基于MindSpore的香橙派AIpro实现垃圾回收AI识别方案一:如何快速实践昇思MindSpore大模型平台?
基于MindSpore的香橙派AIpro实现垃圾回收AI识别方案一:如何快速实践昇思MindSpore大模型平台?
**作****者:**完美记号
**原文链接:**https://www.hiascend.com/developer/blog/details/0272157975874351541
随着AI人工智能、机器学习的不断发展,开发者的编程领域也在经历着一场前所未有的变革,在这个过程中,各行各业都开始不断的发展,包括金融、医疗、教育、工业、游戏、法律等多个行业,以及智能硬件领域,如智能汽车、机器人、智能终端等。

作者也是经过了以上几个阶段的软件开发历程,从Web时代编程、到云时代分布式编程,到如今的AI时代,AI技术的发展还带动了相关行业的创新和转型,如人工智能和机器学习技术的不断进步和应用范围的扩大,推动了社会进步和技术革新。随着算法的改进和计算能力的提升,AI技术的准确性和效率也在不断增强,为各行各业的发展提供了新的动力和支持。
AI技术的发展为各个领域带来了许多创新和便利。那么,在实际的应用中,如何正确的来使用AI进行提高效率呢,值得大家来思考一下?今天给大家分享如何快速实践昇思MindSpore大模型平台,昇思MindSpore旨在实现易开发、高效执行、全场景统一部署三大目标,降低了AI开发者的开发门槛,非常适合各种场景的学习与实践,接下来,带大家一起来实际体验一下。
昇思MindSpore是什么?
昇思MindSpore是新一代覆盖端边云全场景的开源AI框架,旨在开创全新的AI编程范式,降低开发者门槛,为开发者打造开发友好、运行高效、部署灵活的AI框架,推动人工智能生态繁荣发展。昇思在致力于技术创新的同时,着力打造学习型社区环境,希望凝聚开发者力量共建社区,与开发者共同学习和成长。
自2020年3月28日开源以来,昇思MindSpore致力于围绕产品与产业界、学术界共建人工智能框架开源生态,成为框架新选择。目前已孵化、支持50+国内外主流大模型;开源版本已累计获得1100万次下载,覆盖全球133多个国家和地区的2400多个城市,共有3.7万多名开发者参与社区贡献;与360多所高校科研院所展开教学及科研合作,联合1700多位生态伙伴,打造了超过2000+解决方案。
如何快速实践昇思MindSpore大模型平台?
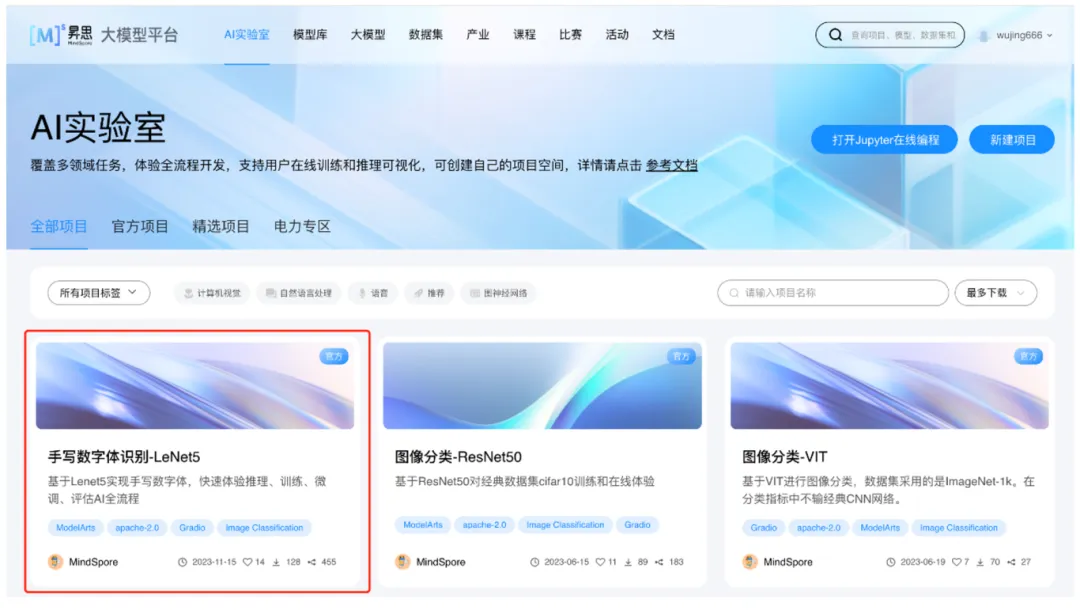
打开官方提供的示例:<<手写数字体识别-LeNet5>>
.
