什么是大模型解码策略?基于MindSpore NLP的Llama3分布式推理Decoding策略实践
什么是大模型解码策略?基于MindSpore NLP的Llama3分布式推理Decoding策略实践
作者:鲍迪 来源:昇思学习打卡营第五期·NLP特辑
《昇思学习打卡营第五期·NLP特辑》的直播和打卡已全部完成。由打卡营优秀学员们输出的学习笔记同样值得我们研读和学习。本期技术文章由打卡营学员鲍迪输出并投稿。如果您也在本期打卡营中获益良多,欢迎私聊我们投稿。
大模型解码策略
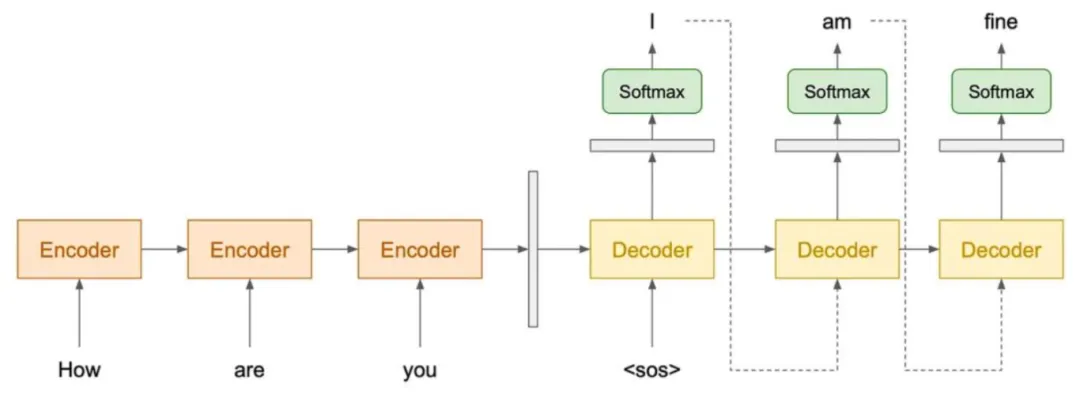
在大模型(如GPT、BERT等)中,分词器(Tokenizer)将输入文本转换为tokens后,模型内部会通过一系列复杂的计算步骤处理这些tokens,最终生成输出。要生成文本,通常是通过一次生成一个token来自回归方式完成的。
哪个embedding用于预测下一个token?
当一段长句子作为输入被编码后,每个token都会转换成对应的embedding向量。在预测下一个token时,并不是单独使用某个token的embedding,而是考虑整个输入序列的上下文信息。基于Transformer架构的模型会通过自注意力机制(self-attention mechanism)来计算输入序列中所有token之间的关系,从而为每个位置生成一个综合了全局信息的表示。这个过程允许模型在预测下一个token时,考虑到之前的所有tokens,而不仅仅是直接前一个token的embedding。
预测到下一个token的概率后,LLM模型是怎么生成完整回答的?
一旦模型预测出下一个token的概率分布,有几种策略可以用来选择具体的token以形成最终的回答:
**1. 贪婪搜索:**选择概率最高的token作为下一个token。
**2. 束搜索(Beam Search):**不是只跟踪最有可能的一个序列,而是同时跟踪多个候选序列,然后从中选择最优解。
**3. 采样方法:**如温度调整后的softmax采样、核采样(nucleus sampling)等,这些方法允许从概率分布中随机抽取下一个token,引入一定的随机性以增加多样性。
通过重复上述过程,每次都将新生成的token添加到当前序列中,并将其再次馈入模型以预测下一个token,直到达到预定长度或遇到结束标记为止。
为什么相同的输入会有不同的回答,这种随机性是如何实现的?
相同的输入能产生不同回答的原因主要在于模型在生成过程中采用的策略和算法:
• **随机性:**即使对于相同的输入,如果使用像核采样这样的策略,模型也会根据给定的概率分布随机选择下一个token,而不是总是选择概率最高的token。这增加了输出的多样性和创造性。
• **温度参数:**在softmax函数中使用的“温度”参数会影响概率分布的平滑度。较低的温度值会使模型更倾向于选择高概率的词,而较高的温度值则使分布更加均匀,从而增加随机性。
• **初始状态的不同:**如果模型包括一些形式的随机初始化(例如,在对话系统中的用户特定的上下文),即使是相同的输入也可能因为初始状态的不同而导致不同的输出。
实践代码
本期实践代码仓:
https://github.com/mindspore-lab/mindnlp/tree/master/llm/inference/llama3
本期实践借助分布式并行进行llama3推理的代码,来讲解解码策略的实现和调整。解码策略在现行的大模型代码中进行调整是非常方便的,无论是哪篇代码都只需要在model.generate函数中调整代码即可。
在model.generate函数中通过入参的调整就可以实现多种解码策略的调整和切换,详细可以参考这篇博文(https://blog.csdn.net/qq\_16555103/article/details/136805147)
那么我们暂且卖个关子,把今天要介绍的五种解码策略放到后面去讲,先来过一过分布式并行的代码。
MindSpore分布式并行
目前GPU、Ascend和CPU分别支持多种启动方式。主要有msrun、动态组网、mpirun和rank table四种方式:

分布式并行启动方式-MindSpore master文档
https://www.mindspore.cn/docs/zh-CN/r2.4.1/model\_train/parallel/startup\_method.html
msrun
msrun在用户安装MindSpore后即可使用,可使用指令msrun --help查看支持参数。 msrun支持图模式以及PyNative模式。
msrun启动:
https://www.mindspore.cn/docs/zh-CN/r2.4.1/model\_train/parallel/msrun\_launcher.html
使用方式
# msrun is a MindSpore defined launcher for multi-process parallel execution, which can get best performance, you can use it by the command below:
msrun --worker_num=2 --local_worker_num=2 --master_port=8118 --join=True run_llama3_distributed.py
# if you use Ascend NPU with Kunpeng CPU, you should bind-core to get better performance
msrun --worker_num=2 --local_worker_num=2 --master_port=8118 --join=True --bind_core=True run_llama3_distributed.py
mpirun
OpenMPI(Open Message Passing Interface)是一个开源的、高性能的消息传递编程库,用于并行计算和分布式内存计算,它通过在不同进程之间传递消息来实现并行计算,适用于许多科学计算和机器学习任务。使用OpenMPI进行并行训练是一种通用的在计算集群或多核机器上利用并行计算资源来加速训练过程的方法。OpenMPI在分布式训练的场景中,起到在Host侧同步数据以及进程间组网的功能。
与rank table启动不同的是,在Ascend硬件平台上通过OpenMPI的mpirun命令运行脚本,用户不需要配置RANK_TABLE_FILE环境变量。
相关命令:
mpirun启动命令如下,其中DEVICE_NUM是所在机器的GPU数量:
mpirun -n DEVICE_NUM python net.py

mpirun文档:https://www.open-mpi.org/doc/current/man1/mpirun.1.php
使用方式
# mpirun controls several aspects of program execution in Open MPI, you can use it by the command below:
mpirun -n 2 python run_llama3_distributed.py
# if you use Ascend NPU with Kunpeng CPU, you should bind-core to get better performance:
mpirun --bind-to numa -n 2 python run_llama3_distributed.py
llama3推理
单卡环境下运行run_llama3.py,使用MindSpore构建自动分词器和自动因果推理模型,搭建llama3模型的对话脚本。
# run_llama3.py
import mindspore
from mindnlp.transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "LLM-Research/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id, mirror='modelscope')
model = AutoModelForCausalLM.from_pretrained(
model_id,
ms_dtype=mindspore.float16,
mirror='modelscope'
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="ms"
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=20,
eos_token_id=terminators,
do_sample=False,
# do_sample=True,
# temperature=0.6,
# top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
llama3并行推理
分布式并行脚本,只是在上面脚本的基础上导入了mindspore.communication库,并使用 init初始化通信。在Terminal中输入即可启动脚本,进行分布式推理。
# Terminal
msrun --worker_num=2 --local_worker_num=2 --master_port=8118 --join=True run_llama3_distributed.py
# run_llama3_distributed.py
import mindspore
from mindspore.communication import init
from mindnlp.transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "LLM-Research/Meta-Llama-3-8B-Instruct"
init()
tokenizer = AutoTokenizer.from_pretrained(model_id, mirror='modelscope')
model = AutoModelForCausalLM.from_pretrained(
model_id,
ms_dtype=mindspore.float16,
mirror='modelscope',
device_map="auto"
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="ms"
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=100,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
解码策略
Greedy: Select the best probable token at a time|贪心:一次选择最可能的标记
每次都选择概率最高的token作为下一个token。这种方法简单直接,但可能导致生成的文本缺乏多样性。
generation_output = model.generate( input_ids=input_ids, num_beams = 1, do_sample = False, return_dict_in_generate=True, max_new_tokens=3,``)
Greedy Search(贪心搜索)是生成任务中最简单的解码策略,每次选择当前概率最高的词作为输出。虽然计算效率高,但可能陷入局部最优,导致生成结果不够多样或质量不高。以下是 Greedy Search 策略下 `model.generate()` 的常用参数设置建议。
### 1. **核心参数**
#### (1) `max_length`
- **作用**:生成序列的最大长度。
- **建议**:根据任务需求设置,避免过长或过短。
- 例如,文本摘要任务可以设置为 50-100,机器翻译任务可以设置为 100-150。
#### (2) `min_length`
- **作用**:生成序列的最小长度。
- **建议**:避免生成过短的结果,例如在摘要任务中可以设置为 10-20。
#### (3) `num_return_sequences`
- **作用**:返回的最终序列数量。
- **建议**:Greedy Search 每次只能生成一个最优序列,因此通常设置为 1。
### 2. **多样性控制参数**
#### (1) `no_repeat_ngram_size`
- **作用**:避免生成重复的 n-gram。
- **建议**:通常设置为 2 或 3,避免生成重复内容。
#### (2) `temperature`
- **作用**:控制生成结果的随机性。
- `temperature < 1`:更确定性的输出。
- `temperature > 1`:更多样化的输出。
- **建议**:Greedy Search 通常设置为 1.0(默认值),因为贪心策略本身是确定性的。
#### (3) `top_k` 和 `top_p`
- **作用**:限制候选词的范围。
- **建议**:Greedy Search 通常不使用这些参数,因为每次只选择概率最高的词。
### 3. **其他参数**
#### (1) `do_sample`
- **作用**:是否使用采样策略。
- **建议**:Greedy Search 是确定性的,因此通常设置为 `False`。
#### (2) `early_stopping`
- **作用**:是否在生成满足条件的序列时提前停止。
- **建议**:可以设置为 `True`,以节省计算资源。
**示例代码**
以下是一个典型的 Greedy Search 参数设置示例:
output = model.generate(
input_ids, # 输入序列
max_length=50, # 最大长度
min_length=10, # 最小长度
num_return_sequences=1, # 返回的序列数量(Greedy Search 只能返回 1 个)
no_repeat_ngram_size=2, # 避免重复 n-gram
early_stopping=True, # 提前停止
do_sample=False, # 不使用采样
temperature=1.0, # 温度参数(默认值)
)
Beam Search: Select the best probable response|波束搜索:选择最可能的响应
beam 在物理领域有光束的含义,简单理解为“多个”就行。它总是保留当前概率最大的num_beams个序列(注意不是词,考虑了词组、短语)(如果num_beams=1就变成贪心解码了)。束搜索策略(beam search)本质上也是一个贪心解码策略 (greedy decoding) ,所以无法保证一定可以得到最好的结果,生成的文本通常较为简洁和连贯,但缺乏多样性。
generation_output = model.generate(
input_ids=input_ids,
num_beams = 3,
num_return_sequences=3,
return_dict_in_generate=True,
max_new_tokens=3,
)
**Beam Search** 是一种常用的解码策略,广泛应用于机器翻译、文本生成等任务。它通过保留多个候选序列(由 `num_beams` 控制)来优化生成结果的质量。以下是 Beam Search 策略下 `model.generate()` 的常用参数设置建议。
### 1. **核心参数**
#### (1) `num_beams`
- **作用**:控制每次保留的候选序列数量。
- **建议**:
- 小任务:**5-10**
- 中等任务:**10-20**
- 大任务:**20-50**
- **注意**:
- 值越大,生成质量通常越高,但计算开销也越大。
- 值越小,生成速度越快,但可能陷入局部最优。
#### (2) `max_length`
- **作用**:生成序列的最大长度。
- **建议**:根据任务需求设置,避免过长或过短。
- 例如,文本摘要任务可以设置为 **50-100**,机器翻译任务可以设置为 **100-150**。
#### (3) `min_length`
- **作用**:生成序列的最小长度。
- **建议**:避免生成过短的结果,例如在摘要任务中可以设置为 **10-20**。
#### (4) `num_return_sequences`
- **作用**:返回的最终序列数量。
- **建议**:根据需求设置,通常设置为 **1-5**。
- **注意**:`num_return_sequences` 必须小于或等于 `num_beams`。
---
### 2. **多样性控制参数**
#### (1) `length_penalty`
- **作用**:控制生成序列长度的偏好。
- `length_penalty > 1`:鼓励生成长序列。
- `length_penalty < 1`:鼓励生成短序列。
- `length_penalty = 1`:无偏好。
- **建议**:通常设置为 **0.6-2.0**,默认值为 **1.0**。
#### (2) `no_repeat_ngram_size`
- **作用**:避免生成重复的 n-gram。
- **建议**:通常设置为 **2 或 3**,避免生成重复内容。
---
### 3. **其他参数**
#### (1) `early_stopping`
- **作用**:是否在生成满足条件的序列时提前停止。
- **建议**:
- 如果希望生成固定数量的序列,设置为 **`False`**。
- 如果希望尽早停止以节省计算资源,设置为 **`True`**。
#### (2) `do_sample`
- **作用**:是否使用采样策略。
- **建议**:Beam Search 通常设置为 **`False`**。
**示例代码**
以下是一个典型的 Beam Search 参数设置示例:
output = model.generate(
input_ids, # 输入序列
max_length=50, # 最大长度
min_length=10, # 最小长度
num_beams=10, # Beam 数量
length_penalty=1.2, # 长度偏好
no_repeat_ngram_size=2, # 避免重复 n-gram
num_return_sequences=3, # 返回的序列数量
early_stopping=True, # 提前停止
do_sample=False, # 不使用采样
)
参数设置总结
| 参数 | 建议值/范围 | 说明 |
|-----------------------|------------------------------|----------------------------------------------------------------------|
| `num_beams` | 5-50 | 控制候选序列数量,值越大生成质量越高,但计算开销越大。 |
| `max_length` | 任务相关(如 50-150) | 生成序列的最大长度,根据任务需求设置。 |
| `min_length` | 任务相关(如 10-20) | 生成序列的最小长度,避免生成过短的结果。 |
| `num_return_sequences`| 1-5 | 返回的序列数量,根据需求设置。 |
| `length_penalty` | 0.6-2.0 | 控制生成序列长度的偏好,值越大越鼓励生成长序列。 |
| `no_repeat_ngram_size`| 2 或 3 | 避免生成重复的 n-gram。 |
| `early_stopping` | `True` 或 `False` | 是否提前停止生成,以节省计算资源。 |
| `do_sample` | `False` | Beam Search 通常不使用采样策略。 |
Temperature: Shrink or enlarge probabilities|温度:缩小或扩大概率
Temperature 是控制生成文本多样性和确定性的重要参数,通过调整 Temperature,可以根据任务需求优化生成文本的质量。
• 低温度:生成结果更加确定性,适合需要准确性的任务。
• 高温度:生成结果更加多样性,适合需要创造性的任务。
import torch
logits = torch.tensor([[0.5, 1.2, -1.0, 0.1]])
# 无temperature
probs = torch.softmax(logits, dim=-1)
# temperature low 0.5
probs_low = torch.softmax(logits / 0.5, dim=-1)
# temperature high 2
probs_high = torch.softmax(logits / 2, dim=-1)
print(f"probs:{probs}")
print(f"probs_low:{probs_low}")
print(f"probs_high:{probs_high}")
logits 是一个包含四个元素的向量 [0.5, 1.2, -1.0, 0.1],这些值表示每个token的原始得分。
计算过程:
•无temperature:使用 softmax 函数将 logits 转换为概率分布,axis=-1 表示沿着最后一个轴进行操作。
• temperature降低0.5:将 logits 除以 0.5,然后应用 softmax,低温度会放大差异,使得高分值的token概率更高,低分值的token概率更低。
• temperature提升2:将 logits 除以 2,然后应用 softmax,高温度会减小差异,使得所有token的概率更加均匀。
probs:tensor([[0.2559, 0.5154, 0.0571, 0.1716]])
probs_low:tensor([[0.1800, 0.7301, 0.0090, 0.0809]])
probs_high:tensor([[0.2695, 0.3825, 0.1273, 0.2207]])
**• 无temperature:**概率分布为 [0.2559, 0.5154, 0.0571, 0.1716]。
• temperature降低0.5****概率分布为 [0.1800, 0.7301, 0.0090, 0.0809],可以看到,高分值的token(如 1.2)的概率显著增加,而低分值的token(如 -1.0)的概率显著减少,因此生成的结果可能性会变少,集中在更高概率的结果中。
**• temperature提升2****概率分布为 [0.2695, 0.3825, 0.1273, 0.2207],可以看到,所有token的概率变得更加均匀,**因此生成的结果可能性会更多。
Temperature Sampling(温度采样)是一种基于概率分布的生成策略,通过调整温度参数(`temperature`)控制生成结果的随机性和多样性。相比于 Greedy Search 和 Beam Search,Temperature Sampling 更适合需要多样性和创造性的任务(如故事生成、对话生成等)。以下是 Temperature Sampling 策略下 `model.generate()` 的常用参数设置建议。
### 1. **核心参数**
#### (1) `temperature`
- **作用**:控制生成结果的随机性。
- `temperature < 1`:更确定性的输出,倾向于选择高概率的词。
- `temperature > 1`:更多样化的输出,倾向于选择低概率的词。
- `temperature = 1`:无偏好的原始概率分布。
- **建议**:
- 需要高质量、确定性输出时,设置为 0.7-1.0。
- 需要多样性和创造性时,设置为 1.0-1.5。
- 避免设置过高(如 >1.5),否则可能导致生成结果不连贯。
#### (2) `max_length`
- **作用**:生成序列的最大长度。
- **建议**:根据任务需求设置,避免过长或过短。
- 例如,文本摘要任务可以设置为 50-100,对话生成任务可以设置为 100-150。
#### (3) `min_length`
- **作用**:生成序列的最小长度。
- **建议**:避免生成过短的结果,例如在摘要任务中可以设置为 10-20。
#### (4) `num_return_sequences`
- **作用**:返回的最终序列数量。
- **建议**:根据需求设置,通常设置为 1-5。
---
### 2. **多样性控制参数**
#### (1) `top_k`
- **作用**:限制候选词的范围,仅从概率最高的 `top_k` 个词中采样。
- **建议**:通常设置为 50-100,避免选择概率极低的词。
#### (2) `top_p`(Nucleus Sampling)
- **作用**:仅从累积概率超过 `top_p` 的词中采样。
- **建议**:通常设置为 0.9-0.95,与 `top_k` 结合使用效果更好。
#### (3) `no_repeat_ngram_size`
- **作用**:避免生成重复的 n-gram。
- **建议**:通常设置为 2 或 3,避免生成重复内容。
---
### 3. **其他参数**
#### (1) `do_sample`
- **作用**:是否使用采样策略。
- **建议**:Temperature Sampling 必须设置为 `True`。
#### (2) `early_stopping`
- **作用**:是否在生成满足条件的序列时提前停止。
- **建议**:可以设置为 `True`,以节省计算资源。
**示例代码**
以下是一个典型的Temperature Sampling参数设置示例:
output = model.generate(
input_ids, # 输入序列
max_length=50, # 最大长度
min_length=10, # 最小长度
do_sample=True, # 启用采样
temperature=0.9, # 温度参数
top_k=50, # 限制候选词范围
top_p=0.95, # Nucleus Sampling
no_repeat_ngram_size=2, # 避免重复 n-gram
num_return_sequences=3, # 返回的序列数量
early_stopping=True, # 提前停止
)
Top-K Sampling: Select top probable K tokens|Top-K 采样:选择最可能的 K 个 token
Top-K Sampling 做法很简单,从概率最大的K个token中采样,避免稀奇古怪的输出。可以生成更多样化的文本,但可能导致一些不连贯的内容。
import torch
filter_value = -float("Inf")
top_k = 2
probs = torch.tensor([[0.2559, 0.5154, 0.0571, 0.1716]])
indices_to_remove = probs < torch.topk(probs, top_k)[0][..., -1, None]
new_probs = probs.masked_fill(indices_to_remove, filter_value)
print("new_probs:", new_probs)
打印结果
new_probs: tensor([[0.2559, 0.5154, -inf, -inf]])
这个打印结果展示了经过 top-k 或 top-p 采样处理后的概率分布。这个张量的含义:
tensor([[0.2559, 0.5154, -inf, -inf]])
1. 格式说明:
- 这是一个形状为 [1, 4] 的二维张量
- 包含4个值,代表4个不同标记的概率分数
2. 具体值的含义:
- `0.2559`: 第一个标记的概率约为25.59%
- `0.5154`: 第二个标记的概率约为51.54%
- `-inf`: 第三和第四个标记被过滤掉了(概率被设置为负无穷)
- 只保留了概率最高的两个选项,其他选项被屏蔽掉
3. 为什么会有 `-inf`:
- 这通常是应用了 top-k 或 top-p 采样策略的结果
- `-inf` 表示这些标记在采样时会被完全排除
- 只有非 `-inf` 的标记(这里是前两个)会被考虑进行采样
4. 实际效果:
- 在后续采样中,只会从概率为0.2559和0.5154的两个标记中选择
- 这样可以避免选到低概率或不合适的标记,提高生成质量
这种处理方式是常见的文本生成策略,通过限制可选的标记数量来提高生成文本的质量。
Top-K Sampling是一种常用的生成策略,通过限制模型在生成每个词时仅从概率最高的 `k` 个候选词中选择,从而在生成质量和多样性之间取得平衡。
以下是 Top-K Sampling 策略下 `model.generate()` 的常用参数设置建议。
### 1. **核心参数**
#### (1) `top_k`
- **作用**:限制候选词的范围,仅从概率最高的 `k` 个词中采样。
- **建议**:
- 小任务:**10-50**
- 中等任务:**50-100**
- 大任务:**100-200**
- **注意**:
- `k` 值越小,生成结果越确定,但可能缺乏多样性。
- `k` 值越大,生成结果越多,但可能包含低质量的候选词。
#### (2) `max_length`
- **作用**:生成序列的最大长度。
- **建议**:根据任务需求设置,避免过长或过短。
- 例如,文本摘要任务可以设置为 **50-100**,对话生成任务可以设置为 **100-150**。
#### (3) `min_length`
- **作用**:生成序列的最小长度。
- **建议**:避免生成过短的结果,例如在摘要任务中可以设置为 **10-20**。
#### (4) `num_return_sequences`
- **作用**:返回的最终序列数量。
- **建议**:根据需求设置,通常设置为 **1-5**。
---
### 2. **多样性控制参数**
#### (1) `temperature`
- **作用**:控制生成结果的随机性。
- `temperature < 1`:更确定性的输出。
- `temperature > 1`:更多样化的输出。
- `temperature = 1`:无偏好的原始概率分布。
- **建议**:通常设置为 **0.7-1.0**,与 `top_k` 结合使用效果更好。
#### (2) `no_repeat_ngram_size`
- **作用**:避免生成重复的 n-gram。
- **建议**:通常设置为 **2 或 3**,避免生成重复内容。
---
### 3. **其他参数**
#### (1) `do_sample`
- **作用**:是否使用采样策略。
- **建议**:Top-K Sampling 必须设置为 **`True`**。
#### (2) `early_stopping`
- **作用**:是否在生成满足条件的序列时提前停止。
- **建议**:可以设置为 **`True`**,以节省计算资源。
**示例代码**
以下是一个典型的 Top-K Sampling 参数设置示例:
output = model.generate(
input_ids, # 输入序列
max_length=50, # 最大长度
min_length=10, # 最小长度
do_sample=True, # 启用采样
top_k=50, # 限制候选词范围
temperature=0.9, # 温度参数
no_repeat_ngram_size=2, # 避免重复 n-gram
num_return_sequences=3, # 返回的序列数量
early_stopping=True, # 提前停止
)
参数设置总结
| 参数 | 建议值/范围 | 说明 |
