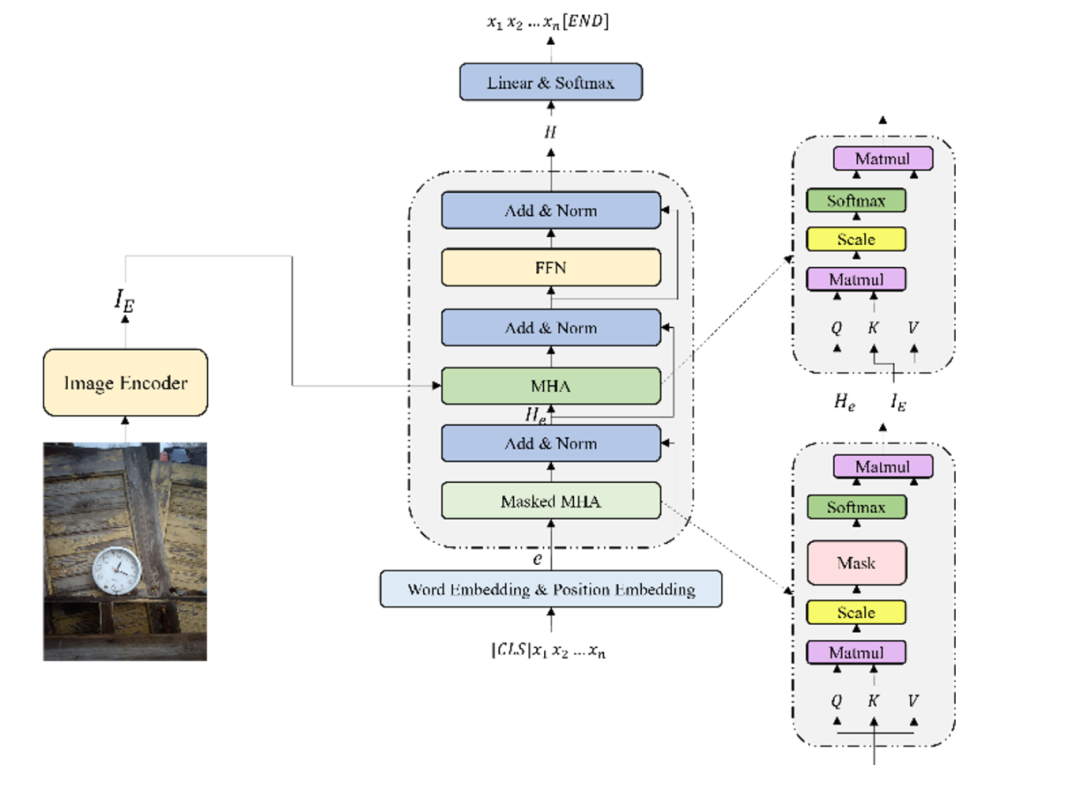
图1 模型结构
作者介绍
论文第一作者梁旭,2020年获得北京邮电大学学士学位,目前是西安交通大学软件工程学院的硕士研究生,其研究成果在Neurocomputing与Computer Vision and Image Understanding等期刊上发表,熟练掌握MindSpore和PyTorch深度学习框架。
论文简介
在计算机视觉领域,图像描述技术近年来受到越来越多的关注。图像描述的目标即使用深度学习、自然语言处理与计算机视觉等多个领域的知识和技术,为图片生成一句准确且流畅的文本描述。因此图像描述技术是一个典型的跨模态任务,其需要考虑模态之间的语义对齐。现有的图像描述方法通常采用编码器-解码器架构,并结合两阶段训练完成模型的训练,其中第一阶段采用交叉熵优化,第二阶段采用强化学习优化。目前图像描述在第二阶段采用的SCTS对模型完成优化,SCST的算法流程如下:对同一图像,模型生成两个句子:采样句子(Sampled Caption):通过随机采样生成。贪心句子(Greedy Caption):通过贪心搜索(每一步取概率最高的词)生成。然后计算两者的奖励值(通常采用CIDEr分数)。接下来计算其优势函数,优势函数定义为采样句子的奖励与贪心句子奖励的差值。最后通过最大化优势函数的期望更新模型参数:
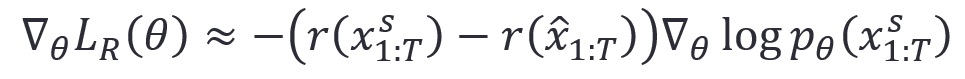

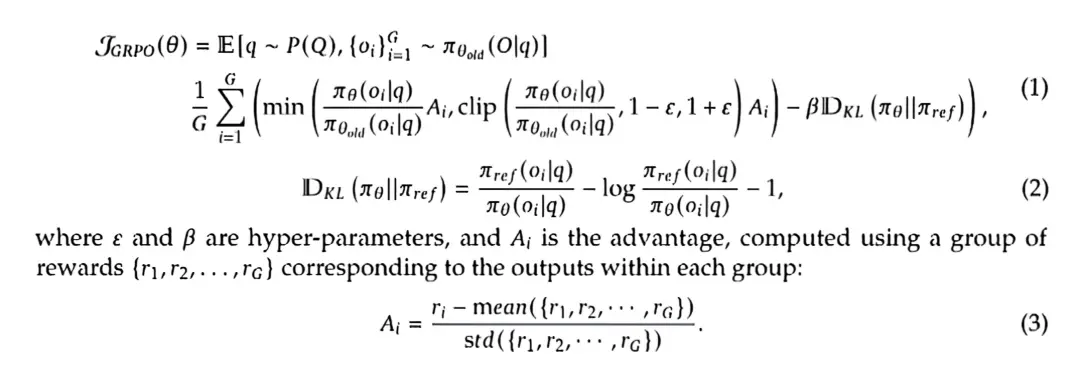
图 2 GRPO计算公式
可以看到GRPO的核心思想是通过对输入提示生成多个候选答案,然后通过组内对比的方式,不断优化模型,并且通过约束策略更新的幅度与KL散度,极大的保证了模型在训练过程中的稳定性。因此GRPO算法非常适用于图像描述领域。GRPO通过组内对比,即使整体奖励稀疏,模型仍能通过组内差异学习优化方向。例如,在生成错误描述较多的组中,相对优势可有效区分部分正确与完全错误的输出,最大限度的保证模型朝着正确的方向优化。此外相比于SCST仅采样一个答案,GRPO采样多组答案,组内多候选生成覆盖更广的解空间,结合KL散度约束,GRPO能在保证流畅性的同时提升多样性。
实验结果
为了验证GRPO方法的性能,我们基于MindSpore框架,使用预先训练好的 ResNet50作为图像编码器,在MSCOCO2014数据集上进行了实验。MSCOCO2014数据集是图像描述中经常使用的数据集,其包含了丰富多样的图像和与之相关联的自然语言描述,共包含123287 张图像,其中 82783 张图片被划分到训练集,40504 被划分为验证集,每张图片有5个参考描述,涵盖了多种场景和主题,包括人物、动物、自然风景、室内环境等。在实际实验中,采用了“Karpathy”重新划分的数据集,其中113287张图像用于训练,5000张图像用于验证,5000张图像用于离线评估,这与目前的研究方法保持一致。其结果如表1所示。实验表明,GRPO在所有指标上都超过了SCST,这验证了我们方法的有效性。
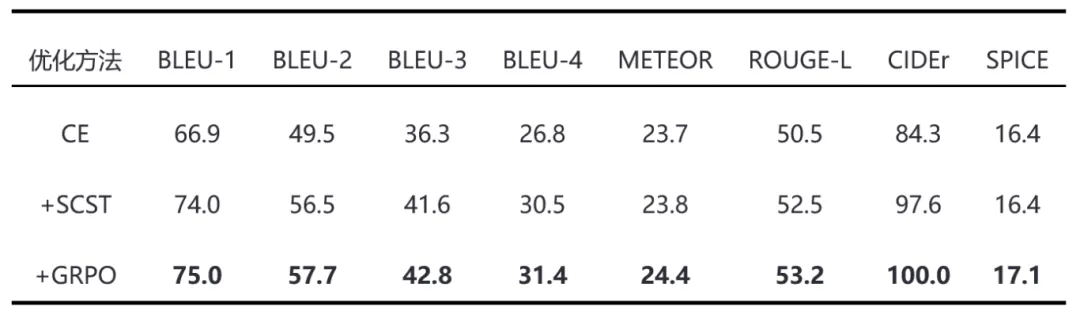
表 1基于 MindSpore 2.2.14 框架的 MSCOCO“Karpathy”拆分测试集上的实验结果。
此外,为了验证SCST和GRPO算法的稳定性,我们使用Flickr8k数据集进行了实验。Flickr8k包含8,000张图像,其中6,000张用于训练,1,000张用于验证,1,000张用于测试。每张图片还有5个关联的标题。由于数据集仅包含少量图像,因此交叉熵优化后的模型能力可能会略弱。实验结果如表2所示。可以看出,GRPO在所有指标上都有所提高,而SCST在某些指标上有所下降。此外,在实验中,我们还发现SCST算法偶尔会崩溃,即验证集指标突然急剧下降,而GRPO算法非常稳定。即使基线模型稍弱,GRPO仍然可以稳步提升模型的性能,这也验证了它的稳定性。
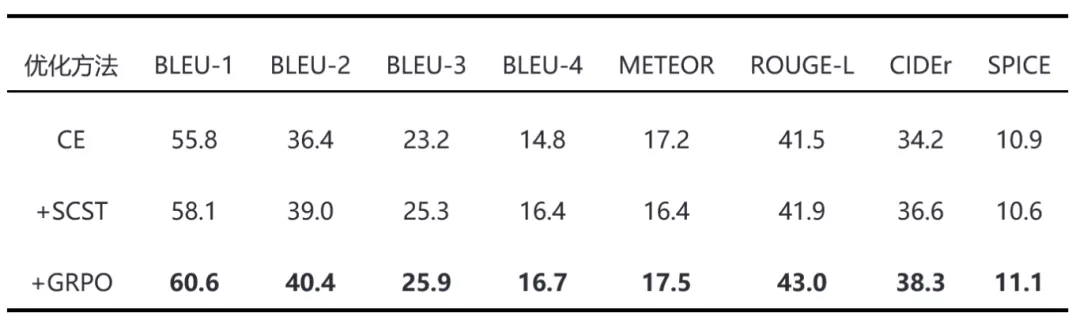
表 2 基于 MindSpore 2.2.14 框架在 Flickr8k 测试数据集上的实验结果。
总结与展望
本文在MindSpore的支持下,提出了一种基于GRPO强化学习的图像描述算法,该算法通过分组优化和KL散度约束解决了传统SCST的局限性。通过为每个图像生成多个候选描述并通过组内比较优化其相对质量,GRPO实现了更好的探索-开发权衡。KL散度约束有效防止了模型崩溃,大大提高了模型的稳定性。在MSCOCO2014和Flickr8k数据集上的实验结果表明,GRPO算法能够稳定高效地提高模型的能力。