Barthez模型论文解读,并基于MindSpore NLP推理复现
Barthez模型论文解读,并基于MindSpore NLP推理复现
作者:北辰星 来源:知乎
Barthez模型概述
Barthez是第一个法语BART模型,其在一个非常大的法语单语语料库上进行了预训练,与现有的基于BERT的法语模型(如CamemBERT和FlauBERT)不同,BARThez特别适合生成任务,因为它的编码器和解码器都经过了预训练。除了FLUE基准测试中的区分任务,本文中发布了一个新颖的摘要数据集OrangeSum,并对BARThez进行了评估。最终得到的模型mBARTHez在性能上显著优于普通的BARThez,并且与CamemBERT和FlauBERT相当或更胜一筹。
论文创新点
在聊BARThez模型之前,我们需要知道,什么是BART模型。近年来,ChatGPt的问世引发了大模型的热潮,而ChatGPT是基于Transformer架构的,但transformer架构所衍生出来的技术路线不仅仅只有ChatGPT这一条路线,主要有三种,分别是GPT路线,BART路线,BERT路线。
GPT路线是OpenAI公司研发的自回归路线,现在已经取得了非常大的成功,BERT路线是自编码路线,是Google公司研发,BART路线,则是结合了这两者,即自回归+自编码路线。而BARThez模型,则是这BART模型的一个分支,一个法语训练的BART模型。
基于BERT的法语模型早先就已有CamemBERT,FlauBERT这两个模型,且都具有比较好的模型性能,但基于BART的法语模型却一直没有问世,所以本文训练了第一个BART法语模型BARThez,并且在本文提出的法语数据集OrangeSum上也表现出了比较优异的性能。
同时,本文在在Bart模型的基础上,又使用了Barthez模型的语料库进行预训练,最终得到了一个性能显著优于mBarthez的模型,比基于BERT的最先进的语言模型CamemBERT和FlauBERT相当或更胜一筹。
数据集上的指标评价得分
01
生成任务
本文中使用了四个模型来进行生成任务作为对比,分别是BARThez、mBART、mBARThez、Random,其模型相关信息如下表所示。
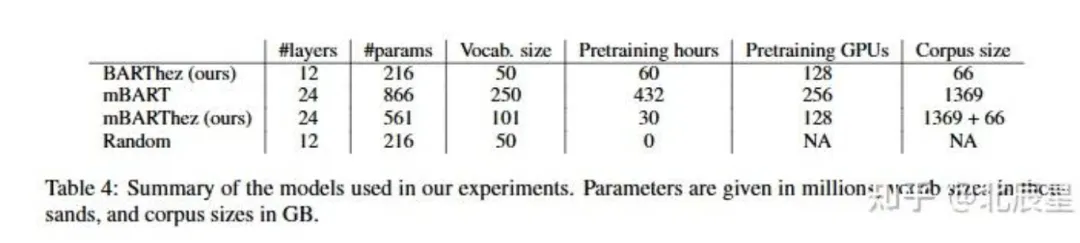
在本文推出的OrangeSum数据集上分别进行摘要生成和标题生成两个任务,使用ROUGE-1、ROUGE-2和ROUGE-L分数作为指标,而由于ROUGE在抽象摘要中不适用,所以又加入了BERTScore分数,其运行对比结果在下表。
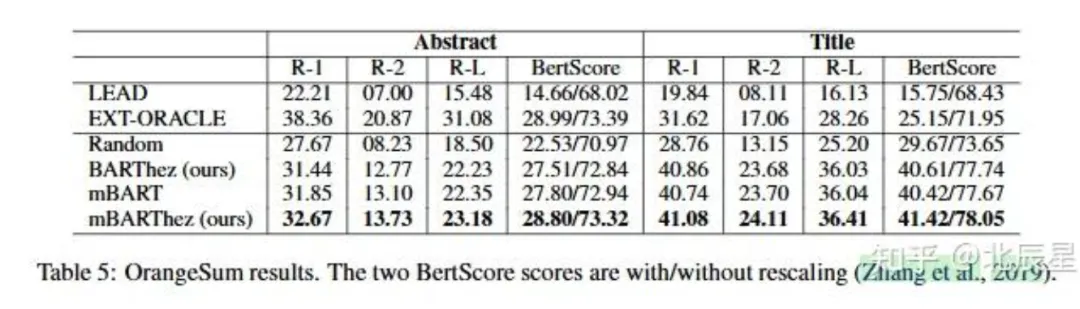
从结果上看,BARThez模型虽然和mBART模型的ROUGE分数和BERTScore分数差不多,但是要注意到这两个模型之间的参数差别,mBART模型的参数比BARThez模型的参数多了整整四倍。而mBARThez则在所有指标上都达到了最优,体现了在微调之前将多语言预训练模型适应特定语言的重要性。
02
识别任务
识别任务中,适用评估框架FLUE,FLUE是一个用于法语自然语言处理系统的评估框架,类似于流行的GLUE基准。其目标是促进未来可重复的实验,并共享法语领域的模型和进展。(
https://link.zhihu.com/?target=https%3A//github.com/getalp/Flaubert/tree/master/flue)
FLUE框架中,包含三个数据集,分别是CLS、PAWSX、XNLI。其中,CLS数据集任务是预测评论的态度是表扬还是批评,PAWSX数据集任务是判断两句话是否语义等价,XNLI数据集任务是推测第一个句子是否蕴含第二个句子。最终运行结果如下。
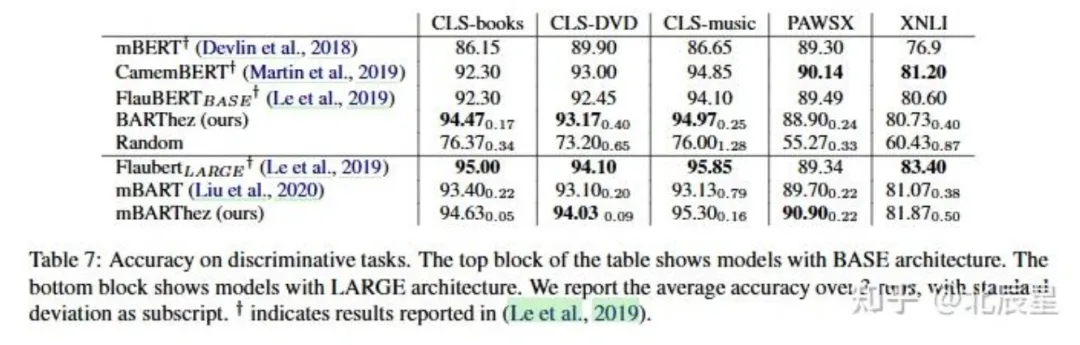
从结果上来看,BARThez在三个情感分析任务中超越了其他模型,而在释义和推理任务中则与CamemBERT和FlauBERT非常接近。在LARGE模型中,mBARThez在所有任务中都优于mBART,再次显示了预训练阶段的语言适应阶段的重要性。
在5个任务中的3个任务中,FlauBERT比mBARThez略有优势,这可能是因为FlauBERT在单语法语语料库上训练的时间大约是mBARThez的10倍。总的来说,BARThez和mBARThez在生成任务上的出色表现并不会导致它们在判别任务上的性能下降。
创新点优势
1、BARThez模型基于BART架构,通过多语言预训练,使其在处理多种语言任务时具有优势。多语言预训练使得模型能够更好地理解和处理不同语言之间的差异和共性,从而提高了模型的泛化能力和性能。
2、BARThez模型在预训练阶段加入了语言适应性预训练,即在多语言预训练的基础上,继续使用特定语言的语料库进行预训练。这种预训练方法使得模型能够更好地适应特定语言的任务,从而提高了模型的性能。
3、BARThez模型不仅具有强大的编码能力,还具有强大的解码能力,这使得它特别适合于生成任务,如摘要生成。BART架构的这种双向编码和解码的能力,使得模型能够更好地理解和生成自然语言文本。
使用MindSpore NLP对数据集进行推理验证
首先是需要找到与官方相同的数据集,这里我采用了FLUE中提供的数据集,让BARThez模型在CLS数据集上进行文本情感预测。数据集对应链接在下方,需要注意的是,CLS数据集并不对外公开,需要进行申请才能获得使用资格,所以这个只提供链接,不提供数据集文件。如果想要获取数据集,可以点击链接,提交数据集使用申请。
https://zenodo.org/records/3251672
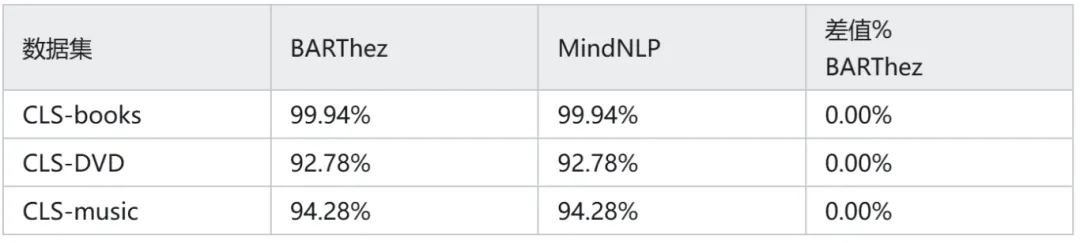
为了验证BARThez模型的效果,我们选取了CLS-,并在数据集上进行了验证评估,最终在CLS-books数据集上得到的正确率为99.94%,与官方给出的结果94.47%相差较大,这里推测是官方模型在CLS-books数据集上可能出现了数据泄露,故而正确率比较高,接近100%。而其他数据集与官方误差小于2%。同时我们也使用了官方给出的Transformers模型与MindSpore NLP模型进行了对比,官方模型与MindSpore NLP在小数点后两位精度的误差为0.00%,其具体对比结果如下:
完整代码
数据集预处理代码,需要将数据集放入同一目录下,会生成books、dvd、music三个文件夹,每个文件夹内包含对应的数据集。由于代码比较长,完整代码请详见如下给出gitee仓库链接。
https://gitee.com/chenjian2024/barthez-mind-nlp/tree/master/
模型推理核心代码:
import numpy as np
from mindnlp.transformers import AutoTokenizer,AutoModelForSequenceClassification
import mindspore
barthez_tokenizer = AutoTokenizer.from_pretrained("moussaKam/barthez")
barthez_model = AutoModelForSequenceClassification.from_pretrained("moussaKam/barthez-sentiment-classification")
def predict_sentiment(text):
input_ids = mindspore.tensor(
[barthez_tokenizer.encode(text, add_special_tokens=True)]
)
predict = barthez_model.forward(input_ids)[0]
return predict.argmax().item()
总结
BARThez模型是第一个专为法语设计的BART模型,它通过在大型法语语料库上进行预训练,并在两个抽象摘要任务上进行评估,展示了与mBART模型相当的竞争力,同时具有更少的参数。此外,通过在预训练阶段添加一个相对便宜的语言适应阶段,mBARThez模型在多个判别任务上提供了显著的性能提升。
MindSpore NLP中提供了与huggingface相同的操作接口,加载、评估和训练模型非常直接高效,在有huggingface使用经验的情况下,学习成本非常低,非常推荐使用MindSpore NLP。