昇思MindSpore原生论文 | 面向大规模科学智算的基础模型OmniArch
昇思MindSpore原生论文 | 面向大规模科学智算的基础模型OmniArch
论文标题
OmniArch: Building the Foundation Model for Scientific Computing
论文来源
arXiv
论文链接
https://arxiv.org/abs/2402.16014
代码链接
https://openi.pcl.ac.cn/cty315/OmniArch
昇思MindSpore作为开源的AI框架,为开发人员带来端边云全场景协同、极简开发、极致性能的体验,支持国内高校/科研机构发表1700+篇AI顶会论文。为鼓励基于昇思MindSpore进行原生创新,昇思开源社区转载、解读系列原生arXiv论文,本文为昇思MindSpore AI arXiv论文系列第5篇。
作者:Tianyu Chen
感谢各位专家教授与同学的投稿,更多精彩的论文精读文章和开源代码实现请访问Models。更多内容请访问: https://gitee.com/mindspore/community/issues/I9W2Z3

研究背景
以GPT-4为代表的基础模型,彻底变革了语言处理、图像理解与跨模态生成等领域,同时也在向人类智慧的最高结晶“科学研究”发起冲击。例如千禧年问题NS方程如何进行人工智能科学计算求解,是否存在类似于基础模型的Scaling law?本文提出了面向科学智算的基础模型OmniArch,首个旨在解决多尺度和多物理科学计算问题的基础模型原型,通过全新设计的统一架构解决了问题尺度、物理量、物理规律的三方面难对齐的挑战。该模型在国际基准PDEBench上完成了1D-2D-3D的联合预训练,展现出了较强的上下文学习能力,特别是零样本推理带来了全新物理发现的可能。
作者介绍
论文第一作者为北京航空航天大学计算机学院博士生陈天宇(Tianyu Chen),依托北航科学智算团队完成,他的研究方向包括科学智算AI4S、大模型安全、跨模态检索等交叉领域,对MindSpore、PyTorch等深度学习框架有丰富的实践经验,深入研究过PDE基础模型构建与自适应、跨模态对比学习、多专家稀疏预训练等关键技术。
