人人都能上手部署DeepSeek-R1蒸馏模型:社区开发者应用昇思+香橙派 AI Pro实践优化心得
人人都能上手部署DeepSeek-R1蒸馏模型:社区开发者应用昇思+香橙派 AI Pro实践优化心得
作者:陈新杰 郑州轻工业大学 梅科尔工作室
前序
2025年蛇年春节,DeepSeek强势出圈,以十分之一的训练成本比肩OpenAI GPT-4o的性能,重塑AI世界新秩序。DeepSeek向全世界开源,为全球的数据科学家、AI爱好者乃至中小开发者开辟了一条通往前沿技术的道路。
而DeepSeek-R1-Distill-Qwen-1.5B 是DeepSeek-R1在 Qwen系列开源模型上进一步优化和蒸馏得到的轻量化语言模型,通过蒸馏技术实现效率与性能的平衡,适合于资源受限场景。
笔者所在的团队之前就有尝试在开发板上部署DeepSeek相关蒸馏模型,但苦于一直没有成功,或者部署成功后仅利用了CPU的算力,导致执行性能很慢。在2月10日了解到DeepSeek-R1-Distill-Qwen-1.5B模型基于MindSpore可以跑在香橙派AI Pro了(文章详见:https://mp.weixin.qq.com/s/l\_CcRJ7Yeirkom36RmizmQ),非常激动,当天晚上便在香橙派AI Pro(20T)24G开发板上把模型部署起来了。
但笔者在运行过程中也发现了一些问题和可优化点,所以在原代码基础上又进行了修改和优化,在此也分享下自己的心得:
开源链接
DeepSeek-R1-Distill-Qwen-1.5B部署代码:
问题描述
问题一:模型权重下载过慢或者不成功
原代码是从默认从HuggingFace上下载权重,有时会因为一些“你懂得”的问题下载权重过慢或者直接下载不成功。

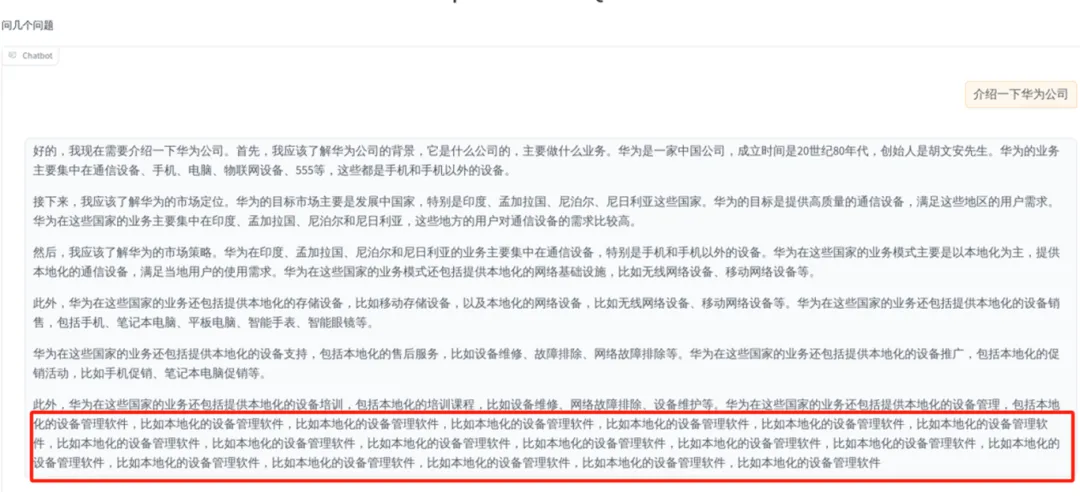
问题二:重复回答
在进行长文本输出的过程当中,输出回答到一定长度后模型会输出重复内容,如图所示:
解决方案
问题一:模型权重下载过慢或不成功
咨询了MindSpore工程师后发现,MindSpore NLP是支持选择镜像的,可以选择国内的镜像网站(如modelers、modelscope)下载权重,这里以modelers上下载权重为例。
我们发现魔乐社区(https://modelers.cn/) 上已经有了DeepSeek-R1-Distill-Qwen-1.5B的权重,我们点击图中红框部分,将model id复制下来。

并将代码中实例化tokenizer和模型的代码改成如下:
tokenizer = AutoTokenizer.from_pretrained("MindSpore-Lab/DeepSeek-R1-Distill-Qwen-1.5B", mirror="modelers", ms_dtype=mindspore.float16)
model = AutoModelForCausalLM.from_pretrained("MindSpore-Lab/DeepSeek-R1-Distill-Qwen-1.5B", mirror="modelers", ms_dtype=mindspore.float16)
