全流程加速MoE模型预训练及强化学习!揭秘昇思MindSpore并行技术
全流程加速MoE模型预训练及强化学习!揭秘昇思MindSpore并行技术
昇思MindSpore已实现DeepSeek V3 + GRPO强化学习训练全流程支持,并将相关代码开源,为强化学习开发者提供了训练接口,支持算法快速开发,提供多种训练优化技术。
当前代码已在昇思社区开源,根据本教程,用户可以快速上手体验,或尝试完成DeepSeek V3 R1的训练全过程。
开源代码仓地址:https://gitee.com/mindspore/mindrlhf/tree/master/examples/grpo/deepseekv3\_grpo\_tutorial
昇思MindSpore框架为DeepSeek V3模型训练流程提供了以下性能优化技术:
- 专家并行下机间零冗余通信技术和共享专家通信掩盖结合,大幅减少超细粒度专家并行带来的通信时间开销。
- 自动专家负载均衡auxloss free训练技术,解决模型专家负载均衡问题并提高训练稳定性。
- 流水线并行1B1F 前反向掩盖技术,提高流水线并行场景下训练速度。
MindSpore实现了DP/TP/PP/CP/Zero/EP多维混合并行模式下的权重在线重排,支持DeepSeek V3模型在GRPO强化学习训练与推理阶段自由选择不同并行策略,并且在线进行训推权重转换。其中,在训练阶段支持数据并行(DP),张量并行(TP),流水线并行(PP),专家并行(EP),序列并行(SP)和ZeRO优化器并行;在推理阶段支持前端数据并行(DP)和张量并行(TP)。
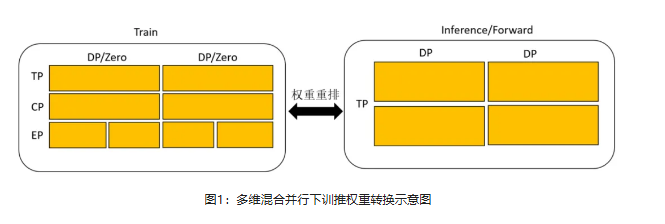
不久之前,昇思MindSpore携手鹏城实验室发布并开源了基于Qwen2.5(7B,32B)模型的GRPO强化学习训练全流程和代码,实现了组件化解耦训练流程与模型定义;升级了MindSpore技术架构,支持训推共部署,训练和推理权重在线快速自动重排与异构内存Swap等技术,成功构建从硬件算力、算法优化到集群调度的完整技术链条。
本次更进一步,MindSpore基于DeepSeek V3模型打通GRPO强化学习训练全流程。与Qwen2.5(7B,32B)模型相比,DeepSeek V3 模型采用超细粒度专家MoE结构,带来了训推过程中模型专家负载均衡的问题,以及训推权重在线快速重排中对专家并行(EP)切分策略的支持的新挑战。同时,超大的模型规模对训练性能和显存管理也提出了更高的要求。
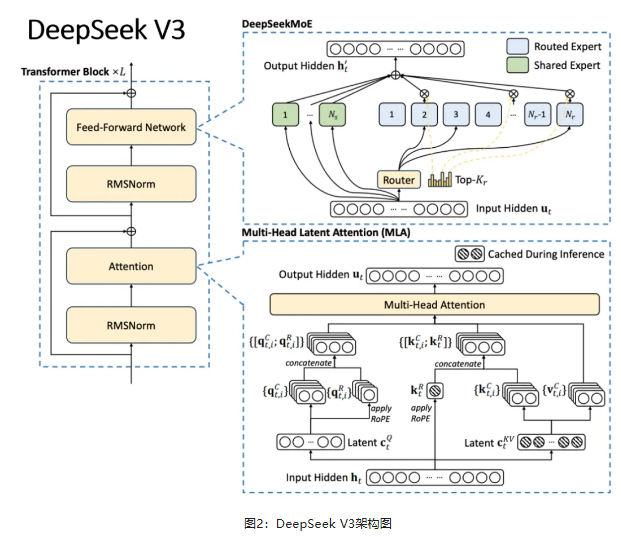
DeepSeek V3模型通过超稀疏MoE架构与多线性注意力(MLA)的协同创新,实现了性能与效率的双重突破,使模型推理成本较同性能闭源模型下降90%以上。此外,多标记预测(MTP)机制突破传统单token预测限制,在提升训练效率3倍的同时,生成文本的连贯性达到人类水平。
这些创新使DeepSeek V3在数学推理、代码生成等任务中超越GPT-4等闭源模型,开创了开源模型性能与成本平衡的新范式。
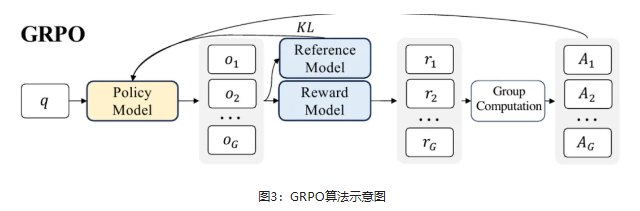
GRPO(Group Relative Policy Optimization,组相对策略优化)是针对数学等逻辑推理任务提出的强化学习训练的算法。强化学习的训练过程是学习一个策略模型,通过不断试错,策略模型与奖励函数的不断交互,策略模型会逐渐倾向于选择能获得更高奖励的行为,自主探索出最佳学习路径。
以DeepSeek V3作为基础模型,通过GRPO算法的大规模强化学习后训练得到的DeepSeek R1模型在逻辑推理能力上得到了显著提升,涌现出了长思维链和反思等深度思考能力。
# 01****基于DeepSeek V3的GRPO强化学习训练教程
一****环境搭建
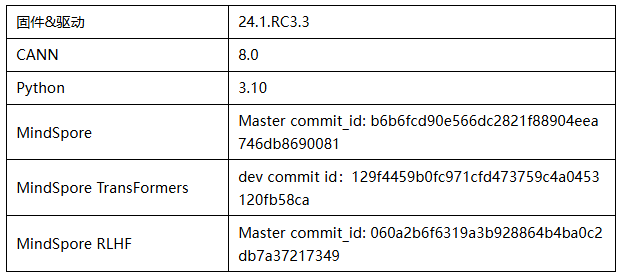
1、版本匹配关系
二 使用指南
1、数据集及文件的获取
使用examples/grpo/deepseekv3_grpo_tutorial/rlhf_data.py将GSM8k.json转换成mindrecord的形式,此数据路径为mind_dataset_dir的取值。此数据路径在启动训推作为mind_dataset_dir 的值。
python rlhf_data.py –tokenizer_file /path/to/tokenizer.json --file_path /path/to/raw/data/ --output_path /path/to/mindrecord/
参数说明
tokenizer_file:tokenizer.json路径
file_path:原始数据文件路径
output_path:输出文件路径
其中tokenizer.json文件可以从HuggingFace(https://huggingface.co/deepseek-ai/DeepSeek-V3)官方获取。
2、权重获取
用户可以从HuggingFace官方(https://huggingface.co/deepseek-ai/DeepSeek-V3)下载预训练权重,经过模型权重转换以及分布式权重切分后进行使用, 可以参考DeepSeek V3(https://gitee.com/mindspore/mindformers/tree/dev/research/deepseek3)进行操作。
2.1 MindSpore权重转换
完整权重转为MindSpore用的ckpt,进入MindSpore Formers路径下
python research/deepseek3/convert_weight.py --torch_ckpt_path TORCH_CKPT_DIR --mindspore_ckpt_path {path}/MS_CKPT_NAME --dtype bf16
参数说明
torch_ckpt_path: 下载HuggingFace权重的文件夹路径
output_path: 转换后的MindSpore权重文件保存路径
dtype: 转换权重的精度
2.2 获得策略文件
cd /path/to/your/mindformers/research/deepseek3
bash scripts/msrun_launcher.sh "run_mindformer.py \
--register_path research/deepseek3 \
--config /path/to/your/desired/model/yaml \
--run_mode finetune \
--train_data /path/to/mindrecord " 8 PORT output/msrun_log False 2000
参数说明:
# run_mindformer.py 参数
config: 模型的配置文件
run_mode: 运行模式选微调
train_data: 训练用的数据文件
# msrun_launcher.sh 参数
单机上卡数8
PORT为节点PORT
join=False
timeout=2000
生成的策略文件在strategy下,在下一步切分ckpt时作为dst_strategy的值。
2.3 获得特定切分的ckpt
nohup python transform_checkpoint.py --src_checkpoint=/path/to/checkpoint.ckpt --dst_checkpoint=/path/to/desired/ckpt/ --dst_strategy=/path/to/strategy/ > output.log 2>&1 &
参数说明
src_checkpoint:原始权重路径
dst_checkpoint:目标权重路径
dst_strategy:目标权重策略文件路径
3. 训练/推理模型配置
3.1 训练模型配置
训练的模型的配置finetune_deepseek3_671b. yaml:
parallel_config:
data_parallel: 1 # 数据并行切分为 4
model_parallel: 4 # 模型并行切分为 1
pipeline_stage: 2 # 流水线并行切分为 1
expert_parallel: 1# 专家并行切分为 4
use_seq_parallel: True
micro_batch_num: 2
vocab_emb_dp: False
gradient_aggregation_group: 4
micro_batch_interleave_num: 2 # mp大于1时,设为1可提升训练效率
model_config:
num_layers: &num_layers 3
在本教程中,将DeepSeek V3的层数裁剪为3层使得可以本地执行任务。
