bertweet模型论文解读,并基于MindSpore NLP推理复现
bertweet模型论文解读,并基于MindSpore NLP推理复现
作者:YoursLLL 来源:知乎
论文创新点
BERTweet是首个大规模预训练的英语推文语言模型,基于BERTbase架构并使用RoBERTa的预训练方法。论文通过实验验证了BERTweet在以下推文自然语言处理任务上的性能优越性:词性标注(POS tagging)、命名实体识别(NER)和文本分类。通过850M条推文的大规模英语推文数据进行训练,BERTweet在所有任务上均优于现有的强基线模型,如RoBERTa和XLM-R。
Roberta概述
RoBERTa本质上是BERT,它只是在预训练中有以下变化:
1、在掩码语言模型构建任务中使用动态掩码而不是静态掩码。
2、不执行下句预测任务,只用掩码语言模型构建任务进行训练。
3、以大批量的方式进行训练。
4、使用字节级字节对编码作为子词词元化算法。
具体表现在什么地方呢,我们举一些例子来说明:
**
1. 动态掩码 vs. 静态掩码
**
**
BERT:在训练时,每个句子的掩码是预先固定的,比如对句子“猫在玩球”应用掩码,可能会得到“[MASK]在玩球”。在整个训练过程中,这个掩码方式保持不变(即在整个训练过程中,被掩盖掉的词总是“猫”)。
