昇思MindSpore支持QwQ-32B并上线开源社区
昇思MindSpore支持QwQ-32B并上线开源社区
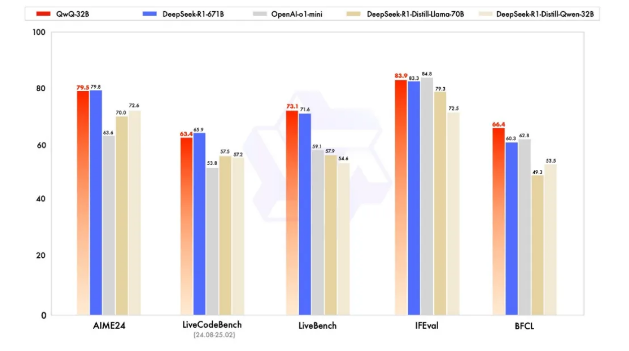
QwQ-32B是阿里云于2025年3月6日发布的人工智能大型语言模型。这是一款拥有 320 亿参数的模型,其性能可与具备 6710 亿参数(其中 370 亿被激活)的 DeepSeek-R1 媲美。这一成果突显了将强化学习应用于经过大规模预训练的强大基础模型的有效性。在保持强劲性能的同时,千问QwQ-32B还大幅降低了部署使用成本,此外,阿里云采用宽松的Apache2.0协议,将千问QwQ-32B模型向全球开源,所有人都可免费下载及商用。
QwQ-32B 在一系列基准测试中进行了评估,测试了数学推理、编程能力和通用能力。结果显示了 QwQ-32B 与其他领先模型的性能对比,包括DeepSeek-R1、OpenAI-o1-mini、DeepSeek-R1-Distilled-Llama-70B和DeepSeek-R1-Distilled-Qwen-32B。
昇思MindSpore原生支持Qwen2.5-32B, 在此基础上0Day完成QwQ-32B的支持,并且完成性能测试。昇思MindSpore开源社区、魔乐社区已第一时间上架该模型,欢迎广大开发者下载体验!此外,MindSpore将于近期支持vLLM推理框架部署,敬请期待!
魔乐社区:https://modelers.cn/models/MindSpore-Lab/QwQ-32B
以下为手把手教程:
# 01快速开始
QwQ-32B推理验证使用了Atlas 800T A2服务器(基于BF16权重)。昇思MindSpore提供了QwQ-32B推理专用的Docker容器镜像,供开发者快速体验。
1、下载昇思 MindSpore 推理容器镜像
执行以下 Shell 命令,拉取昇思 MindSpore 推理容器镜像(复用DeepSeek-V3的镜像):
docker pull
swr.cn-central-221.ovaijisuan.com/mindformers/deepseek_v3_mindspore2.5.0-infer:20250217
2、启动容器
执行以下命令创建并启动容器:
docker run -it --privileged --name=qwq-32b --net=host \
--shm-size 500g \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device /dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin:/usr/local/sbin \
-v /etc/hccn.conf:/etc/hccn.conf \
swr.cn-central-221.ovaijisuan.com/mindformers/deepseek_v3_mindspore2.5.0-infer:20250217 \
bash
注意事项:
如果部署在多机上,每台机器中容器的hostname不能重复。如果有部分宿主机的hostname是一致的,需要在起容器的时候修改容器的hostname。
后续所有操作均在容器内操作。
3、模型下载
执行以下命令为自定义下载路径/home/work/QwQ-32B添加白名单:
export HUB_WHITE_LIST_PATHS= /home/work/QwQ-32B
执行以下 Python 脚本从魔乐社区下载昇思 MindSpore 版本的 QwQ-32B 文件至指定路径/home/work/QwQ-32B。下载的文件包含模型代码、权重、分词模型和示例代码,占用约 62GB 的磁盘空间:
from openmind_hub import snapshot_download
snapshot_download(
repo_id="MindSpore-Lab/QwQ-32B",
local_dir="/home/work/QwQ-32B",
local_dir_use_symlink=False
)
下载完成的 /home/work/QwQ-32B 文件夹目录结构如下:
QwQ-32b
├── config.json # 模型json配置文件
├── vocab.json # 词表vocab文件
├── merges.txt # 词表merges文件
├── tokenizer.json # 词表json文件
├── tokenizer_config.json # 词表配置文件
├── predict_qwq_32b.yaml # 模型yaml配置文件
├── qwen2_5_tokenizer.py # 模型tokenizer文件
├── model-xxxxx-of-xxxxx.safetensors # 模型权重文件
└── param_name_map.json # 模型权重映射文件
注意事项:
/home/work/QwQ-32B可修改为自定义路径,确保该路径有足够的磁盘空间(约 62GB)。
模型权重文件和映射文件单独存放到一个文件夹目录下。
下载时间可能因网络环境而异,建议在稳定的网络环境下操作。
# 02服务化部署
1、修改模型配置文件
在 predict_qwq_32b.yaml 中对以下配置进行修改:
auto_trans_ckpt: True # 打开权重自动切分,自动将权重转换为分布式任务所需的形式
load_checkpoint: '/home/work/QwQ-32B' # 为存放模型分布式权重文件夹路径
processor:
tokenizer:
vocab_file: /home/work/QwQ-32B/vocab.json" # vocab文件绝对路径
merges_file: "/home/work/QwQ-32B/merges.txt" # merges文件绝对路径
2、一键启动MindIE
MindSpore Transformers提供了一键拉起MindIE脚本,脚本中已预置环境变量设置和服务化配置,仅需输入模型文件目录后即可快速拉起服务。
进入mindformers/scripts目录下,执行MindIE启动脚本
cd mindformers/scripts
bash run_mindie.sh --model-name QwQ-32B --model-path /home/work/QwQ-32B --max-prefill-batch-size 1
参数说明:
--model-name:设置模型名称
--model-path:设置模型目录路径
查看日志:
tail -f output.log
当log日志中出现Daemon start success!,表示服务启动成功。
3. 执行推理请求测试
执行以下命令发送流式推理请求进行测试:
curl -w "\ntime_total=%{time_total}\n" -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{"inputs": "请介绍一个北京的景点", "parameters": {"do_sample": false, "max_new_tokens": 128}, "stream": false}' http://127.0.0.1:1025/generate_stream &
# 03声明
本文档提供的模型代码、权重文件和部署镜像,当前仅限于基于昇思MindSpore AI框架体验QwQ-32B的部署效果,不支持生产环境部署。相关使用问题请反馈至ISSUE(链接:https://gitee.com/mindspore/mindformers/issues)。
昇思MindSpore AI框架将持续支持相关主流模型演进,并根据开源情况面向全体开发者提供镜像与支持。