├── inference # 推理可视化相关代码
│ ├── app.py # 推理核心启动文件
│ ├── config.json # 推理权重文件配置
│ └── requirements.txt # 推理可视化相关依赖文件
└── train # 训练可视化相关代码
├── pip-requirements.txt # 训练相关依赖文件,必须和启动文件同一级
├── train_customize_aim.py # 自定义Aim训练代码,支持自定义评估
├── train_gridsearch.py # grid search + LossMonitor 训练代码,支持标准评估
|── train_valaccmonitor.py # ValAccMonitor训练代码,支持标准评估
└── train.py # LossMonitor训练代码,支持标准评估
注:建议将推理可视化相关的代码放在inference文件夹下,训练相关的代码放在train文件夹下。注意该项目下不能有lfs文件,否则会调度失败。
0****1
评估方式1——训练日志可视化:
# train.py,支持标准评估
...
from mindvision.engine.callback import LossMonitor
...
# 训练网络模型
model.train(10, dataset_train, callbacks=[ckpoint, LossMonitor(0.01, 1875)])
...
# train_gridsearch.py,支持标准评估
...
# 训练代码
def train(args_opt):
# grid search
batch_size_choice = [32, 64, 128]
learning_rate_choice = [0.01, 0.001, 0.0001]
momentum_choice = [0.9, 0.99]
for batch_size in batch_size_choice:
for learning_rate in learning_rate_choice:
for momentum in momentum_choice:
...
# LossMonitor or ValAccMonitor
model.train(20, dataset_train, callbacks=[ckpoint, LossMonitor(learning_rate, steps)])
...
0****2
评估方式2——自定义评估:
评估方式1的评估指标有限,你也可以自己写评估代码,跟踪你想要关注的指标。比如下例train_customize_aim.py中以自定义Callback+Aim 跟踪指标 的方式跟踪每个epoch之后训练集和测试集的acc。
```js
# train_customize_aim.py
...
from aim import Run
...
# 自定义Callback
class AimCallback(Callback):
def __init__(self, model, dataset_test, aim_run):
super(AimCallback, self).__init__()
self.aim_run = aim_run # 传入aim实例
self.model = model # 传入model,用于eval
self.dataset_test = dataset_test # 传入dataset_test, 用于eval test
def step_end(self, run_context):
"""step end"""
cb_params = run_context.original_args()
# loss
epoch_num = cb_params.cur_epoch_num
step_num = cb_params.cur_step_num
loss = cb_params.net_outputs
run1 = self.aim_run.track(float(str(loss)), name='loss', step=step_num, epoch=epoch_num,
context={"subset": "train"})
def epoch_end(self, run_context):
"""epoch end"""
cb_params = run_context.original_args()
# loss
epoch_num = cb_params.cur_epoch_num
step_num = cb_params.cur_step_num
loss = cb_params.net_outputs
train_dataset = cb_params.train_dataset
train_acc = self.model.eval(train_dataset)
test_acc = self.model.eval(self.dataset_test)
print("【Epoch:】", epoch_num, "【Step:】", step_num, "【loss:】", loss, "【train_acc:】", train_acc['accuracy'], "【test_acc:】",
test_acc['accuracy'])
self.aim_run.track(float(str(loss)), name='loss', epoch=epoch_num, context={"subset": "train"})
self.aim_run.track(float(str(train_acc['accuracy'])), name='accuracy', epoch=epoch_num,
context={"subset": "train"})
self.aim_run.track(float(str(test_acc['accuracy'])), name='accuracy', epoch=epoch_num,
context={"subset": "test"})
...
# Aim
aim_run = Run(repo=args_opt.aimrepo_url, experiment=f{args_opt.output_url}/bs{batch_size}_lr{learning_rate}_mt{momentum}")
# Log run parameters
aim_run['learning_rate'] = learning_rate
aim_run['momentum'] = momentum
aim_run['batch_size'] = batch_size
# 训练网络模型
model.train(2, dataset_train, callbacks=[ckpoint, AimCallback(model, dataset_test, aim_run)])
...
