零样本声音克隆!基于昇腾+MindSpore玩转Spark-TTS !
零样本声音克隆!基于昇腾+MindSpore玩转Spark-TTS !
Spark-TTS 是一款基于大语言模型(LLM)技术的先进文本转语音系统,能够根据用户需求合成高准确度且自然流畅的定制化语音。
MindSpore团队现已完成对Spark-TTS 的适配,并将其开源至MindSpore ONE仓库,本文将要给大家详细介绍,如何基于昇思MindSpore和单机Atlas 800T A2,完整实现Spark-TTS 定制化语音合成的部署流程。
- MindSpore ONE开源代码仓链接:
https://github.com/mindspore-lab/mindone/tree/master/examples/sparktts
# 01 效果展示
1、声音克隆

2、可控语音合成

# 02 核心特性
SparkTTS模型具有以下特性:
- 简洁高效:
1)完全基于 Qwen2.5 架构,无需依赖流匹配(flow matching)等额外生成模型。
2)直接通过大语言模型预测的音频编码重建语音,简化流程并提升合成效率。 - 高保真音色克隆:
1)支持零样本语音克隆(zero-shot),即使无目标说话人的训练数据,也能复现其音色。
2)特别适用于跨语言和语码转换场景,无需针对每种语言或音色单独训练。 - 双语混合支持:
兼容中文与英文,支持跨语言和语码切换的零样本克隆,实现多语言自然流畅的语音合成。 - 可控语音生成:
可通过调节性别、音高、语速等参数,自定义虚拟发音人声线特征。
# 03 模型介绍
Spark-TTS的语言模型采用解码器-仅变压器架构,与典型的文本语言模型统一。它使用预训练的文本LLM Qwen2.5-0.5B作为骨干模型。Spark-TTS不需要流匹配来生成声学特征,而是通过BiCodec的解码器直接处理LM的输出,生成最终的音频。 Spark-TTS的语音合成流程如下图所示:

figure1.infer_control
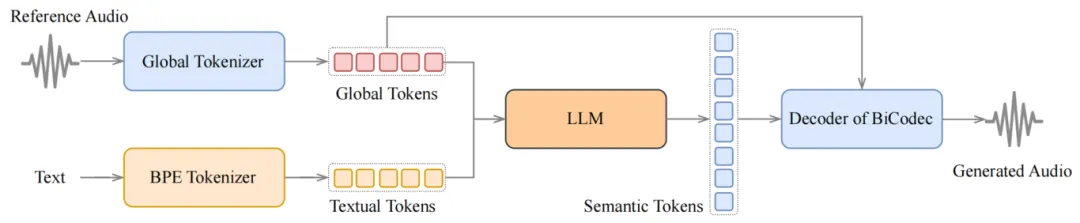
figure2.infer_voice_cloning
BiCodec包括一个全局tokenizer 和一个语义tokenizer 。前者从输入音频的梅尔频谱图中提取全局token ,后者使用wav2vec 2.0的特征作为输入提取语义token 。BiCodec的架构遵循标准的VQ-VAE编码器-解码器框架,并增加了tokenizer,解码器将离散token 重构为音频信号。语义tokenizer 的编码器和解码器是基于ConvNeXt块的卷积神经网络,采用单码本矢量量化。全局tokenizer 的编码器使用ECAPA-TDNN架构,并通过交叉注意力机制提取固定长度的全局token 序列,使用FSQ进行量化,以避免训练崩溃的风险。
LM模型结构如下:
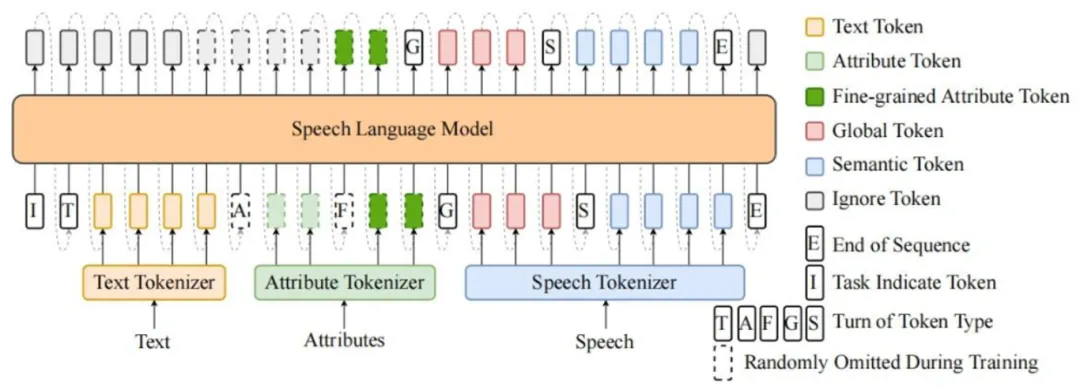
figure3.Speech language model of Spark-TTS
# 04 快速上手
1、环境准备

- CANN下载:
https://www.hiascend.com/developer/download/community/result?module=cann&cann=8.0.RC3.beta1 - MindSpore下载:
https://www.mindspore.cn/install
2、安装依赖
git clone https://github.com/mindspore-lab/mindone
cd mindone/examples/sparktts
pip install -r requirements.txt
3、模型下载
从Huggingface下载模型权重:
from huggingface_hub import snapshot_download
snapshot_download("SparkAudio/Spark-TTS-0.5B", local_dir="pretrained_models/Spark-TTS-0.5B")
下载完成后,使用以下命令把wav2vec2模型权重从bin格式转为safetensors格式:
python convert.py \
--pt_filename pretrained_models/Spark-TTS-0.5B/wav2vec2-large-xlsr-53/pytorch_model.bin \
--sf_filename pretrained_models/Spark-TTS-0.5B/wav2vec2-large-xlsr-53/model.safetensors \
--config_path /pretrained_models/Spark-TTS-0.5B/wav2vec2-large-xlsr-53/config.json
4、运行推理
进行语音生成推理也非常简单,运行下面的命令即可:
如果想要自定义语音生成的内容,只需要修改--text,输入你想要生成的文字即可,支持多种语言文字输入。另外,你还可以通过修 改--prompt_speech_path中提供的参考语音来控制你想要克隆的音色。
python -m cli.inference \
--text "text to synthesis." \
--save_dir "path/to/save/audio" \
--model_dir pretrained_models/Spark-TTS-0.5B \
--prompt_text "transcript of the prompt audio" \
--prompt_speech_path "path/to/prompt_audio"
如果你想要自定义虚拟发音人声线特征,调节性别、音高、语速等参数,只需要运行以下添加了此类参数的命令即可:
python -m cli.inference \
--text "text to synthesis." \
--save_dir "path/to/save/audio" \
--model_dir pretrained_models/Spark-TTS-0.5B \
--prompt_text "transcript of the prompt audio" \
--prompt_speech_path "path/to/prompt_audio" \
--gender choices=["male","female"]\
--pitch choices=["very_low","low", "moderate", "high", "very_high"]\
--speed choices=["very_low","low", "moderate", "high", "very_high"]\
# 05
性能实测
基于Atlas 800T A2和MindSpore2.5.0的性能测试结果如下:

# 06
马上体验
我们在魔乐社区上完成了Spark-TTS的部署!欢迎体验:https://modelers.cn/spaces/MindSpore-Lab/sparktts