BARTpho模型论文解读,并基于MindSpore NLP推理复现
BARTpho模型论文解读,并基于MindSpore NLP推理复现
作者:paff 来源:知乎
BARTpho模型概述
BARTpho包含两个版本:BARTphosyllable 和 BARTphoword,他们是首个公开的针对越南语的单语言大规模序列到序列预训练模型。BARTpho 使用了 BART 的"large"架构以及序列到序列去噪自编码器的预训练方案,因此特别适用于生成式NLP任务。
论文创新点
本文的创新点如下:
- 首个针对越南语的大规模单语言序列到序列预训练模型
- 专为越南语设计,填补了越南语声称是自然语言处理任务预训练模型的空白
2. 适配越南语的预训练设计
- 针对越南语的特点,分别设计了基于音节(BARTphosyllable)和基于单词(BARTphoword)的两种版本
3. 在多个越南语下游任务上的表现显著提升
- 在越南语文本摘要任务中,BARTpho的ROUGE分数和人工评估分数均强于mBART;在越南语大写和标点恢复任务中,BARTpho的性能也显著优于mBART。
数据集上的指标评价得分
01
文本摘要生成
本文评估并比较了BARTpho与基线模型mBART在越南语文本摘要这一任务中的性能。使用单文档摘要数据集VNDS进行实验,该数据集包含150704篇新闻文章,每篇文章包括一个新闻摘要和正文。由于该数据集中存在重复文章,本文对数据集进行了去重。
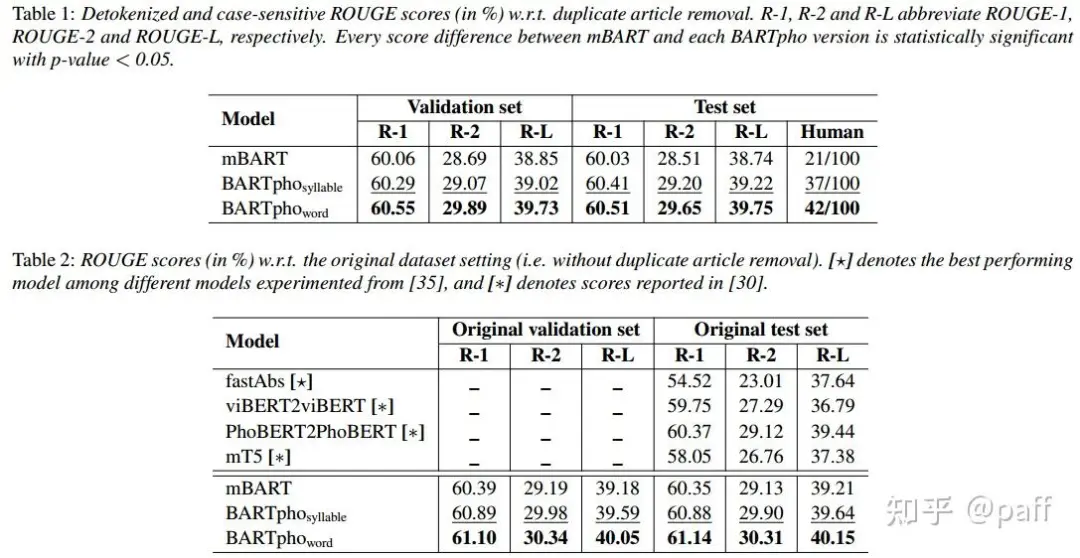
表1 显示了去重之后,mBART和BARTpho的ROUGE分数。显然,两种BARTpho版本在验证集和测试集上都显著优于mBART。除此以外,本文还随机抽取了100个案例进行基于人工的评估。在人工评估中,BARTpho的表现依然优于mBART。表2 显示了在未去重数据集上的结果。表 1 和表 2 的自动评估和人工评估结果证明了基于 BART 的大规模单语言 seq2seq 模型对越南语的有效性。
02
大写和标点符号恢复
表 3 显示了 BARTpho 和 mBART 在大写任务上的结果。BARTpho 的表现优于 mBART,具体来说,BARTphoword 和 BARTphosyllable 的 F1 分数分别比 mBART 高 1.1% 和 0.7%。表 3 同时展示了 BARTpho 和 mBART 在标点恢复任务上的结果。两种 BARTpho 版本在逗号和问号类型上都优于 mBART,特别是在问号标点上性能差距显著。

相比其他工作的优势
01
专注于越南语的单语言序列到序列预训练
此前大部分相关工作(如 mBART 和 mT5)主要针对多语言模型,未专注于越南语。由于越南语的语言特点(如音节和单词的特殊性),本文通过分词策略(音节级与单词级)探索了如何更好地为越南语优化 seq2seq 模型,解决了多语言模型无法充分利用越南语语言特性的局限性。
02
性能显著提升
在越南语单文档文本摘要任务中,BARTpho 在自动评估(ROUGE 分数)和人工评估中均超过了强基线 mBART;在越南语大写与标点符号恢复任务中,BARTpho 的性能也全面优于 mBART,尤其在问号和逗号标点符号的恢复上展现了更大的性能提升。
03
专用模型的高效性
即便训练数据量远小于多语言模型,BARTpho 的性能仍然优于 mBART。
基于MindSpore NLP复现
对于文本摘要生成任务,通过查阅本文的参考文献,我找到了文中提到的VNDS数据集。数据集对应链接在下方,该数据集完全公开,可自由下载。而对于大写和标点符号恢复任务,本文使用的测试数据是根据现有数据集生成的,且并未公开,这里无法验证。因此只能尝试文本摘要生成任务。
- VNDS数据集:
https://github.com/ThanhChinhBK/vietnews
在验证本文的工作过程当中,发现文章对于摘要生成的具体参数设置描述不完整,仅提到了输入大小为512,没有说明输出大小应固定在什么范围,且文中的去重后的数据集也未公开。因此这里用去重前的测试数据集,设置输入大小为512,输出为50进行实验。使用官方给出的TransFormers模型与MindSpore NLP模型进行了对比,官方模型与MindSpore NLP在小数点后两位精度的误差为0.00%。
Model
R-1
R-2
R-L
BARTpho-syllable
(TransFormers)
0.4324
0.1434
0.2982
BARTpho-syllable
(MindSpore NLP)
0.4324
0.1434
0.2982
基于MindSpore NLP复现完整代码: