0Day支持!昇思MindSpore同步首发Qwen3,支持一键部署
0Day支持!昇思MindSpore同步首发Qwen3,支持一键部署
Qwen3是阿里云于2025年4月29日发布并开源的全新模型,作为Qwen 系列中的最新一代大型语言模型,提供了一系列密集型和混合专家(MoE)模型。本次Qwen发布多个尺寸模型,覆盖235B/32B/30B/14B/8B/4B/1.7B/0.6B。昇思MindSpore基于对Qwen2.5的支持与兼容主流生态的接口,快速实现Qwen3的0Day支持,并将MindSpore版Qwen3代码上传至开源社区代码仓,面向开发者提供开箱即用的模型。
模型链接:
类型
模型名称
魔乐社区链接
稠密Base
Qwen3-0.6B-Base
https://modelers.cn/models/MindSpore-Lab/Qwen3-0.6B-Base
Qwen3-1.7B-Base
https://modelers.cn/models/MindSpore-Lab/Qwen3-1.7B-Base
Qwen3-4B-Base
https://modelers.cn/models/MindSpore-Lab/Qwen3-4B-Base
Qwen3-8B-Base
https://modelers.cn/models/MindSpore-Lab/Qwen3-8B-Base
稠密Instruct
Qwen3-0.6B
https://modelers.cn/models/MindSpore-Lab/Qwen3-0.6B
Qwen3-1.7B
https://modelers.cn/models/MindSpore-Lab/Qwen3-1.7B
Qwen3-4B
https://modelers.cn/models/MindSpore-Lab/Qwen3-4B
Qwen3-8B
https://modelers.cn/models/MindSpore-Lab/Qwen3-8B
Qwen3-32B
https://modelers.cn/models/MindSpore-Lab/Qwen3-32B
稀疏MOE
Qwen3-30B-A3B
https://modelers.cn/models/MindSpore-Lab/Qwen3-30B-A3B
Qwen3-235B-A22B
https://modelers.cn/models/MindSpore-Lab/Qwen3-235B-A22B
# 01 Qwen3模型介绍
Qwen3是 Qwen 系列大型语言模型的最新成员。其中的旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出极具竞争力的结果。此外,小型 MoE 模型 Qwen3-30B-A3B 的激活参数数量是 QwQ-32B 的 10%,表现更胜一筹,甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。
1 Qwen3 模型支持两种思考模式
- **思考模式:**在这种模式下,模型会逐步推理,经过深思熟虑后给出最终答案。这种方法适合需要深入思考的复杂问题。
- **非思考模式:**在此模式中,模型提供快速、近乎即时的响应,适用于那些对速度要求高于深度的简单问题。
2
多语言
Qwen3 模型支持 119 种语言和方言。这一广泛的多语言能力为国际应用开辟了新的可能性。
3
预训练
在预训练方面,Qwen3 的数据集相比 Qwen2.5 有了显著扩展。Qwen2.5是在 18 万亿个 token 上进行预训练的,而 Qwen3 使用的数据量几乎是其两倍,达到了约 36 万亿个 token,涵盖了 119 种语言和方言。
4 后训练
Qwen3实施了一个四阶段的训练流程。该流程包括:(1)长思维链冷启动,(2)长思维链强化学习,(3)思维模式融合,以及(4)通用强化学习。
# 02 昇思MindSpore相关技术特性
昇思MindSpore原生支持Qwen系列大模型,兼容主流生态的分布式并行接口,已快速完成Qwen3多个模型的同步支持。同时,具备以下技术特性,加速模型训练、推理。
- 昇思MindSpore同步支持MindSpeed加速库,已完成Qwen3系列模型训练适配。
- **JIT加速,提升推理系统吞吐率:**昇思MindSpore通过JIT编译自动将模型的Python类或者函数,编译成一张完整的计算图,进而通过自动模式匹配,在整图范围内将多种小算子组合,融合成单个大颗粒的算子。同时,构建了Shape推导、Tiling数据计算、下发执行的三级流水线,实现Host计算和Device计算的掩盖,有效提升了计算图动态Shape执行效率。
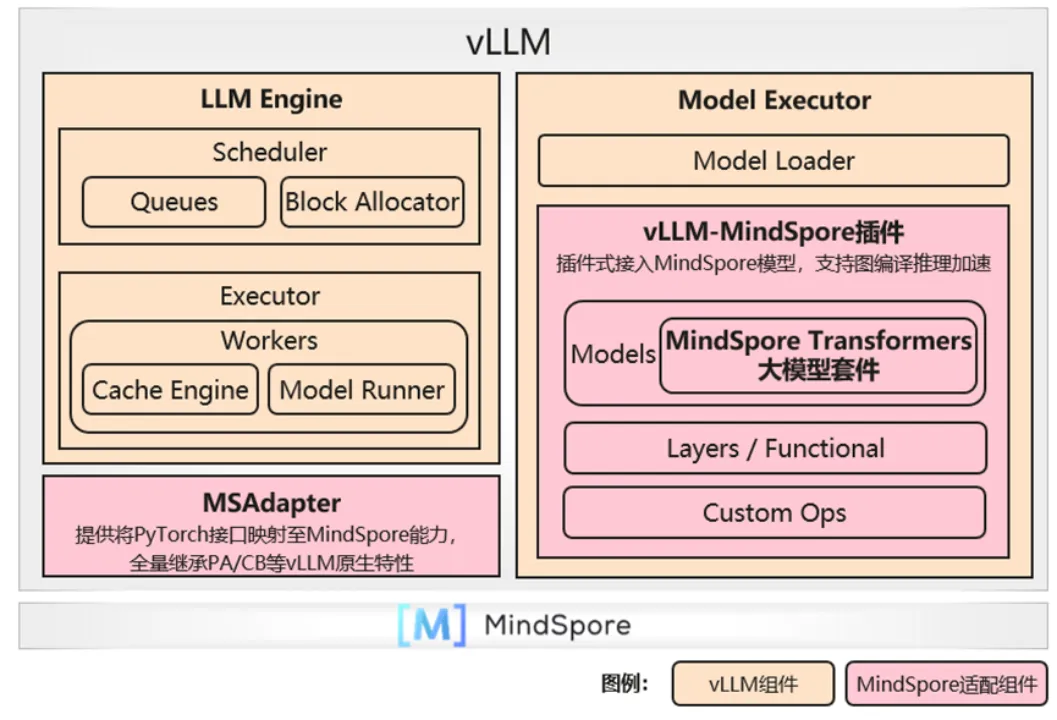
- **无缝接入vLLM生态:**昇思MindSpore开发了vLLM-MindSpore插件,支持主流大模型的推理服务部署。如图1所示,其采用MSAdapter将vLLM服务组件依赖的PyTorch接口映射至MindSpore能力,无缝继承了Continuous Batching等核心特性。通过插件式接入MindSpore Transformers套件所提供的大模型,实现昇腾+昇思的推理加速,有机整合了vLLM和MindSpore的推理加速能力。vLLM-MindSpore插件已适配vLLM v0.7.3版本,即将支持v0.8.3版本和V1架构。
# 03 手把手教程:基于昇思快速上手Qwen3模型训练和推理
1 快速开始
以Qwen3-32B推理为例,使用1台(2卡)Atlas 800I A2(64G)服务器(基于BF16权重)。昇思MindSpore提供了Qwen3-32B推理专用的Docker容器镜像,供开发者快速体验。
下载昇思 MindSpore Qwen3****-32B**** 推理容器镜像
执行以下 Shell 命令,拉取昇思 MindSpore Qwen3 推理容器镜像:
docker pull swr.cn-central-221.ovaijisuan.com/mindformers/qwen3_mindspore2.6.0-infer:20250428
启动容器
执行以下命令创建并启动容器:
docker run -it --privileged --name=qwen3 --net=host \
--shm-size 500g \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device /dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin:/usr/local/sbin \
-v /etc/hccn.conf:/etc/hccn.conf \
swr.cn-central-221.ovaijisuan.com/mindformers/qwen3_mindspore2.6.0-infer:20250428 \
bash
后续所有操作均在容器内操作。
模型下载
执行以下命令为自定义下载路径/home/work添加白名单:
export HUB_WHITE_LIST_PATHS=/home/work
执行以下 Python 脚本从魔乐社区下载昇思 MindSpore 版本的 Qwen3-32B 文件至指定路径/home/work。下载的文件包含模型代码、权重、分词模型和示例代码,占用约 62GB 的磁盘空间:
from openmind_hub import snapshot_download
snapshot_download(
repo_id="MindSpore-Lab/Qwen3-32B",
local_dir="/home/work",
local_dir_use_symlinks=False
)
注意事项:
- 下载时间可能因网络环境而异,建议在稳定的网络环境下操作。
2 服务化部署
1. 添加环境变量
在服务器中添加如下环境变量:
export MINDFORMERS_MODEL_CONFIG=/home/work/Qwen3-32B/predict_qwen3_32b.yaml
export ASCEND_CUSTOM_PATH=$ASCEND_HOME_PATH/../
export vLLM_MODEL_BACKEND=MindFormers
export vLLM_MODEL_MEMORY_USE_GB=50
export ASCEND_TOTAL_MEMORY_GB=64
export MS_ENABLE_LCCL=off
export HCCL_OP_EXPANSION_MODE=AIV
export HCCL_SOCKET_IFNAME=enp189s0f0
export GLOO_SOCKET_IFNAME=enp189s0f0
export TP_SOCKET_IFNAME=enp189s0f0
export HCCL_CONNECT_TIMEOUT=3600
export ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
2. 拉起服务
执行以下命令拉起服务:
python3 -m vllm_mindspore.entrypoints vllm.entrypoints.openai.api_server --model "Qwen3-32B" --trust_remote_code --tensor_parallel_size=32 --enable-prefix-caching --enable-chunked-prefill --max-num-seqs=256 --block-size=32 --max_model_len=70000 --max-num-batched-tokens=2048 --distributed-executor-backend=ray
3. 执行推理请求测试
执行以下命令发送流式推理请求进行测试:
curl http://localhost:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "Qwen3-32B ","prompt": "请介绍下北京的top景点", "temperature": 0, "max_tokens": 256, "top_p": 1.0, "top_k": 1, "repetition_penalty":1.0}'
本文档提供的模型代码、权重文件和部署镜像,当前仅限于基于昇思MindSpore AI框架体验Qwen3-32B的部署效果,不支持生产环境部署。相关使用问题请反馈至Issue。
昇思MindSpore AI框架将持续支持相关主流模型演进,并根据开源情况面向全体开发者提供镜像与支持。