训练相关配置在mindrlhf/configs/grpo_configs.py有学习率和GRPO相关的超参
optimizer: str = 'adamw' # 优化器类型
beta1: float = 0.9 # 优化器adamw超参,下同
beta2: float = 0.95
eps: float = 1.0e-8
weight_decay: float = 0.01
epochs: int = 100 # 训练轮数
3.2 推理模型配置
推理的模型的配置predict_deepseek3_671b.yaml
parallel_config:
data_parallel: 2
model_parallel: 4 # 模型并行切分为4
pipeline_stage: 1 # 流水线并行切分为1
expert_parallel: 1# 专家并行切分为1
micro_batch_num: 1
vocab_emb_dp: False
gradient_aggregation_group: 4
micro_batch_interleave_num: 1
model_config:
num_layers: &num_layers 3
在本教程中,将DeepSeek V3的层数裁剪为3层使得可以本地执行任务。
三****启动单机8卡训练脚本
用bash run_grpo.sh启动GRPO强化学习流程。
注意:用户需要确认将MindSpore Transformers和MindSpore RLHF的路径加入PYTHONPATH。
msrun --worker_num=8 --local_worker_num=8 --master_addr=127.0.0.1 \
--master_port=9190 --join=False --log_dir=./deepseekv3_one_log \
examples/grpo/deepseekv3_grpo_tutorial/grpo_one_stage.py \
--sft_path_infer ./model_configs/deepseek_v3_config/predict_deepseek3_671b.yaml \
--sft_path_train ./model_configs/deepseek_v3_config/finetune_deepseek3_671b.yaml \
--tokenizer_path /path/to/tokenizer.json \
--mind_dataset_dir /path/to/gms8k.mindrecord \
--save_data_file /path/to/grpo.mindrecord \
--save_ckpt_dir /path/to/save/ckpt \
--use_parallel True \
--load_sft_checkpoint_infer /path/to/infer/ckpt \
--load_sft_checkpoint_train /path/to/train/ckpt \
--load_ref_checkpoint /path/to/ref/ckpt \
--enable_compile_cache False \
参数说明
# msrun 参数
worker_num:总卡数
local_worker_num:单机的卡数
master_addr:主节点地址
master_port: 主节点端口
join:是否等待所有worker退出
log_dir: 日志路径
# grpo_one_stage.py 参数
sft_path_infer:推理用的模型配置
sft_path_train:训练用的模型配置
tokenizer_path:tokenizer.json文件路径
mind_dataset_dir:训练数据文件的路径
save_data_file:中间推理结果的保存路径(可选)
save_ckpt_dir:训练ckpt的保存路径
use_parallel:是否并行
load_sft_checkpoint_infer: 推理ckpt路径
load_sft_checkpoint_train: 训练ckpt路径
load_ref_checkpoint:参考模型ckpt路径
enable_compile_cache:是否编译缓存
拉起任务后,通过
tail -f deepseekv3_one_log/worker_0.log