**
**
RoBERTa:采用动态掩码,每次训练时,句子的掩码位置会有所变化,例如句子“猫在玩球”在一次训练中可能变成“[MASK]在玩球”,而在另一轮训练中可能变成“猫在[MASK]球”,使模型能在不同上下文中学习更广泛的词语语义。
**
**
2. 使用字节级字节对编码(Byte-Pair Encoding, BPE)作为子词词元化算法
**
**
BERT:使用 WordPiece 词元化算法,将句子拆分为词元(token),例如“unhappiness”可能被分为“un-”, “happi-”和“-ness”。
**
**
RoBERTa:采用 BPE 子词词元化算法,以更细粒度的字节级别进行分词。像Emoji这样的特殊字符也会被分为多个字节级子词。这样,RoBERTa 可以处理更广泛的文本格式,包括非常见字符和表情符号。在Bertweet的数据训练主要来源于推文,在我的理解中,BPE对于Bertweet相当于关键的心脏部分。
**
假设词语为 internationalization:
**
BERT(WordPiece):将长词分解为更小的词根或词缀,比如:
**
"internationalization" -> ["inter", "##national", "##ization"]
**
RoBERTa(BPE):使用字节级分词算法,根据子词频率,按字节进行拆分:
**
"internationalization" -> ["international", "ization"]
在这种情况下,如果词干和后缀的组合频繁出现,RoBERTa 更倾向于保持这些高频的子词完整。
**
包含特殊字符Emoji的句子示例:

数据集上的指标评价得分
**
**
BERTweet在不同推文数据集上的主要任务评价指标表现如下:
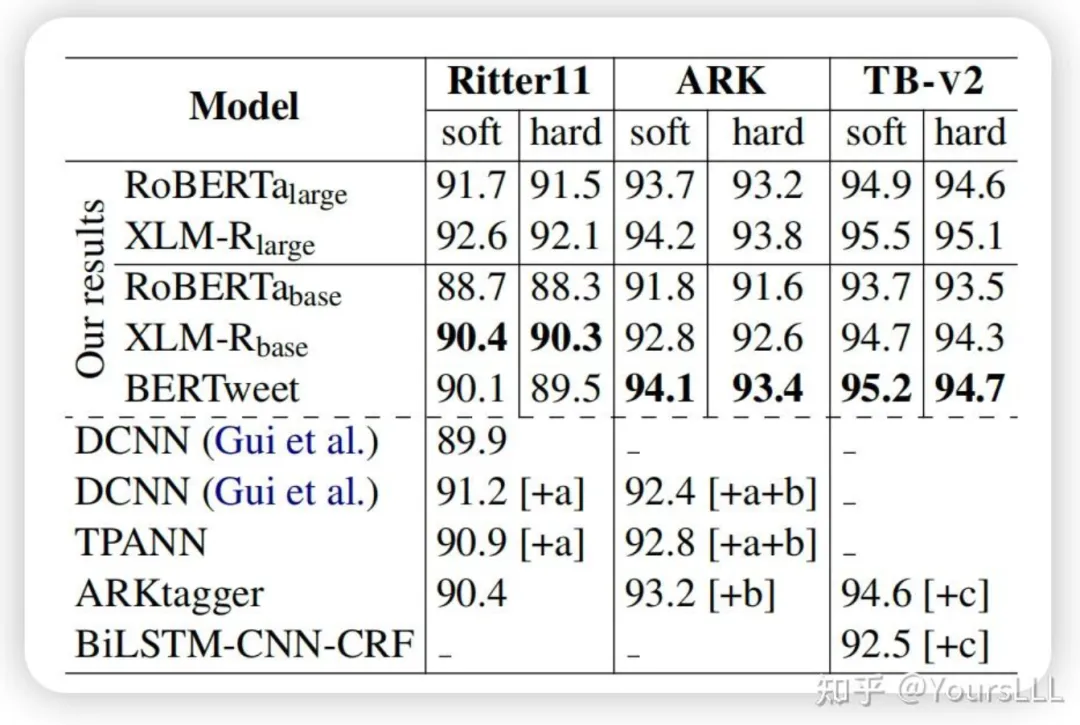
词性标注(POS Tagging):在Ritter11、ARK-Twitter和TWEEBANK-V2数据集上,BERTweet的准确率(Accuracy)分别为90.1%、94.1%、95.2%。
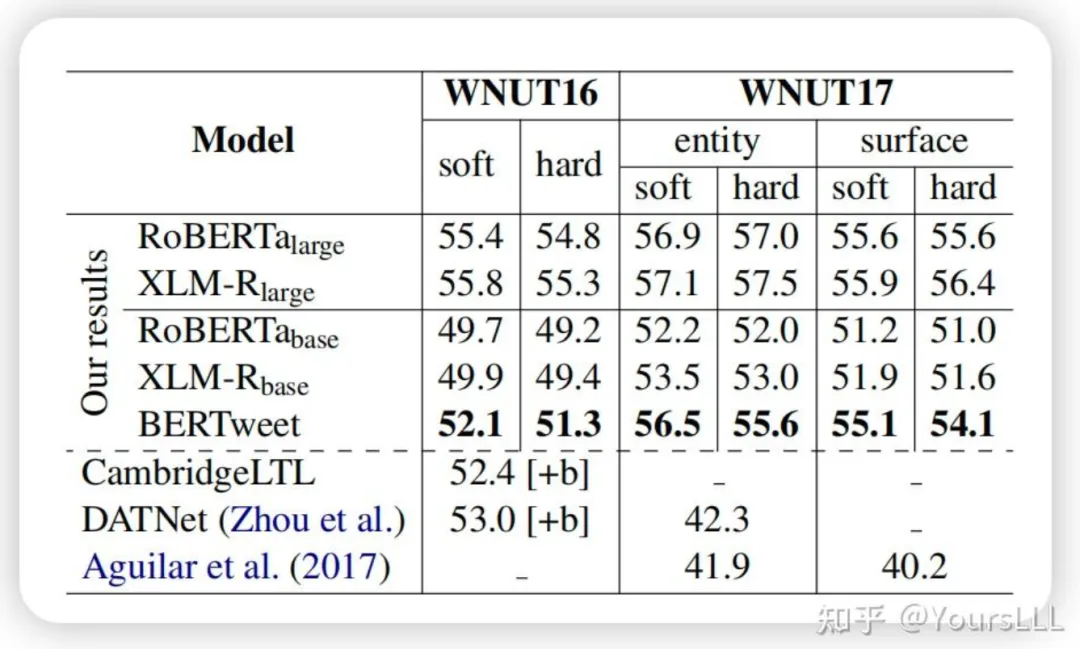
**命名实体识别(NER):**在WNUT16和WNUT17数据集上,BERTweet的F1分数为52.1%和56.5%。
**文本分类:**在SemEval2017-Task4A和SemEval2018-Task3A数据集上的F1得分分别为72.8%和74.6%,均刷新了现有的最优结果。
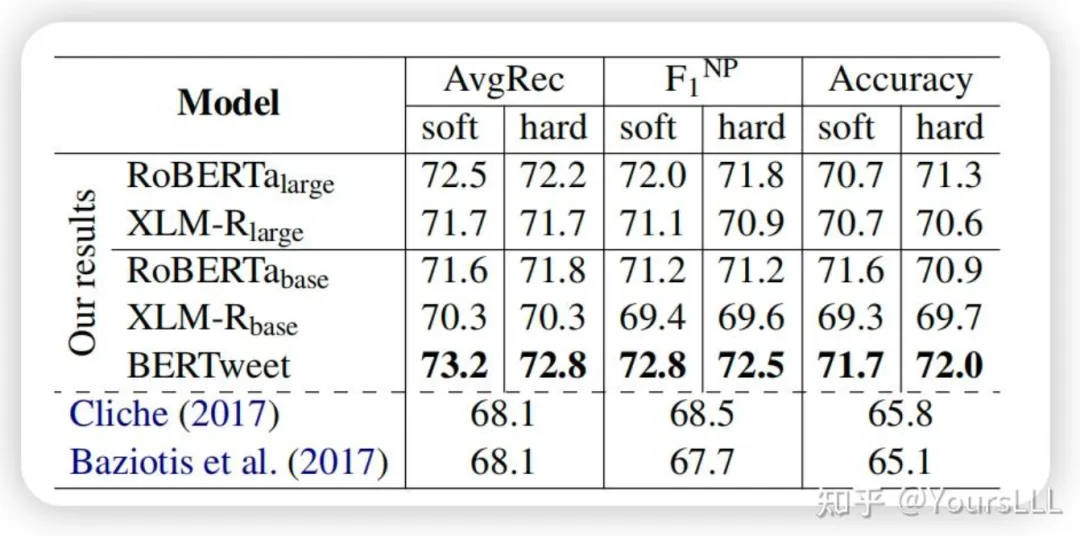
在 SemEval2017-Task4A 数据集上的得分表现
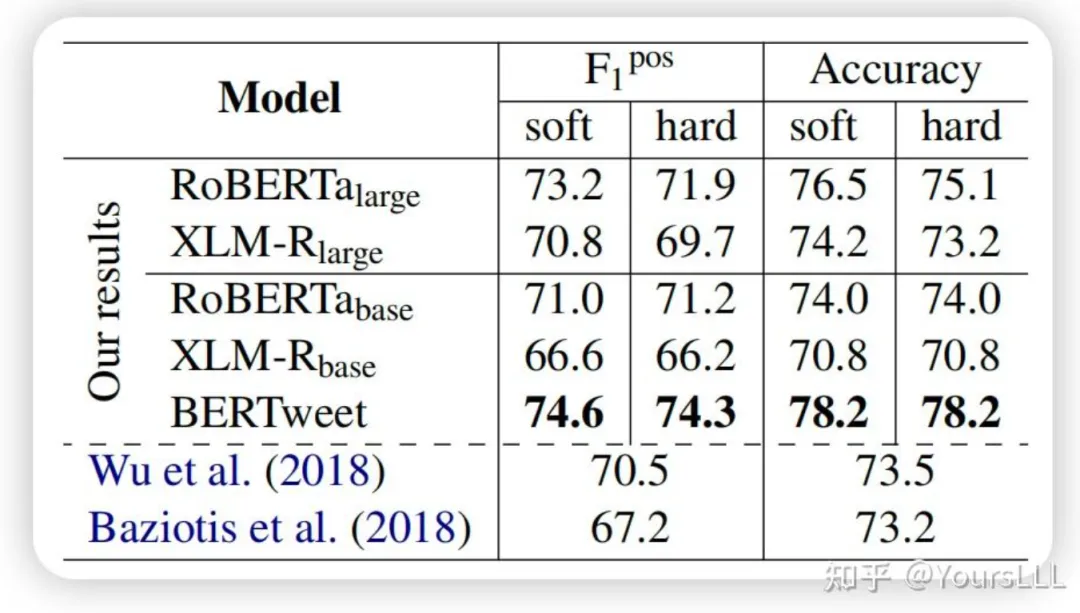
在 SemEval2018-Task3A 数据集上的得分表现
创新点优势
相较于以往的模型采用正规的、书面化的语言来做数据源(维基百科等)训练,BERTweet的主要创新点在于其**专门针对推文数据进行预训练,**从而有效处理推文特有的非正式表达方式(如缩写、拼写错误和表情符号)。相较于RoBERTa和XLM-R等模型,BERTweet采用了基于领域的预训练数据,使得其在处理推文时更具表现力。具体优势包括:
**1.专注于推文领域:**BERTweet利用850M条推文数据进行训练,而RoBERTa等模型则基于常规的书籍和新闻数据,这使得BERTweet在推文的特定任务上表现更佳。
**2. 高效的预训练方法:**尽管BERTweet的数据量小于XLM-R和RoBERTa的训练数据,但通过RoBERTa的优化预训练方法,模型在处理推文任务时能更好地提取领域特征。
**3. 丰富的词汇处理能力:**BERTweet对推文中特有的词汇进行了处理,例如用户提及和URL等符号的规范化,这使其在处理推文内容时具备较好的泛化能力。
基于 Bertweet 本文使用两种框架分别对两个数据集进行了推理验证:
核心代码切片如下:
情感分类任务(IMDB)数据集:
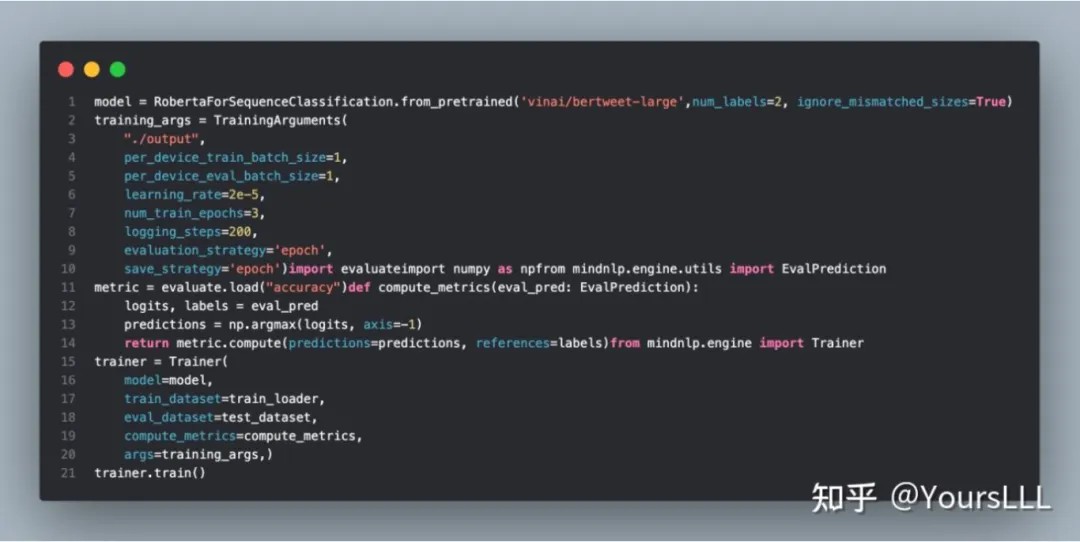
MindSpore NLP加载模型并以IMDB数据集训练
实体命名类任务(TweetBank数据集):
数据集地址: https://github.com/Oneplus/Tweebank
数据集处理与验证代码仓库:https://gitee.com/laizhenglin2024/bertweet-thesis
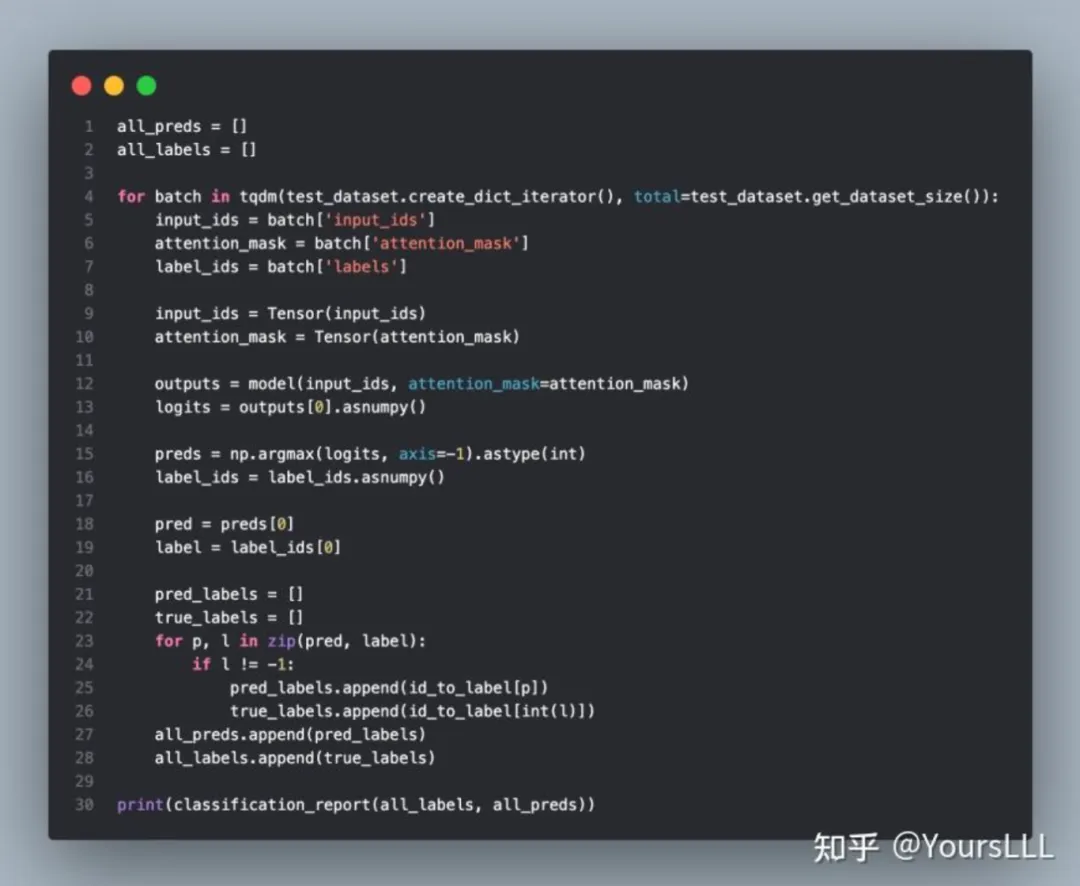
MindSpore NLP加载模型并以Tweetbank数据集训练
在Transformers和MindSpore NLP两个框架下加载相同数据集的得分对比:
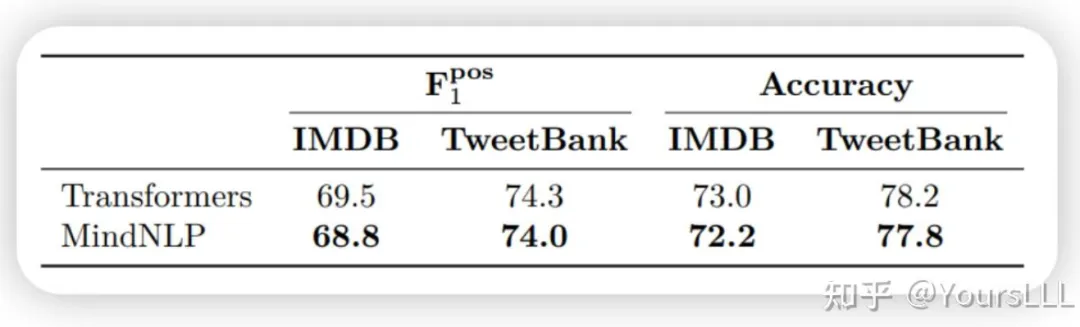
从得分上来看MindSpore NLP还是极其微弱于Transformers,毕竟Transformers在自然语言处理社区中广泛应用,并经历了大量的优化和调优。它拥有丰富的模型库和大量的社区贡献,这使得在标准任务上的表现更佳。而MindSpore NLP相对较新,尽管具有潜力,但在特定任务和预训练模型的优化上可能还不如Transformers成熟。但我相信经过国内社区生态慢慢建设发展一定能够MindSpore NLP一定能够表现的更好。
总结
BERTweet是一款专门为英语推文设计的大规模预训练语言模型,通过RoBERTa方法在850M条推文数据上训练,使其在推文特定任务(POS、NER、文本分类)上达到最优表现。与现有的强基线模型相比,BERTweet在领域内表现出色,为推文自然语言处理任务提供了一个强大且有效的模型,能够有效捕获推文中非正式表达的特点。研究的结果验证了针对特定领域数据的预训练模型在特定任务上的优势,未来可能会进一步扩展BERTweet模型至更大规模以提升任务表现。
**