支持GRPO强化学习训练全流程,揭秘MindSpore RLHF套件技术细节
支持GRPO强化学习训练全流程,揭秘MindSpore RLHF套件技术细节
近年来强化学习与大模型技术的融合日益深化,在此背景下,如何高效管理训练过程中的优化器激活值与权重释放,以及实现训练权重向推理阶段的转换,已成为强化学习中的必备技术。此外,利用SPMD架构的vLLM加速技术进行推理优化,也已成为提升系统整体性能的重要策略。
不久之前,MindSpore携手鹏城实验室发布并开源了基于Qwen2.5(7B,32B)模型的GRPO强化学习训练全流程和代码,实现了组件化解耦训练流程与模型定义,通过训推共部署、训练和推理权重在线快速自动重排、异构内存Swap等技术,成功构建从硬件算力、算法优化到集群调度的完整技术链条。
本次将围绕MindSpore RLHF套件中的关键技术进行进一步的分析,重点解读以下特性:
- 训推共部署
- 多维混合并行在线快速自动重排
- 异构内存Swap
- 支持vLLM
# 01 GRPO的算法流程实现
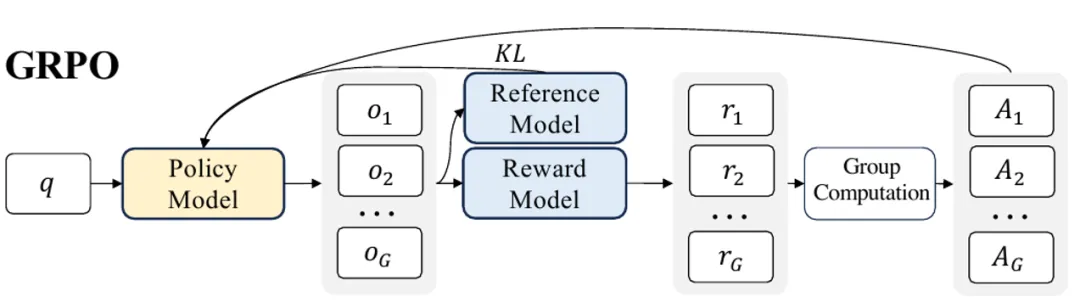
图 1:GRPO算法示意图
GRPO(Group Relative Policy Optimization,组相对策略优化)是DeepSeek针对数学等逻辑推理任务提出的强化学习优化算法。通过GRPO算法的大规模后训练得到的DeepSeek R1-Zero和DeepSeek R1模型在逻辑推理能力上得到了显著提升,涌现出了长思维链和反思等深度思考能力,其在数学和编程任务上的表现已超越或媲美OpenAI o1系列模型。
从监督学习到强化学习
在监督学习(Supervised Learning)中,模型通过“模仿”海量文本数据中的统计规律,学习预测下一个token。这种模式下,模型的目标是尽可能“复现”已有数据的分布,但缺乏主动优化的方向性。而强化学习(Reinforcement Learning, RL)则不同,它让模型(称为“智能体”)在动态环境中通过“试错”学习,根据反馈信号(奖励)自主探索最佳策略,这类似于人类通过实践反馈调整行为的过程。
在RL框架中,三个核心要素构成闭环:
* 环境(Environment):模型交互的对象(例如用户提问的输入、代码执行结果反馈)。
* 动作(Action):模型对环境做出的反应(例如生成一段回答或代码)。
* 奖励(Reward):一个标量函数,量化动作的质量(例如答案正确性评分或人工偏好打分)。
模型的目标是学习一个策略网络(Policy Network)——以LLM为例,其输出的token概率被视为一种“动作选择策略”。通过不断与环境交互,策略网络会逐渐倾向于选择能获得更高奖励的动作(例如生成更符合人类价值观或者与标准答案一致的回答)。这一过程的关键在于策略梯度(Policy Gradient) :用奖励信号作为权重,反向传播调整策略网络的参数,类似于传统LLM训练中的反向传播,但梯度来源于环境反馈而非固定标签。
GRPO算法的突破:用“相对比较”替代“价值模型”,用“规则奖励”替代“奖励模型”
传统RLHF算法(如PPO)需要同时训练策略网络,一个独立的价值模型(Value Network)来估计奖励期望值,和一个独立的奖励模型(Reward model)来给予实际奖励值,这类似于在LLM旁挂载一个“评分器”模型和一个用来模拟真实环境的“奖励模拟器”模型。但这种方法存在三个问题:
* 训练复杂度高,需训练三个模型,平衡其训练目标。
* 价值模型对奖励的绝对数值敏感,容易因奖励尺度变化导致训练不稳定。
* 作为“奖励模拟器”的奖励模型并不能完全反映真实环境奖励(如人类价值观或数学问题的回答是否正确),存在被“欺骗”(reward hacking)的风险。
DeepSeek提出的GRPO创新性地引入“组内相对比较”机制,并采取基于规则的奖励:
* 组(Group) :将同一输入生成的多条候选输出(例如4-8条回答)视为一组。
* 相对价值:不再依赖价值模型,而是计算组内样本间的相对优劣关系(例如A比B好,B比C差)。
* 基于规则的奖励:采用基于规则的显式奖励函数(如输出回答与标准答案的最终答案是否一致,输出代码是否通过所有测试用例)而不是一个奖励模型。
这样的设计消除了对独立价值模型的依赖,直接利用同一批次样本中不同策略输出的相对优势评估,既降低了显存占用,又避免了因价值模型预测偏差引发的训练波动,显著提升了训练稳定性。同时,GRPO采用基于规则的显式奖励函数,而非奖励模型。这种方法减少了奖励函数被对抗性样本“欺骗”(reward hacking)的风险,使奖励信号更透明、可解释且与任务目标强对齐。
MindSpore RLHF内部通过实现GRPOTrainer、GRPOConfig进行GRPO算法的控制和流程的实现。具体的运行脚本如下:
msrun --worker_num=8 --local_worker_num=8 --master_addr=127.0.0.1 \
--master_port=9190 --join=False --log_dir=./qwen2_5_one_log \
examples/grpo/qwen_grpo_tutorial/grpo_one_stage.py \
--
sft_path_infer ./model_configs/qwen_grpo/predict_qwen2_5_7b_instruct.yaml
\
--sft_path_train ./model_configs/qwen_grpo/finetune_qwen2_5_7b.yaml \
--vocab_path /{path}/vocab.json \
--merges_file_path /{path}/merges.txt \
--mind_dataset_dir /{path}/gsm8k_train.mindrecord \
--save_data_file /{path}/grpo.mindrecord \
--save_ckpt_dir /{path}/save_ckpt \
--use_parallel True \
--load_sft_checkpoint_infer /{path}/infer_ckpt \
--load_sft_checkpoint_train /{path}/train_ckpt \
--load_ref_checkpoint /{path}/ref_ckpt \
--enable_compile_cache False
具体的配置和参数说明可以参考:
https://gitee.com/mindspore/mindrlhf/blob/master/examples/grpo/qwen\_grpo\_tutorial/README.md
# 02 细粒度的模型参数offload/load机制
offload-load特性通过动态调度模型参数的存储位置,优化NPU显存使用:在生成阶段,仅保留推理模型(Infer Model)和参考模型(Reference Model)的参数在NPU上以加速推理计算,而将训练模型(Train Model)的参数卸载到CPU内存中;在训练阶段,则反向操作——将推理和参考模型的参数移至CPU,仅保留训练模型的参数在NPU上以支持梯度计算和参数更新。这种按需分配策略利用NPU的计算效率同时规避其显存限制,通过“热切换”模型参数的位置(NPU/CPU),显著降低峰值显存占用(例如从同时驻留三个模型降至仅一个),从而支持更大规模的模型训练或更高批次的并行处理,尤其适用于显存资源紧张的硬件环境。

图 2权重卸载加载示意图
在MindSpore RLHF提供的细粒度参数offload/load机制使能后,整个GRPO的显存占用几乎和微调、预训练的显存占用相同,如下图所示。通过MindSpore RLHF的细粒度的模型参数offload/load机制,假如单模型在单机8卡可以完成训练流程,那么同样的配置的情况下,MindSpore RLHF中整个GRPO流程的训练(包含训练、推理、权重在线重排等部分)也只需要单机8卡即可。
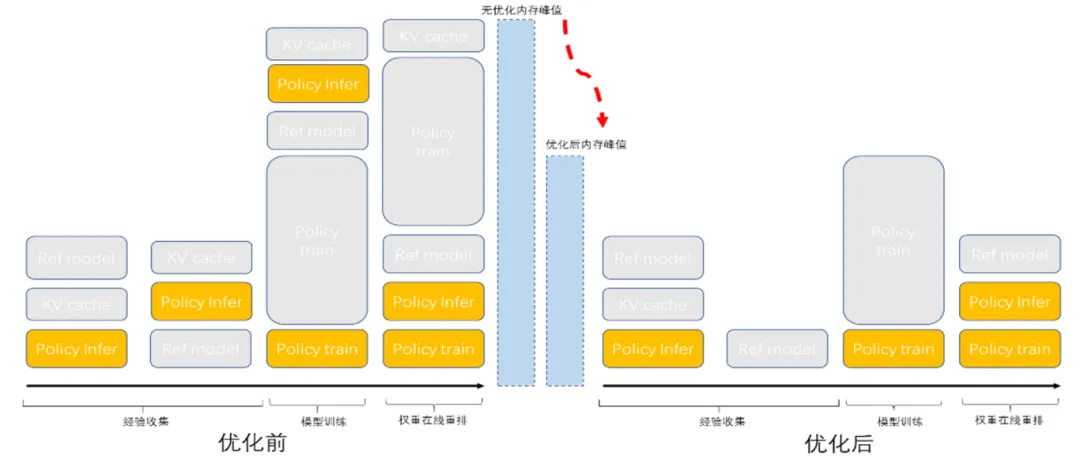
图3 通过细粒度的权重重排优化前后的内存变化
# 03 多维混合并行的权重在线重排布
训练和推理在执行时的并行策略一般不同,导致它们的权重切分策略也会不相同,因此没有办法直接将训练的权重赋给推理。传统方法中,会将训练权重先落盘,然后离线的将训练的权重排布倒换成推理的排布,推理加载倒换后的ckpt再进行推理。这会导致训练和推理被分割成了两个进程,性能无法达到最优。
因此MindSpore RLHF套件实现了训练权重排布到推理排布的在线转换,并能够实时更新至推理网络。该套件支持多种主流并行策略间的灵活转换,包括数据并行(DP)、模型并行(MP)、零冗余优化(ZeRO)、专家并行(EP)、长序列并行(CP)以及流水线并行(PP)等。下文将详细阐述几种典型的转换场景,并分析转换过程中涉及的通信。
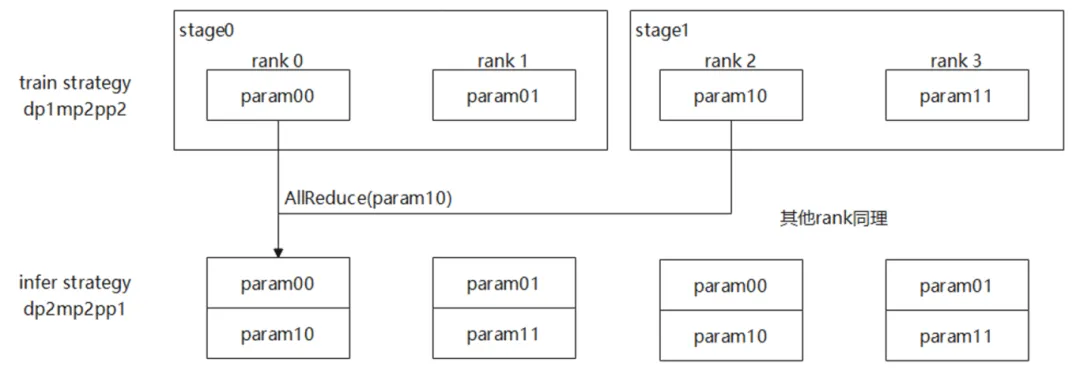
图 4流水线并行的倒换
图4为流水线并行场景下的权重倒换,训练策略为dp1mp2pp2,推理策略为dp2mp2pp1.由于mp的切分策略一致,因此不需要进行mp间的倒换,只需要进行pp间的聚合。
在MindSpore RLHF套件中,rank2上的参数param10通过AllReduce算子与rank0上的zero tensor进行聚合,从而将param10的权重数据聚合到rank0上,完成rank0上的pp间权重聚合。类似地,其他rank也通过AllReduce算子将对应位置的权重数据进行聚合,确保各rank上的权重数据在推理阶段能够正确分布和加载。
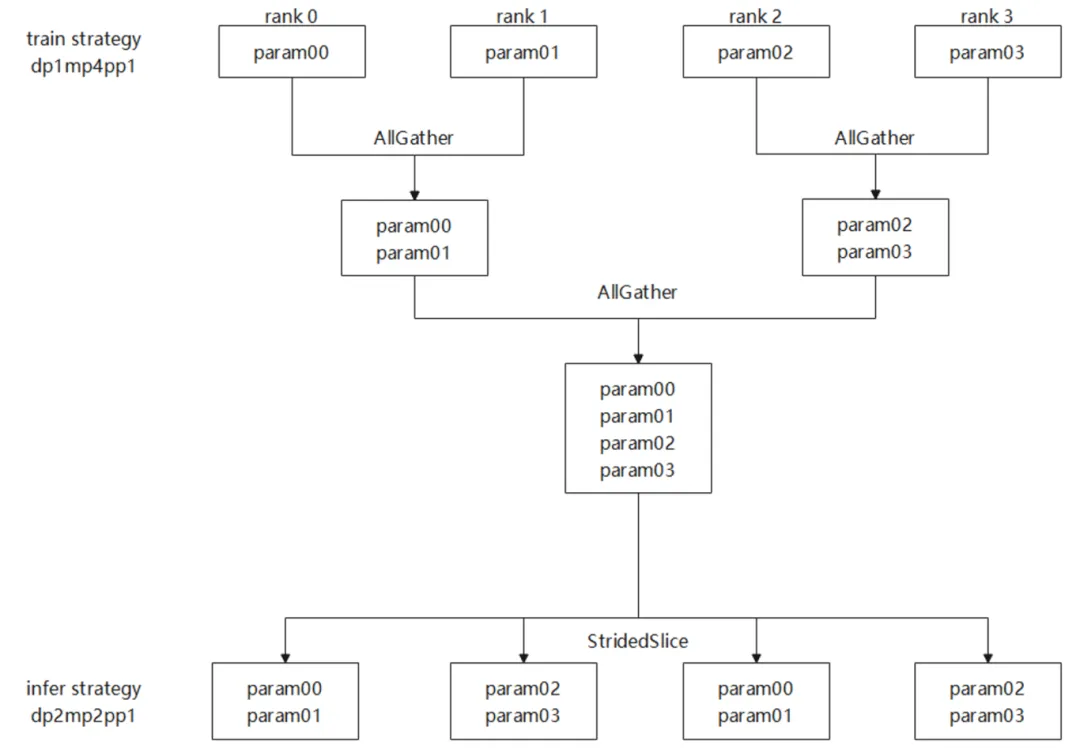
图 5模型并行的倒换
图5为模型并行场景下的权重倒换,训练策略为dp1mp4pp1,推理策略为dp2mp2pp1.因为pp的切分策略一致,所以仅需要进行mp间的倒换,不需要pp间的聚合。
mp4倒换到mp2会在rank0-rank3之间做两次AllGather通信让每张卡都获得一份完整的权重,然后每张卡通过StridedSlice获得自己需要的那一份权重。
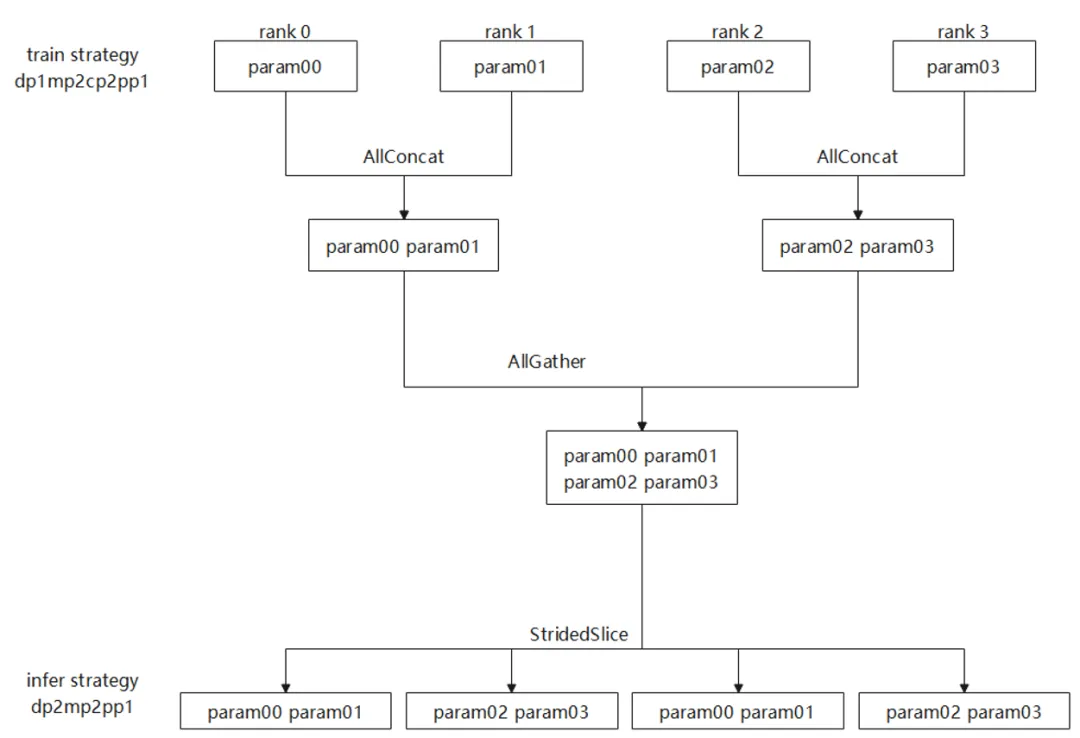
图 6长序列并行的倒换
图6为长序列并行的倒换,训练策略为dp1mp2cp2pp1,推理策略为dp2mp2pp1.训练需要在cp维度做聚合,从而实现从训练到推理的倒换。
mp2cp2倒换到mp2会首先对rank0-3的数据做AllConcat和AllGather,其中AllConcat的意思是在非0轴做一次聚合,比如将param00和param01在1轴做拼接,最终每张卡获得一份完整的权重。然后各自通过StridedSlice获得自己需要的那一份权重。
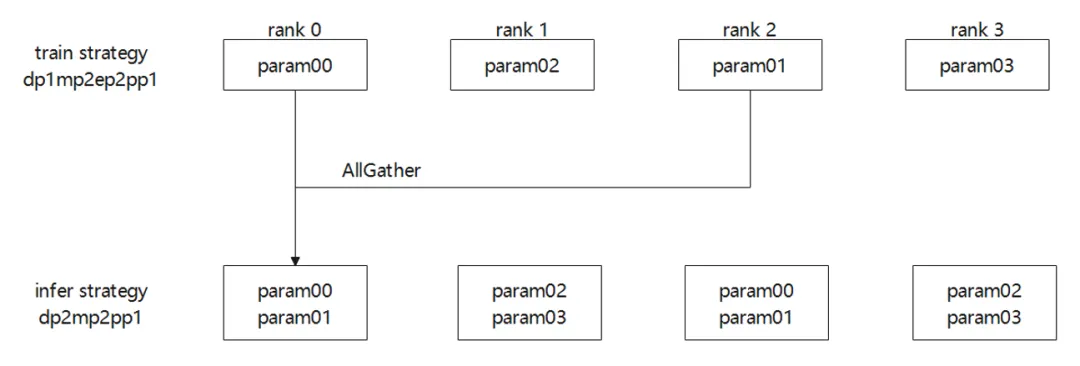
图 7专家并行的倒换
图7为专家并行的倒换,训练策略为dp1mp2ep2pp1,推理策略为dp2mp2pp1.训练需要在ep维度做聚合,从而实现从训练到推理的倒换。
mp2ep2倒换到mp2仅性需要进行一次rank0和rank2或者rank1和rank3的AllGather即可。每个rank上,0轴的ep维度被汇聚后,训练权重倒换成了推理权重的排布。
# 04 推理和训练共进程
训练和推理模型需要做权重重排同步(如图1流程),为了传输的代价最小,训练和推理得部署在同一个卡集合上。共进程可以更好的使能hccl的高速互联能力。
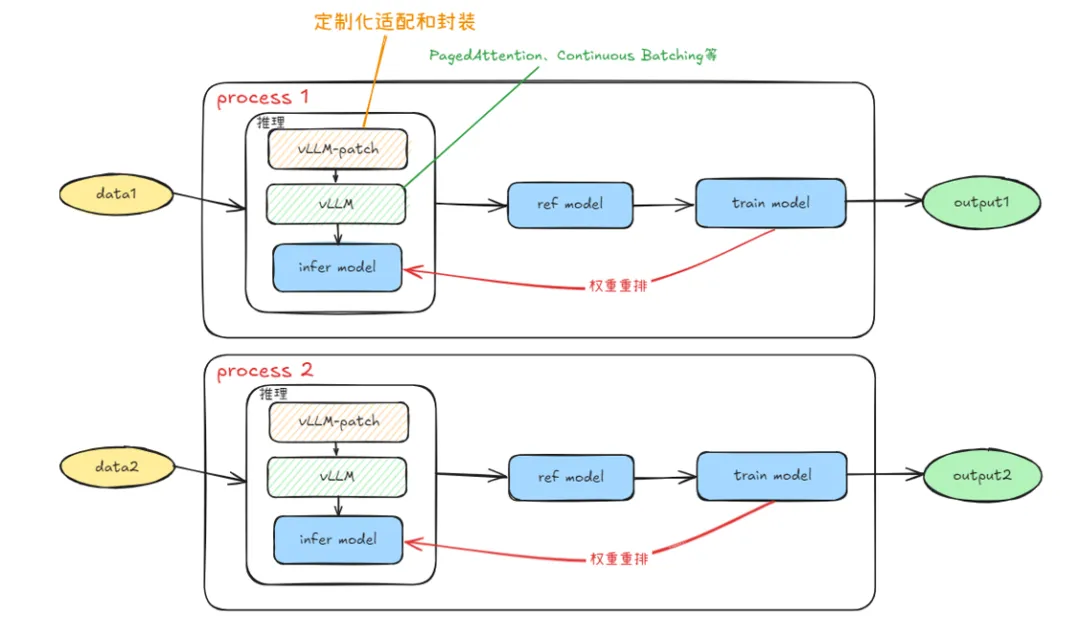
图 8 MindSpore RLHF训推共进程流程示意图
MindSpore RLHF中为了进行推理部分的加速,使用了vLLM。vLLM 是一个专为LLM设计的高效推理和服务框架,通过优化内存管理和注意力机制,可以显著提升LLM的推理速度、吞吐量和资源利用率,其最重要的两个优化点为:
- **PagedAttention:**传统LLM推理时,KV cache占用大量显存,且因序列长度可变导致内存碎片化。PA将KVcache分块为固定大小的“页”,按需动态分配和释放显存。显存利用率提升至99%以上,且能支持更长上下文。
- **Continuous Batching:**实时合并多个请求的输入,无需等待固定批次大小。可以提高GPU利用率,减少等待时间。
在具体实现的过程中,MIndSpore RLHF结合了vLLM最新版本的主要特性,主要做了以下两个方面的结合:
1、 由于vllm0.7版本以下的版本都是子进程启动推理服务,为了实现训推共进程,需要做一些定制化适配和封装。
2、 主要是继承了原始的vllm,以支持所需要的一些功能,比如取出特定计算结果、sync/offload params,weight loader的兼容等;
当前MindSpore RLHF结合vLLM的训练脚本和微调脚本类似,我们增加了use_vllm来控制vllm功能的开关。训练Qwen2.5 7B,单机8卡的指令如下:
msrun --worker_num=8 --local_worker_num=8 \
--master_addr=127.0.0.1 --master_port=9188 \
--join=True --log_dir=./qwen2_vllm_log \
examples/qwen_grpo_tutorial/grpo_one_stage.py \
--sft_path_infer./model_configs/qwen_grpo/predict_qwen2_7b_instruct.yaml \
--sft_path_train ./model_configs/qwen_grpo/finetune_qwen2_7b.yaml \
--vocab_path /path/to/vocab.json \
--merges_file_path /path/to/merges.txt \
--mind_dataset_dir /path/to/cvalues_one_1024.mindrecord \
--save_data_file /path/to/grpo_1024.mindrecord \
--save_ckpt_dir /path/to/ckpt/train \
--use_parallel True \
--enable_compile_cache False \
--load_sft_checkpoint_infer "/path/to/ckpt/infer" \
--load_sft_checkpoint_train "/path/to/ckpt/train" \
--use_vllm 1 \
--hf_config_path "/path/to/config.json"