|-----------------------|------------------------------|----------------------------------------------------------------------|
| `top_k` | 50-100 | 限制候选词范围,避免选择概率极低的词。 |
| `max_length` | 任务相关(如 50-150) | 生成序列的最大长度,根据任务需求设置。 |
| `min_length` | 任务相关(如 10-20) | 生成序列的最小长度,避免生成过短的结果。 |
| `num_return_sequences`| 1-5 | 返回的序列数量,根据需求设置。 |
| `temperature` | 0.7-1.0 | 控制随机性,值越小越确定,值越大越多样。 |
| `no_repeat_ngram_size`| 2 或 3 | 避免生成重复的 n-gram。 |
| `do_sample` | `True` | 启用采样策略。 |
| `early_stopping` | `True` 或 `False` | 是否提前停止生成,以节省计算资源。 |
Nucleus Sampling: Dynamically choose the number of K (sort of)|核采样Top-P:动态选择K的数量
Nucleus Sampling也就是Top-P采样,其实是引入累计函数分布的Top-K采样。从一个概率池子(可以联系二八定律,20%的词贡献了80%的概率)中采样,设置累计概率阈值,比如p=0.92, 至于p中包含了多少个词,是根据t情况而变化的,这样就形成了是自适应选词的效果。
当候选词的概率分布高度集中时,Top-p和Top-k采样行为相似。当候选词的概率分布较为均匀时,Top-p采样会自动增加候选词的数量,以确保累积概率达到设定的阈值p。这使得生成的文本更具多样性,而Top-k采样可能会因为固定的选择数量而错过一些有潜力的候选词。
import torch
# 样例:probs: tensor([[0.2559, 0.5154, 0.0571, 0.1716]])
probs = torch.tensor([[0.2559, 0.5154, 0.0571, 0.1716]])
#- 这是原始的概率分布
#- 四个数字分别代表四个不同标记的概率
#- 总和为1(0.2559 + 0.5154 + 0.0571 + 0.1716 = 1)
# 第一步进行排序
probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)
# 结果
probs_sort: tensor([[0.5154, 0.2559, 0.1716, 0.0571]])
probs_idx: tensor([[1, 0, 3, 2]])
#- `probs_sort`: 概率按从大到小排序
#- `probs_idx`: 对应的原始位置索引
# - 1: 0.5154 原来在位置1
# - 0: 0.2559 原来在位置0
# - 3: 0.1716 原来在位置3
# - 2: 0.0571 原来在位置2
# 第二步概率的累积和
probs_sum = torch.cumsum(probs_sort, dim=-1)
# 结果
probs_sum: tensor([[0.5154, 0.7713, 0.9429, 1.0000]])
#- 0.5154 = 0.5154
#- 0.7713 = 0.5154 + 0.2559
#- 0.9429 = 0.5154 + 0.2559 + 0.1716
#- 1.0000 = 0.5154 + 0.2559 + 0.1716 + 0.0571
# 第三步找到第一个大于阈值p的位置,假设p=0.9,并将后面的概率值置为0:
mask = probs_sum - probs_sort > p
probs_sort[mask] = 0.0
# 结果
probs_sort: tensor([[0.5154, 0.2559, 0.1716, 0.0000]])
#- 保留了累积概率和小于0.9的值
#- 最后一个值被置为0,因为加上它会超过阈值0.9
# 第四步复原原序列
new_probs = probs_sort.scatter(1, probs_idx, probs_sort)
# 结果
new_probs: tensor([[0.2559, 0.5154, 0.0000, 0.1716]])
#- 使用`scatter`操作将排序后的概率值放回原始位置
#- 0.2559 回到位置0
#- 0.5154 回到位置1
#- 0.0000 回到位置2
#- 0.1716 回到位置3
# 注:在真实实现中一般会把舍弃的概率置为-inf,即
zero_indices = (new_probs == 0)
new_probs[zero_indices] = float('-inf')
# 结果
new_probs: tensor([[0.2559, 0.5154, -inf, 0.1716]])
#- 将概率为0的位置替换为负无穷
#- 这样在后续采样中会完全排除这些位置
#- 只会从非-inf的位置中进行采样
# 完整代码
def sample_top_p(probs, p):
probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)
probs_sum = torch.cumsum(probs_sort, dim=-1)
mask = probs_sum - probs_sort > p
probs_sort[mask] = 0.0
new_probs = probs_sort.scatter(1, probs_idx, probs_sort)
zero_indices = (new_probs == 0)
new_probs[zero_indices] = float('-inf')
return new_probs
这个过程实现了 nucleus sampling (top-p),通过累积概率和的方式来过滤掉低概率的选项,保持文本生成的多样性的同时确保质量。Top-p(nucleus)采样通过累积概率实现K值的自适应变化,是一种非常精巧的方法,具有以下优势:
1、自适应灵活性:通过选择累积概率超过阈值p的最小单词集合,Top-p采样能够根据概率分布动态调整候选词的数量(K值)。这种自适应性使得模型在概率分布较为集中时考虑较少的高概率词,而在分布较为均匀时考虑更多的词。
2、自然流畅性和连贯性:Top-p采样的自适应特性确保了生成文本的连贯性和自然流畅性。它避免了固定Top-k采样的僵化性,后者可能会不必要地包含低概率词。
3、高效的资源利用:虽然对概率进行排序可能计算量较大,但现代GPU能够高效处理这一任务。此外,近似排序或堆维护等优化方法可以进一步提升性能,而不会显著影响准确性。
4、多样性与创造性的控制:通过调整p值,可以平衡生成文本的多样性和连贯性。较高的p值包含更多词,增加多样性;而较低的p值则限制选择范围,专注于更高概率的词。
在具体实现中,Top-p采样的过程包括生成概率分布、对概率进行排序、计算累积和、确定超过阈值的点,并从选定的子集中进行采样。这种方法在GPT-2论文中被提出,因其在处理不同上下文场景时的自适应性和灵活性而受到青睐。
Top-P Sampling(也称为 **Nucleus Sampling**)是一种常用的生成策略,通过限制模型在生成每个词时仅从累积概率超过 `p` 的候选词中选择,从而在生成质量和多样性之间取得平衡。
以下是 Top-P Sampling 策略下 `model.generate()` 的常用参数设置建议。
### 1. **核心参数**
#### (1) `top_p`
- **作用**:限制候选词的范围,仅从累积概率超过 `p` 的词中采样。
- **建议**:
- 通常设置为 **0.9-0.95**。
- 较小的值(如 0.8)会限制候选词范围,生成结果更确定。
- 较大的值(如 0.98)会增加候选词范围,生成结果更多样。
#### (2) `max_length`
- **作用**:生成序列的最大长度。
- **建议**:根据任务需求设置,避免过长或过短。
- 例如,文本摘要任务可以设置为 **50-100**,对话生成任务可以设置为 **100-150**。
#### (3) `min_length`
- **作用**:生成序列的最小长度。
- **建议**:避免生成过短的结果,例如在摘要任务中可以设置为 **10-20**。
#### (4) `num_return_sequences`
- **作用**:返回的最终序列数量。
- **建议**:根据需求设置,通常设置为 **1-5**。
---
### 2. **多样性控制参数**
#### (1) `temperature`
- **作用**:控制生成结果的随机性。
- `temperature < 1`:更确定性的输出。
- `temperature > 1`:更多样化的输出。
- `temperature = 1`:无偏好的原始概率分布。
- **建议**:通常设置为 **0.7-1.0**,与 `top_p` 结合使用效果更好。
#### (2) `no_repeat_ngram_size`
- **作用**:避免生成重复的 n-gram。
- **建议**:通常设置为 **2 或 3**,避免生成重复内容。
---
### 3. **其他参数**
#### (1) `do_sample`
- **作用**:是否使用采样策略。
- **建议**:Top-P Sampling 必须设置为 **`True`**。
#### (2) `early_stopping`
- **作用**:是否在生成满足条件的序列时提前停止。
- **建议**:可以设置为 **`True`**,以节省计算资源。
**示例代码**
以下是一个典型的 Top-K Sampling 参数设置示例:
output = model.generate(
input_ids, # 输入序列
max_length=50, # 最大长度
min_length=10, # 最小长度
do_sample=True, # 启用采样
top_p=0.95, # 限制候选词范围
temperature=0.9, # 温度参数
no_repeat_ngram_size=2, # 避免重复 n-gram
num_return_sequences=3, # 返回的序列数量
early_stopping=True, # 提前停止
)
参数设置总结
| 参数 | 建议值/范围 | 说明 |
|-----------------------|------------------------------|----------------------------------------------------------------------|
| `top_p` | 0.9-0.95 | 限制候选词范围,仅从累积概率超过 `p` 的词中采样。 |
| `max_length` | 任务相关(如 50-150) | 生成序列的最大长度,根据任务需求设置。 |
| `min_length` | 任务相关(如 10-20) | 生成序列的最小长度,避免生成过短的结果。 |
| `num_return_sequences`| 1-5 | 返回的序列数量,根据需求设置。 |
| `temperature` | 0.7-1.0 | 控制随机性,值越小越确定,值越大越多样。 |
| `no_repeat_ngram_size`| 2 或 3 | 避免生成重复的 n-gram。 |
| `do_sample` | `True` | 启用采样策略。 |
| `early_stopping` | `True` 或 `False` | 是否提前停止生成,以节省计算资源。 |
参考文章
[1] https://www.zhihu.com/tardis/zm/art/647813179?source\_id=1005