开源之夏系列 | 基于大规模预训练语言模型的单细胞类型注释和测序干扰预测算法实践应用
开源之夏系列 | 基于大规模预训练语言模型的单细胞类型注释和测序干扰预测算法实践应用
开源之夏,是由中国科学院软件研究所发起,专为高校学生精心打造的活动。旨在鼓励广大学子积极参与开源软件的开发与维护,推动优秀开源软件社区的蓬勃发展。
目前,开源之夏2024已圆满结项!在本届开源之夏中,不少开发者跟随昇思MindSpore一起,在开源的世界里畅游,成功完成项目任务。在此,昇思 MindSpore 开源社区邀请了开源之夏的开发者们,分享他们在本次活动中的宝贵经验与心得。我们希望通过这些精彩的项目经历和实战技巧,能够激发更多创意火花,帮助大家提升技术能力。本文为昇思MindSpore 开源之夏项目经验分享系列第6篇。

项目基本介绍
1、项目名称:基于大规模预训练语言模型的单细胞类型注释和测序干扰预测算法实践应用
2、项目导师:段鹏飞
3、项目链接:https://summer-ospp.ac.cn/org/prodetail/24c6d0548?list=org&navpage=org
4、项目描述:本项目旨在通过使用 AnnData 数据结构和多个单细胞 RNA 测序数据集,进行单细胞类型注释与干扰建模。数据主要来自 CELLxGENE、Replogle 和 Norman 等数据集,将利用 scBERT 、 scGen 和 sams-vae 等迁移学习模型进行分析。项目将搭建在 MindSpore 平台上,以便于大规模预训练和模型优化。实施步骤包括环境准备、模型分析、网络搭建和调试调优,确保模型在新框架中高效、准确运行。最终目标是提升单细胞数据的分析能力,为生物医学研究提供支持。
项目选择初衷
选择这个项目的原因可能是因为它具有广泛的应用前景,尤其在生物学和医学领域。单细胞转录组学能够提供细胞的详细信息,帮助我们更好地理解细胞的类型和功能,揭示疾病的机制,探索潜在的治疗方法和药物靶点。而现有的分析方法往往存在效率和准确性方面的挑战,因此开发高效、精准的算法,可以大大推动这一领域的科研和应用进展。此外,这类项目也有助于推动个性化医疗和精准医学的发展,具有重要的社会和经济价值。
项目方案介绍
本项目旨在通过大规模预训练语言模型(如scBERT、scGen和sams-vae)实现单细胞转录组数据的类型注释和干扰预测。该项目基于MindSpore平台,使用CELLxGENE、Replogle和Norman等多个单细胞RNA测序数据集,应用迁移学习方法提高模型的分析能力。项目的主要任务包括环境准备、模型设计与分析、迁移训练与推理模块的实现,最终目标是提升单细胞数据分析的准确性与效率,为生物医学研究提供有力支持。
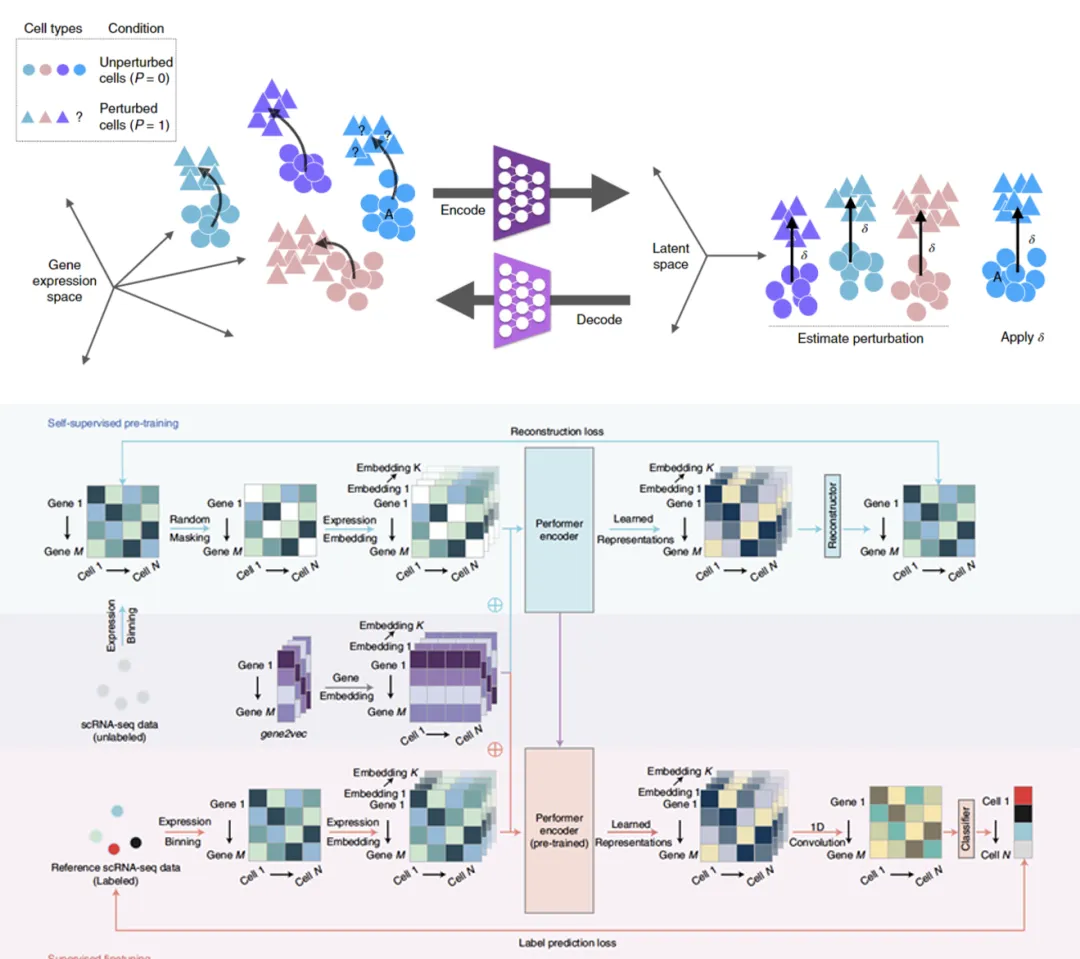
scGen以及scBERT框架
scBERT初步设想的架构图
scGen初步设想的架构图
如果要迁移模型,我们需要做到以下7点:
01
分布式训练的初始化
在 PyTorch 中,设备的选择是通过 torch.cuda.set_device() 来指定每个进程使用的 GPU 设备,并通过 torch.device() 将设备分配给变量 device,而在 MindSpore 中,这部分操作则通过 ms.set_context() 来指定设备。对于分布式训练,PyTorch 使用 torch.distributed.init_process_group() 进行初始化,而 MindSpore 则对应使用 mindspore.communication.init(),并且通过 get_group_size() 和 get_rank() 替代 PyTorch 的 get_world_size() 和 get_rank() 来获取分布式环境中的进程数量和当前进程的 rank。PyTorch 中可以直接通过导入 DDP(DistributedDataParallel)实现数据并行,而在 MindSpore 中则不能直接导入,取而代之的是使用 set_auto_parallel_context() 提供类似的并行控制机制。在 MindSpore 中,我选择了 Pipeline 流水线并行或数据并行两种模式来替代 DDP 实现分布式训练,并且增加了非分布式的模式。PyTorch 使用 seed_all() 为每个进程设置独立的随机数种子,而 MindSpore 则使用 ms.set_seed(),该函数会将种子应用到框架内所有的随机操作中。最后,MindSpore 中的 ms.set_context() 还可以指定 Ascend 设备的内存限制。

02
数据加载与预处理
首先自定义了一个数据集,在 PyTorch 中,SCDataset 继承自 torch.utils.data.Dataset,而在 MindSpore 中,没有 Dataset 类继承,只能使用 GeneratorDataset 来封装数据集。数据在 PyTorch 中通过 torch.from_numpy() 转换为 PyTorch 张量并发送到指定设备 (device) 上,而在 MindSpore 中,则使用 mindspore.Tensor() 替代 torch.from_numpy(),且无需显式指定设备,因为 MindSpore 会自动处理设备分配。SCDataset 类的构造函数在 PyTorch 中仅接收 data 参数,而在 MindSpore 中增加了 n_class 和 seq_len 两个参数,以指定类别数量和序列长度,从而提高数据集的灵活性,能够根据不同设置调整类别数和序列长度。在数据提取方面,PyTorch 使用 random.randint() 随机获取起始点并从该位置开始提取数据,而 MindSpore 则通过直接索引获取指定位置的数据,且返回数据的长度被限制为 seq_len。在数据加载和分布式数据采样方面,PyTorch 使用 DataLoader 和 DistributedSampler,而 MindSpore 则使用 GeneratorDataset 替代 DataLoader 来加载数据,并支持数据并行(DP)模式,通过 num_shards 和 shard_id 实现分片。为了支持分布式训练,MindSpore 使用 to_mind_dataset() 方法替代 DistributedSampler 实现数据并行功能,利用 mindspore.dataset.GeneratorDataset 生成数据集,并根据是否启用数据并行 (DP=True/False) 选择是否对数据集进行分片,通过 get_group_size() 和 get_rank() 实现数据分片。在批次处理方面,PyTorch 的 DataLoader 直接指定 batch_size 参数,而 MindSpore 则通过 to_mind_dataset 方法将数据转换为 GeneratorDataset,并在调用时指定 batch_size 和 DP。整体而言,MindSpore 在数据集封装、设备分配、数据并行及批次处理等方面与 PyTorch 有显著的不同,提供了其特有的实现方式以支持分布式和非分布式的训练模式。

03
掩码函数
在代码迁移过程中,torch.zeros_like(t).float().uniform_(0, 1) 被替换为 ops.uniform,因为 ops.uniform 可以直接生成介于 (0, 1) 之间的浮点数矩阵,无需额外的 .float() 转换;torch.full_like 被替换为 ops.full_like,且在 MindSpore 中生成的布尔矩阵类型为 ms.uint8,而在 PyTorch 中为 torch.bool。返回类型方面,MindSpore 中返回的 mask 被转换为 Tensor(mask, dtype=ms.uint8),而 PyTorch 中直接返回布尔类型的 mask。在设备管理方面,PyTorch 的张量可以通过 mask.device 获取设备信息并指定后续操作的设备,而 MindSpore 默认操作不涉及设备的直接指定和管理,设备通常在上下文配置时统一设置,因此代码中移除了设备管理部分。PyTorch 中的 torch.cat() 和 torch.arange() 被替换为 MindSpore 的 ops.cat() 和 ops.arange(),torch.rand.masked_fill 被 ops.rand.masked_fill 替代。PyTorch 中的 scatter 操作用于根据索引修改张量,而在 MindSpore 中,ops.ones() 生成的张量类型需要显式指定。MindSpore 使用 ops.Cast() 对数据类型进行转换,而 PyTorch 则使用 .bool() 直接转换为布尔类型。此外,PyTorch 中的 torch.zeros 生成张量的方式在 MindSpore 中使用 ops.zeros 替代,rand.topk() 操作在两个框架中虽然类似,但 API 存在微小差异。

04
掩码机制与数据增强
在随机数生成方面,PyTorch 的 torch.randint 被替换为 MindSpore 的 ops.randint 用于生成随机数;获取非零元素时,torch.nonzero 被替换为 ops.nonzero。在掩码填充过程中,MindSpore 需要通过 ops.Cast() 将布尔类型转换为 MindSpore 的布尔张量类型。此外,在 MindSpore 中不需要显式指定设备,设备的分配由框架自动处理。

05
训练过程
在训练循环中,PyTorch 使用 train_loader 的循环方式通过 enumerate 直接获取数据,而在 MindSpore 中则通过 train_dataloader.create_tuple_iterator() 来获取数据。对于张量操作,PyTorch 中的 logits.transpose(1, 2) 被替换为 MindSpore 中的 ops.softmax 和 ops.argmax。在梯度累积方面,PyTorch 使用 with model.no_sync() 来实现梯度累积,并在每次累积间隔后调用 backward() 和 optimizer.step(),而 MindSpore 则不再需要 no_sync 的概念,框架会自动处理并行时的梯度同步。精度计算方面,PyTorch 直接使用 torch.true_divide 来计算正确预测的比例,而在 MindSpore 中则使用 ops.mul() 及其他操作来计算 correct_num 和 val_num。为了确保所有节点的操作一致,PyTorch 通过 dist.barrier() 来同步进程,而 MindSpore 则通过 pp_grad_reducer 来处理并行的梯度同步。在学习率更新方面,PyTorch 使用 scheduler.step() 来调整学习率,而在 MindSpore 中则使用 lr_schedule 函数来控制学习率的更新,并将新的学习率分配给 optimizer.learning_rate。整体而言,MindSpore 在训练数据迭代、张量操作、梯度累积与同步、精度计算以及学习率调度等方面与 PyTorch 存在显著差异,提供了其特有的实现方式以支持高效的分布式训练。

06
验证结果
在模型评估过程中,PyTorch 使用 model.eval() 将模型设置为评估模式,从而关闭 dropout 和 batch normalization 的影响,而在 MindSpore 中,等效的方法是使用 model.set_train(False)。PyTorch 中通过 torch.no_grad() 来关闭梯度计算,而 MindSpore 默认在验证过程中不会计算梯度,因此无需显式调用该步骤。此外,PyTorch 需要显式调用 data.to(device) 将数据移动到 GPU 或 CPU,而 MindSpore 则自动处理设备管理,无需手动指定。在张量操作方面,PyTorch 的 nn.Softmax(dim=-1) 被替换为 MindSpore 的 ops.softmax 操作,维度操作如 .transpose 在 MindSpore 中需要使用 ops.repeat_elements、ops.reshape() 和 ops.cast 来实现。对于最终的预测结果,PyTorch 中的 final.argmax(dim=-1) 被 MindSpore 的 ops.argmax(axis=-1) 所替代。在计算准确率时,PyTorch 通过张量比较 predictions == truths 来计算正确的数量,而在 MindSpore 中则使用 ops.mul 进行相应的计算。整体而言,MindSpore 在模型评估模式设置、梯度计算控制、设备管理以及张量操作等方面与 PyTorch 有显著的差异,提供了其特有的实现方式以支持高效的模型评估流程。

07
其他
在学习率、调度器与优化器方面,MindSpore 使用了指数衰减,而 PyTorch 则采用余弦退火,两者都使用了 Adam 优化器。在训练步骤中,MindSpore 将前向传播和梯度计算封装在 Grad_Fn 中,并使用 ms.value_and_grad 进行自动微分,而 PyTorch 则通过显式的 backward 和 step 方法来实现梯度计算和参数更新,这使得 MindSpore 的方式更加模块化和专业化,而 PyTorch 的方法则显得更加直观。此外,MindSpore 在 Train 函数中进行了封装,使其更易于扩展和修改,而 PyTorch 则在训练循环中直接计算损失并更新参数,适合快速的迭代开发。在判断主进程的逻辑上,MindSpore 将 is_master 替换为 get_rank() == 0,而在模型保存函数方面,MindSpore 使用 save_checkpoint 替代了 PyTorch 的 save_ckpt。总体而言,MindSpore 提供了更加封装和模块化的实现方式,便于扩展和分布式训练,而 PyTorch 则以其直观和灵活性适合快速开发和实验。

项目分析
在项目需求分析方面,首先需要支持处理大规模单细胞RNA测序数据,确保数据处理管道的高效性和模型的兼容性。技术难点主要集中在数据处理和平台迁移上,尤其是在迁移学习模型的选择与优化、MindSpore平台适配、以及不同模型间的协同工作上。此外,还需关注模型精度和推理性能,确保能够高效运行于大规模数据环境中。
项目实现思路
项目的实现思路包括从理论研究到实际操作的多阶段过程。首先,进行文献调研与数据集收集,理解scBERT、scGen和sams-vae等模型的原理和应用,搭建并配置MindSpore平台。接着,定义和构建模型架构,迁移训练和推理模块,并针对单细胞数据进行处理和分析。最后,进行单元测试和集成测试,优化训练过程,确保迁移后的模型能够高效、准确地运行。
最终方案
最终方案将确保单细胞数据分析的高效性和准确性,通过迁移学习模型的优化,提升数据的类型注释和干扰预测能力。在模型部署方面,采用MindSpore平台进行大规模训练和推理,确保系统能够在生产环境中稳定运行。整个项目将在数据处理、模型优化和性能调优方面达到最佳效果,并最终为生物医学研究提供精准的分析工具和方法。
项目总结
项目已经顺利完成,成功将基于大规模预训练语言模型的单细胞转录组数据分析算法迁移至MindSpore平台。具体而言,ScBERT模型已在公开单细胞RNA测序数据集PanglaoDB上完成测试,ScGen模型则在公开胰腺数据集Pancreatic上完成测试。两个模型的训练、测试和代码合并工作已圆满完成,且均通过了所有测试,确保了模型的高效性和准确性。项目的顺利完成提升了单细胞数据分析的能力,为生物医学研究提供了有力支持,推动了相关技术的实际应用和发展。
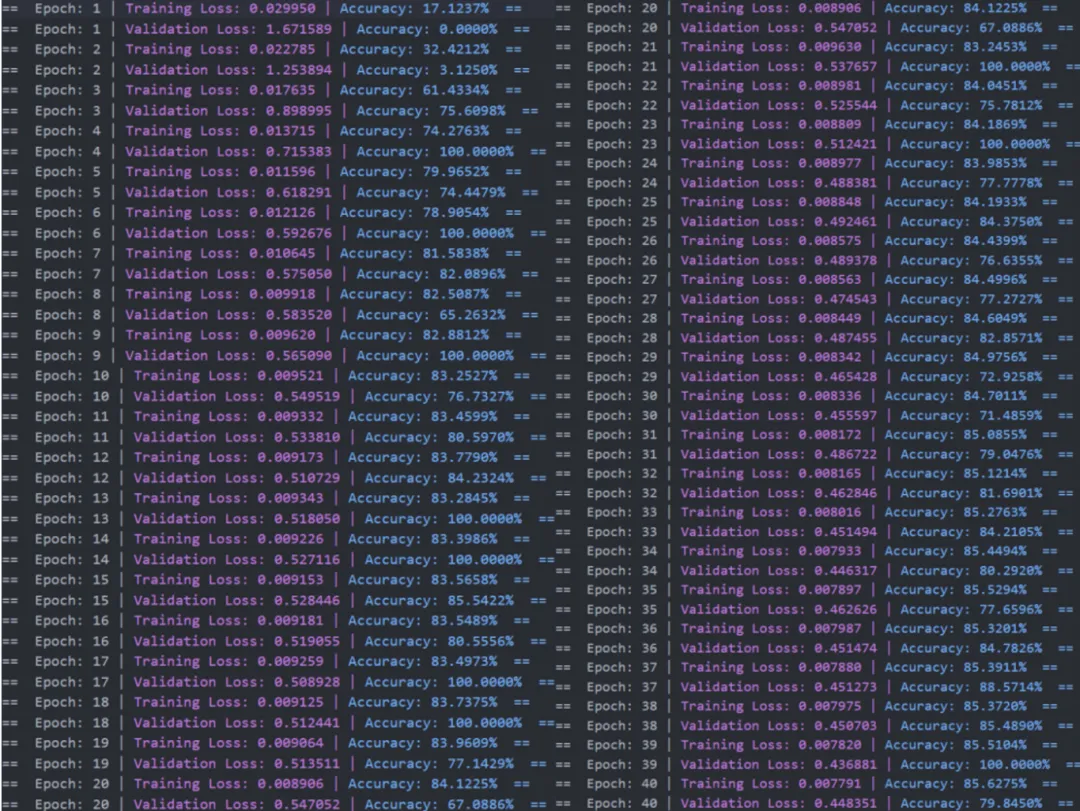
Scbert进行细胞注释的准确率
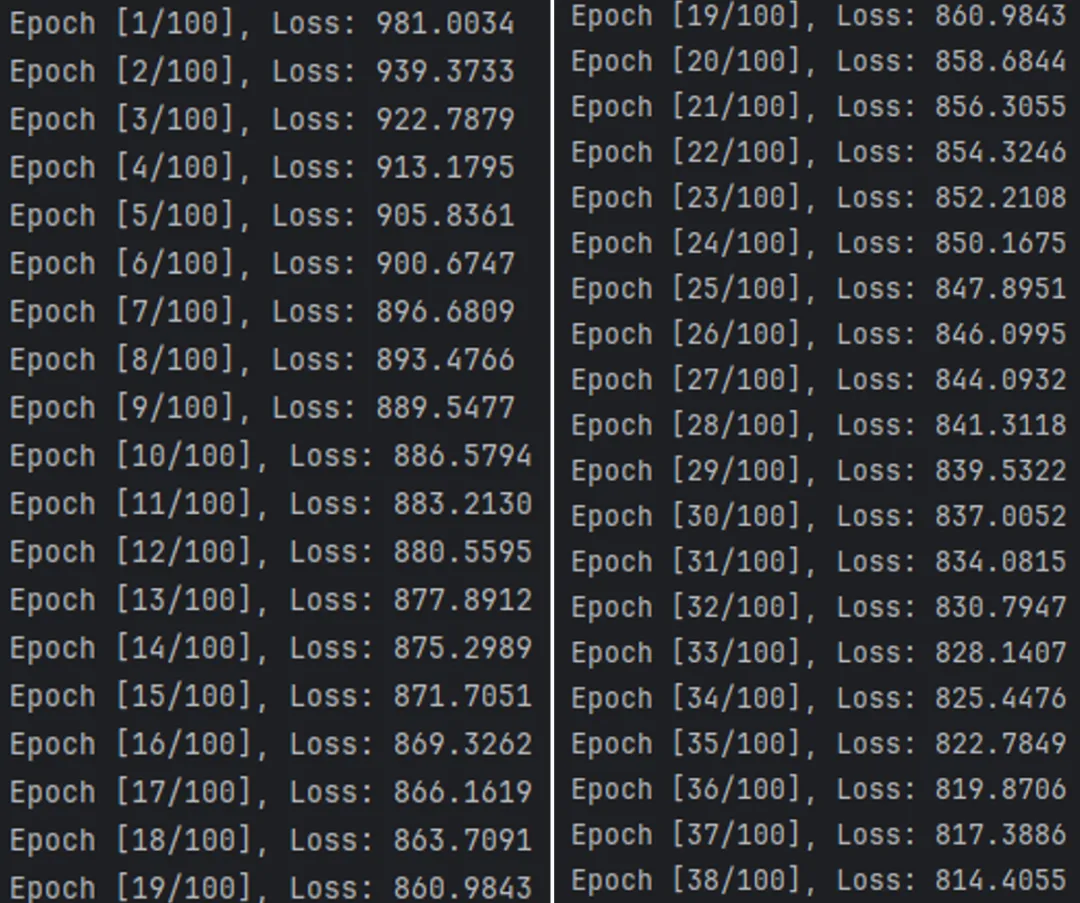
scGen训练阶段
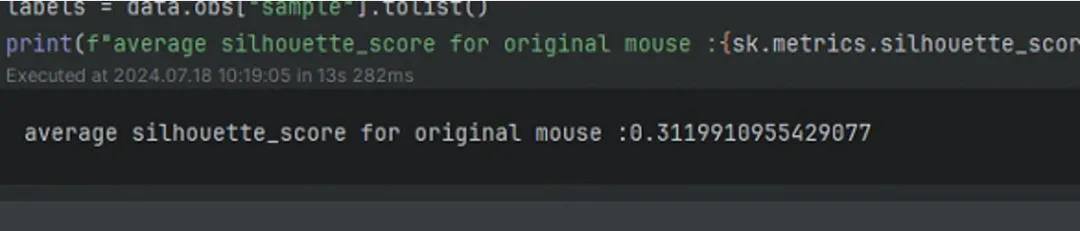
使用ASW对经过scgen去批次后的数据进行评估