0****3
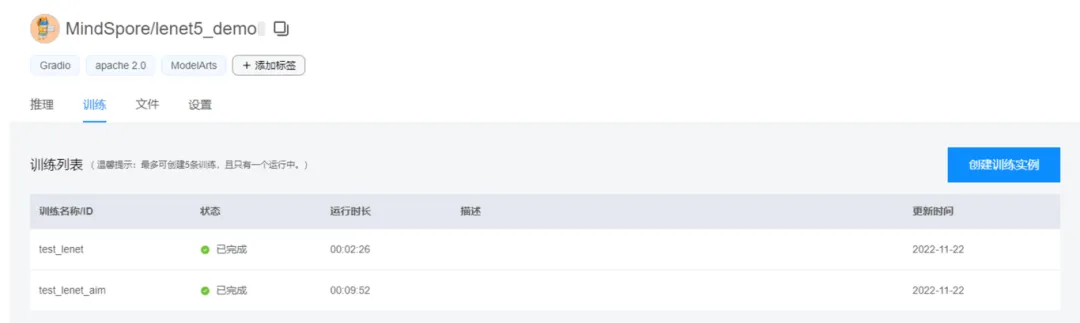
查看训练列表
0****4
推理可视化
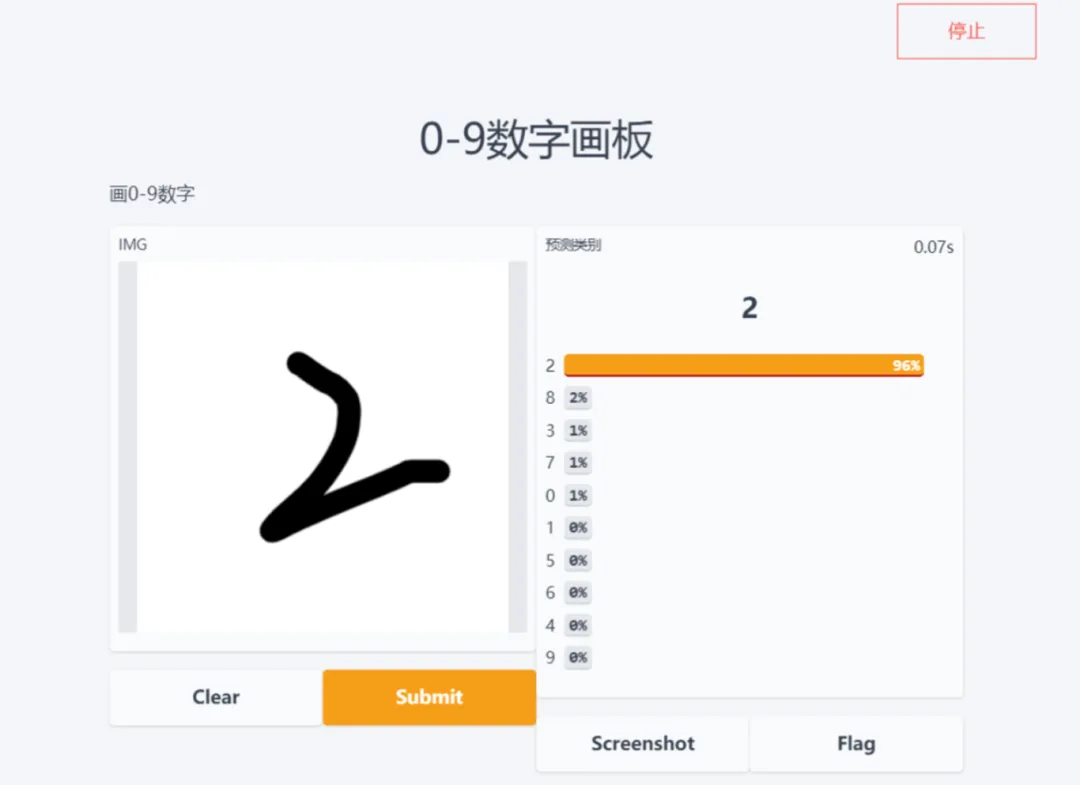
选择推理页签,点击启动按钮,启动过程会比较慢,请耐心等待,一般为5分钟以内,若时间过长,请检查推理代码。
MNIST画板效果展示: