扩散模型系列——LDM
扩散模型系列——LDM
LDM
论文地址:High-Resolution Image Synthesis with Latent Diffusion Models
代码地址:https://github.com/CompVis/latent-diffusion
一、概述
LDM(Latent Diffusion Model)是一种基于扩散过程的先进生成模型,其核心思想是通过逐步去除图像中的噪声来生成高质量的图像样本。与传统扩散模型不同,LDM 引入了潜在空间的概念,将图像表示为潜在空间中的向量。通过学习潜在空间中的映射关系,结合预训练好的变分自编码器(VAE),实现高效的图像生成。由于 LDM 在潜在空间进行操作,特征维度远小于图像空间,因此推理速度相较于基于 DDPM 的模型有显著提升。
LDM 的主要特点包括:
- VAE 潜在表示学习:利用 VAE 学习图像的潜在表示,在压缩数据的同时保留关键特征,为后续的扩散过程提供低维高效的输入。
- UNet 映射学习:采用 UNet 架构学习从潜在空间到图像空间的映射关系,充分利用 UNet 的多尺度特征提取和重建能力。
- 条件扩散生成:支持条件扩散过程,能够根据给定的条件(如文本、图像等)生成特定类型的图像,增强了模型的可控性。
- 分层扩散机制:运用分层扩散过程,在不同的分辨率层级上进行图像生成,有助于生成高分辨率、细节丰富的图像。
二、主要步骤
1. 数据编码
使用预训练的 VAE 编码器将原始高维图像数据映射到低维潜在空间。这一过程不仅降低了计算复杂度,还提取了图像的关键特征,为后续的扩散过程提供了更紧凑的表示。
2. 潜在空间扩散
在潜在空间中执行与 DDPM 类似的扩散过程。通过逐步向潜在表示添加高斯噪声,将其从原始数据分布转化为纯噪声分布。在反向过程中,通过 UNet 逐步去除噪声,生成新的潜在样本。
3. 数据重建
使用预训练好的 VAE 解码器将去噪后的潜在表示映射回原始图像空间,得到最终的生成图像。
三、关键点
1. 感知压缩与潜在空间优化
LDM 通过预训练的自动编码器将高维图像数据进行感知压缩,映射到低维潜在空间。例如,将 256×256 的图像压缩为 16×16 的潜在表示,大幅减少了计算量。为了控制潜在空间的分布,LDM 采用了以下两种正则化技术:
- KL 正则化:约束潜在变量接近标准正态分布,类似于 VAE 的做法,增强了生成过程的稳定性。
- VQ 正则化:通过向量量化层对潜在表示进行离散化,类似于 VQ - VAE,有助于提升模型对结构化特征的学习能力。
2. 扩散过程与去噪机制
LDM 在潜在空间中进行扩散过程,分为前向扩散和反向去噪两个阶段:
- 前向扩散:逐步向潜在变量添加高斯噪声,噪声强度随时间步递增(如采用线性或余弦调度),最终使潜在表示接近纯噪声分布。
- 反向去噪:使用 UNet 预测当前潜在表示中的噪声,并逐步去除噪声。目标函数为预测噪声与实际噪声的均方误差,通过优化该目标函数提升模型的去噪能力。
3. 多模态条件生成
LDM 引入了交叉注意力机制,支持文本、图像、语义地图等多模态条件输入。具体实现方式如下:
- 条件编码器:将不同模态的输入(如文本、图像)映射为中间表示,再与 UNet 的中间层进行交互。
- 注意力融合:通过查询(Q)、键(K)、值(V)机制,将条件信息融入生成过程,实现对图像生成的精准控制,例如根据文本描述生成相应的图像。
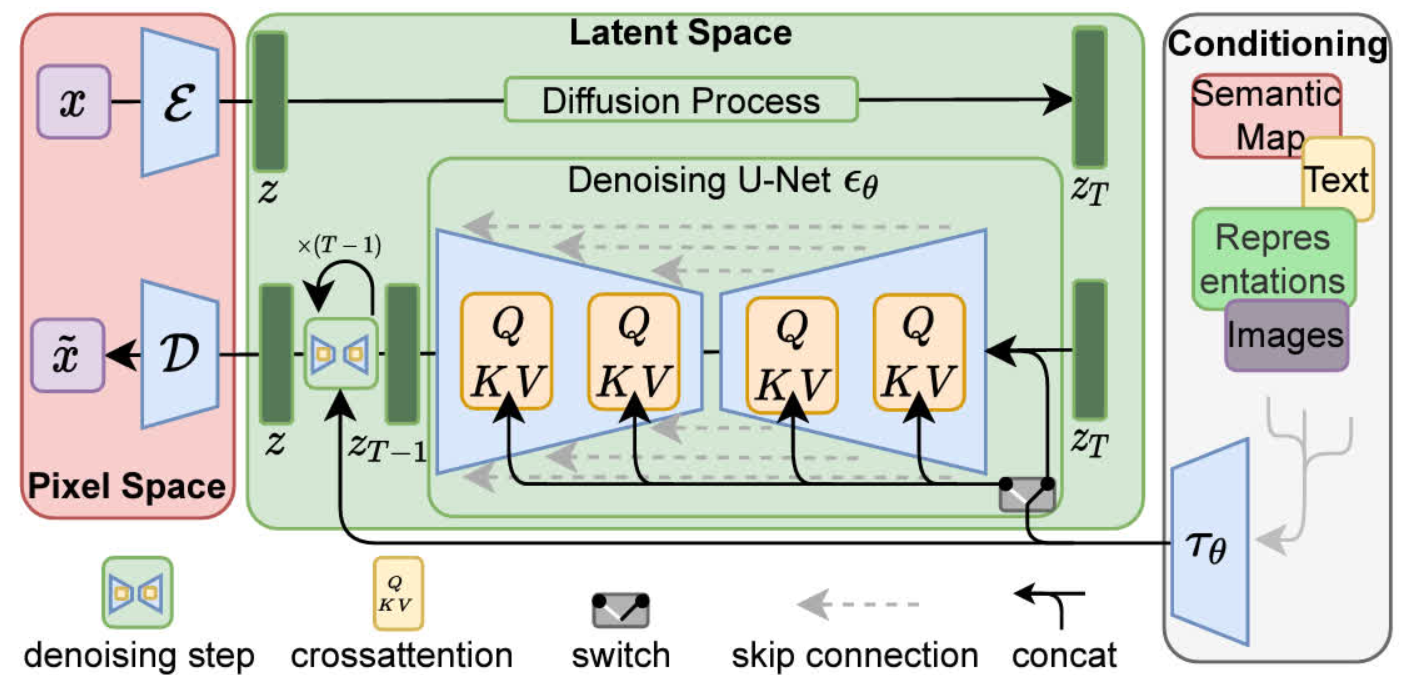
四、模型结构
1. 像素空间与潜在空间的转换
- 编码器(Encoder):由卷积网络构成,通过下采样和特征提取操作,将输入图像 x从高维像素空间压缩到低维潜在空间,生成潜在表示 z。
- 解码器(Decoder):包含上采样和特征重建层,将去噪后的潜在表示 \tilde{z}映射回像素空间,生成重建图像 \tilde{x}。
2. 潜在空间中的扩散过程
- 前向扩散:在潜在空间中,逐步向潜在表示 z添加高斯噪声,生成一系列噪声版本 z_t(t表示时间步)。
- 噪声调度:噪声强度随时间步递增,常见的调度方式有线性调度和余弦调度,最终使 z_T接近纯噪声。
3. 去噪 U-Net 核心模块
- 网络结构:
- 下采样路径:通过卷积层、批归一化(BN)和激活函数(如 ReLU)逐步提取多尺度特征。
- 上采样路径:使用反卷积或上采样操作恢复空间分辨率。
- 跳跃连接:将下采样层的特征直接传递到对应的上采样层,帮助保留图像的细节信息。
- 时间条件注入:
- 通过可学习的时间嵌入(如正弦位置编码)将时间步 t编码为向量。
- 将时间嵌入向量与 UNet 中间特征进行拼接,指导模型根据扩散进度调整去噪策略。
- 跨注意力机制:
- 条件融合:将条件信息(如文本、语义图)通过条件模块(如 Transformer)编码为查询(Q)。
- 潜在表示交互:将潜在表示 z_t作为键(K)和值(V),通过注意力机制与条件查询交互。公式:
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right) \cdot V
4. 条件输入处理
- 条件编码器:针对不同模态(如文本、图像)设计专用编码器,将输入映射为固定维度的向量。
- 与 UNet 交互:条件编码器的输出作为跨注意力层的查询,指导 UNet 的去噪过程,从而实现根据条件生成图像。
5. 去噪迭代过程
从纯噪声 z_T开始,通过 UNet 逐步去噪,每次迭代中 UNet 预测当前噪声并去除,最终生成干净的潜在表示 z_0,逐步逼近真实数据分布。
五、代码实现
import mindspore as ms
from mindspore import nn, ops, Tensor, Parameter
import mindspore.numpy as mnp
import numpy as np
# 超参数配置
config = {
"latent_dim": 64, # 潜在空间维度
"image_size": 64, # 输入图像尺寸
"batch_size": 32, # 批次大小
"timesteps": 1000, # 扩散时间步数
"lr": 1e-4, # 学习率
"channels": [64, 128, 256],# UNet通道数
"condition_dim": 128 # 条件嵌入维度
}
# 2. 编码器 - 解码器模块
class Encoder(nn.Cell):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, 3, pad_mode='same', padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32, 64, 3, pad_mode='same', padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.pool = nn.MaxPool2d(2, 2)
# 对于 64x64 输入,特征图尺寸为 64x16x16
self.fc = nn.Dense(64 * 16 * 16, config["latent_dim"])
def construct(self, x):
x = ops.relu(self.bn1(self.conv1(x)))
x = self.pool(ops.relu(self.bn2(self.conv2(x))))
x = x.view(x.shape[0], -1)
return self.fc(x)
class Decoder(nn.Cell):
def __init__(self):
super().__init__()
self.fc = nn.Dense(config["latent_dim"], 64 * 16 * 16)
self.conv1 = nn.Conv2d(64, 32, 3, pad_mode='same', padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32, 3, 3, pad_mode='same', padding=1)
self.upsample = nn.ResizeNearestNeighbor((32, 32))
def construct(self, z):
x = self.fc(z).view(-1, 64, 16, 16)
x = self.upsample(ops.relu(self.bn1(self.conv1(x))))
return self.conv2(x)
# 3. 时间编码模块
class TimeEmbedding(nn.Cell):
def __init__(self, dim):
super().__init__()
self.embed = nn.Embedding(config["timesteps"], dim)
self.proj = nn.Dense(dim, dim)
def construct(self, t):
return self.proj(self.embed(t))
# 4. 交叉注意力模块
class CrossAttention(nn.Cell):
def __init__(self):
super().__init__()
self.q_proj = nn.Dense(config["latent_dim"], config["condition_dim"])
self.k_proj = nn.Dense(config["condition_dim"], config["condition_dim"])
self.v_proj = nn.Dense(config["condition_dim"], config["condition_dim"])
self.scale = mnp.sqrt(mnp.asarray(config["condition_dim"], dtype=ms.float32))
def construct(self, z, condition):
q = self.q_proj(z)
k = self.k_proj(condition)
v = self.v_proj(condition)
attn = ops.matmul(q, k.transpose(0, 1)) / self.scale
attn = ops.softmax(attn, axis=-1)
return ops.matmul(attn, v)
# 5. UNet 去噪网络
class UNetBlock(nn.Cell):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, 3, pad_mode='same', padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, pad_mode='same', padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def construct(self, x):
residual = x
x = ops.relu(self.bn1(self.conv1(x)))
x = self.bn2(self.conv2(x))
return x + residual # 残差连接
class UNet(nn.Cell):
def __init__(self):
super().__init__()
self.time_emb = TimeEmbedding(config["latent_dim"])
self.down1 = UNetBlock(3, config["channels"][0])
self.down2 = UNetBlock(config["channels"][0], config["channels"][1])
self.down3 = UNetBlock(config["channels"][1], config["channels"][2])
self.up2 = UNetBlock(config["channels"][1] + config["channels"][2], config["channels"][1])
self.up1 = UNetBlock(config["channels"][0] + config["channels"][1], config["channels"][0])
self.final = nn.Conv2d(config["channels"][0], 3, 3, pad_mode='same', padding=1)
def construct(self, x, t, condition):
# 时间条件注入
t_emb = self.time_emb(t)
t_emb = ops.broadcast_to(t_emb[:, None, None, :], (x.shape[0], x.shape[1], x.shape[2], t_emb.shape[1]))
x = ops.concat((x, t_emb), axis=-1)
# 下采样路径
x1 = self.down1(x)
x2 = self.down2(ops.max_pool2d(x1, 2))
x3 = self.down3(ops.max_pool2d(x2, 2))
# 上采样路径
x = self.up2(ops.concat((ops.resize_nearest_neighbor(x3, scale=2), x2), axis=1))
x = self.up1(ops.concat((ops.resize_nearest_neighbor(x, scale=2), x1), axis=1))
# 交叉注意力融合条件
attn = CrossAttention()(x.view(x.shape[0], -1, x.shape[-1]), condition)
x = x + attn.view(x.shape)
return self.final(x)
# 6. 完整 LDM 模型
class LDM(nn.Cell):
def __init__(self):
super().__init__()
self.encoder = Encoder()
self.decoder = Decoder()
self.unet = UNet()
self.cross_attn = CrossAttention()
def construct(self, x, t, condition):
# 1. 编码到潜在空间
z = self.encoder(x)
# 2. 添加噪声(使用线性噪声调度)
beta = 1e-4 + (0.02 - 1e-4) * (t / config["timesteps"])
noise = ops.randn(z.shape) * mnp.sqrt(beta)
z_noisy = z + noise
# 3. UNet 去噪
# 调整形状以适应 UNet 输入
denoised = self.unet(z_noisy.view(-1, 64, 8, 8), t, condition)
# 4. 解码回图像空间
return self.decoder(denoised)