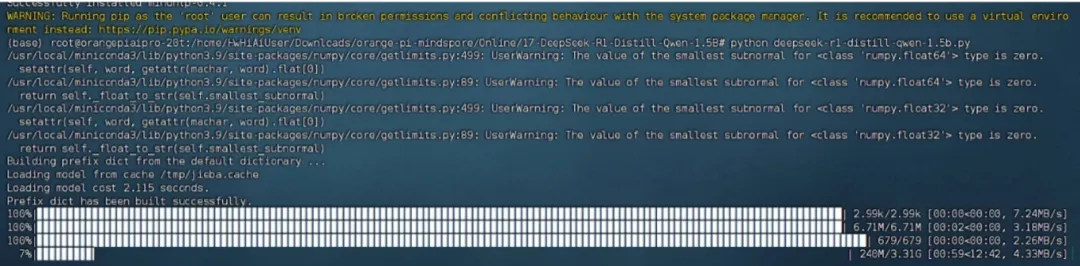
注意:目前MindSpore NLP master分支可支持从modelers下载镜像,需要在终端执行如下命令。
pip install git+https://github.com/mindspore-lab/mindnlp.git
安装后再执行DeepSeek-R1-Distill-Qwen-1.5B的案例python脚本,就可以下载权重了。
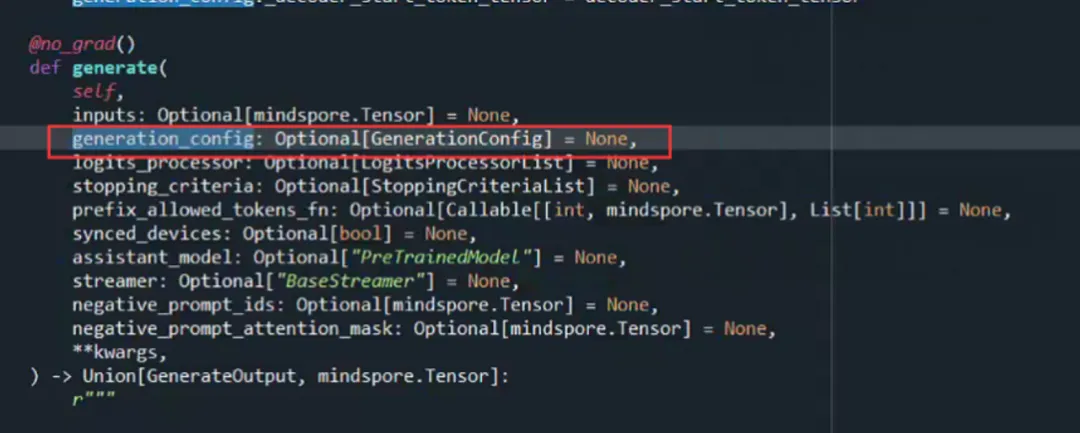
问题二:重复回答
这个在第二天与MindSpore社区工作人员讨论过后,确定是由于部分参数未进行设置,比如惩罚系数的参数设置,原程序设置为None:
需要将generate_kwargs(第34行)中添加repetition_penalty=1.2,即可解决长文本输出重复问题:
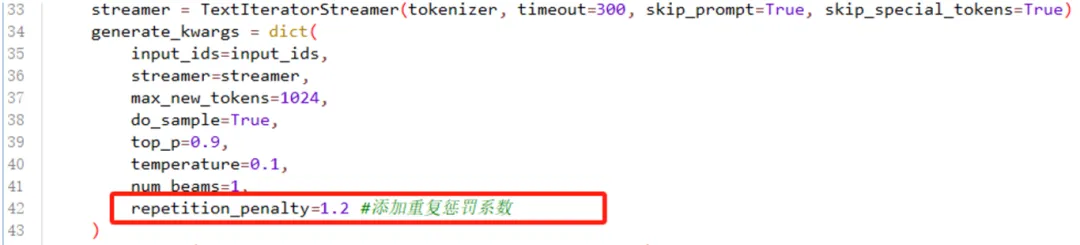
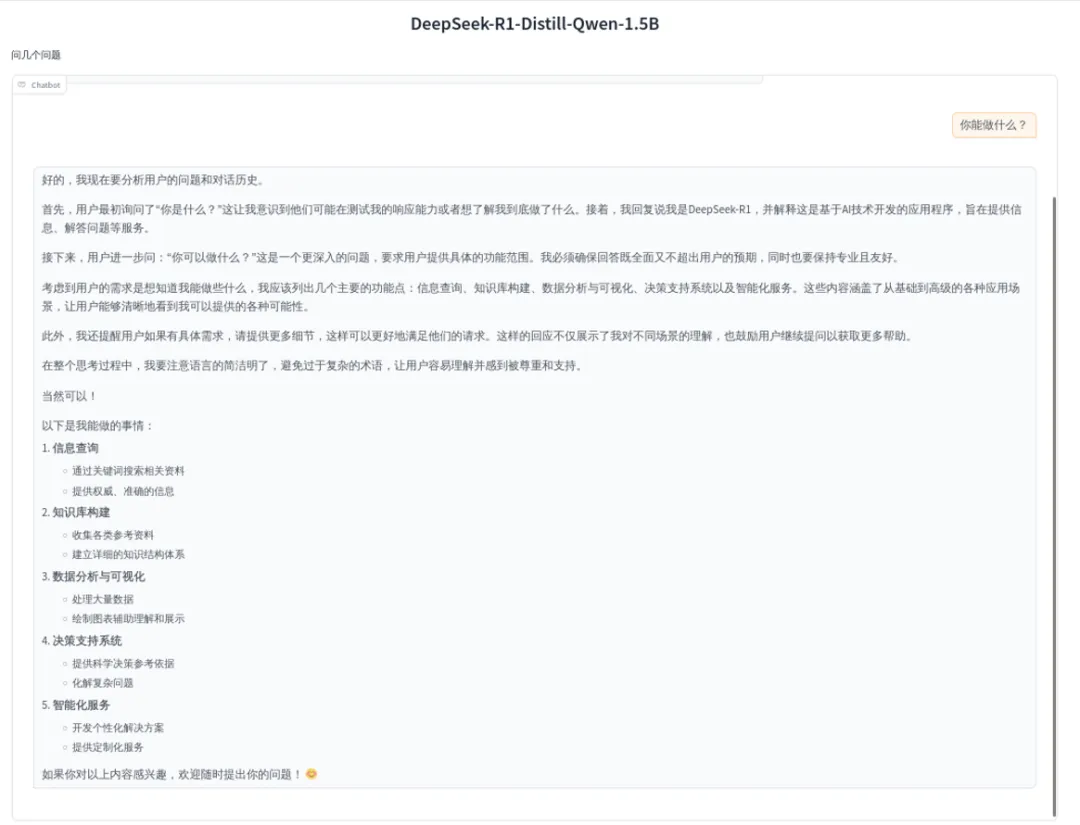
再次运行,长文本回答便不再出现重复内容,可以正常输出:
写在最后
感谢MindSpore开源社区开发专家的热情支持,专家们不仅耐心解答了我关于香橙派AI Pro硬件适配和DeepSeek模型部署流程中的各种疑难问题,还通过分享实际案例和优化技巧,让我对香橙派AI Pro的性能优势以及DeepSeek模型的高效部署有了更深入的理解,更加积极地参与开源社区、拥抱开源。