论文简介
偏微分方程(PDE)作为描述物理现象的关键数学工具,其求解方法一直面临诸多挑战:传统数值方法难以高效处理复杂系统,而神经网络方法则需特定性设计,难以泛化。虽然基础模型通过大规模预训练展现出强大的泛化潜力,但目前多数模型仍局限于特定维度特定物理系统,且在物理信息的利用上有待加强。
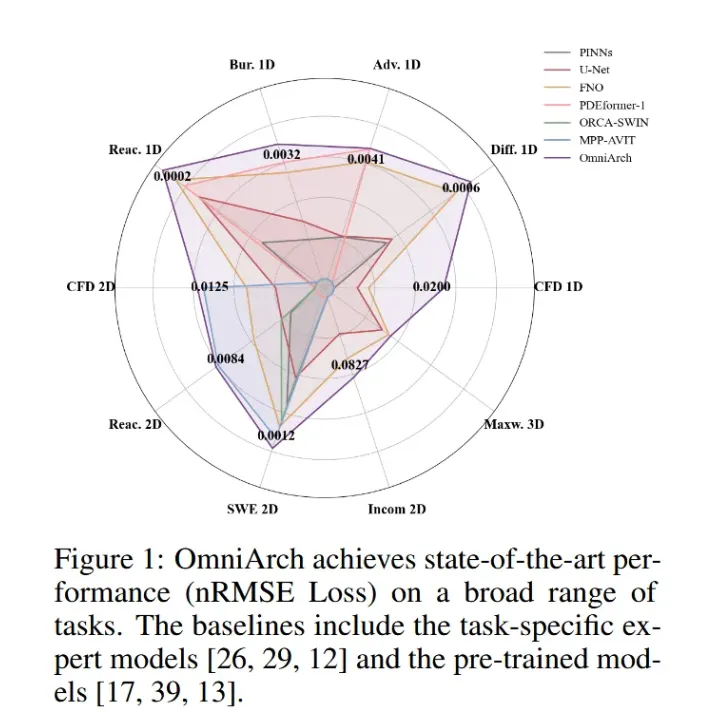
本文提出的OmniArch模型是首个针对多尺度、多物理量PDE问题实现物理对齐基础模型。它通过统一架构应对三大核心挑战:
**1、多尺度:**支持不同维度(1D-3D)、不同分辨率和形状的输入,从简单的一维管道流动到复杂的三维湍流均可准确模拟。
**2、多物理:**能够处理包含多种物理量的动态系统,有效捕捉如湍流系统中速度、压力、密度等物理量间的相互作用。
**3、物理对齐:**灵活整合物理先验知识,包括控制方程、对称性、守恒定律和边界条件等。
OmniArch采用"预训练-微调"策略:预训练阶段通过傅里叶编码器-解码器处理多尺度问题,并引入时间注意力机制增强多物理量泛化能力;微调阶段则通过PDE-Aligner模块深化物理规律的嵌入。实验表明,该模型在广泛任务中均实现了较优性能(nRMSE损失)。
0****1
OmniArch 的预训练:灵活学习不同动态系统
OmniArch的整体预训练框架如图2所示。通过傅里叶编码器将不同维度(1D、2D、3D)的物理数据坐标和观测值转换为频率域。高频和低频分量在频域中进行裁剪,以确保来自不同网格的数据具有相同长度的嵌入表示,这些表示通过共享的 Transformer 模块沿时间轴建模积分算子。通过时间掩码机制,每个物理量可以同时关注所有物理量以及以前的时间步长,最终通过傅里叶解码器从预测的频率域信号恢复物理场预测值。
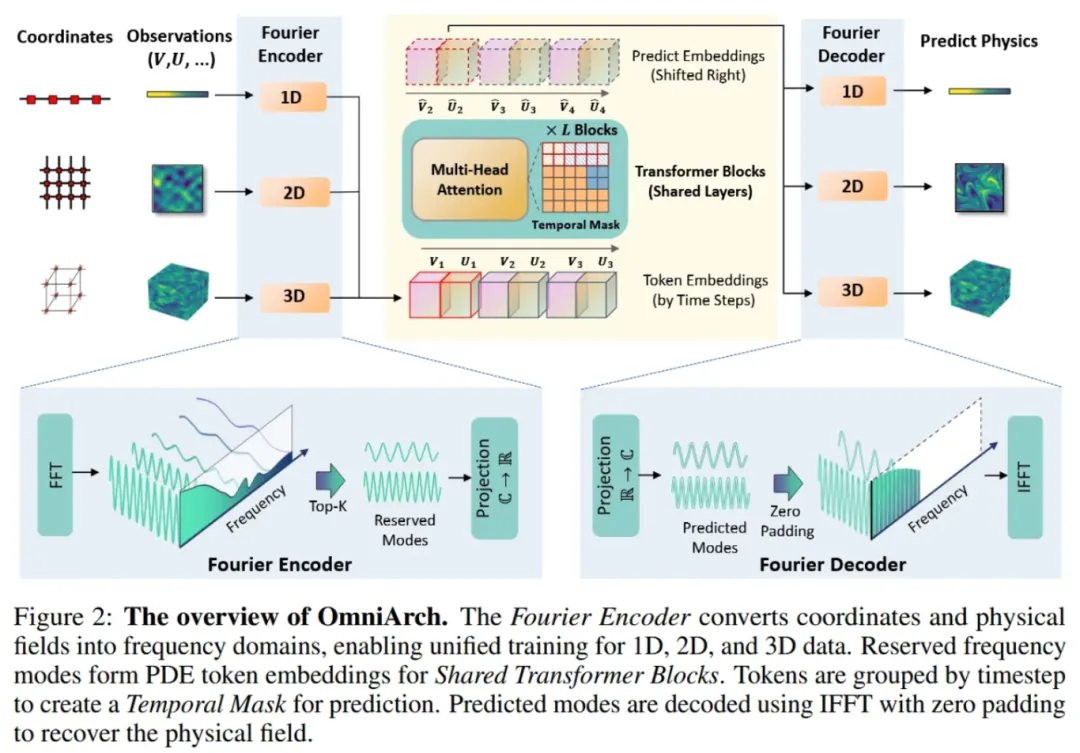
1.1 傅里叶域的编码器/解码器
为了应对多尺度挑战,OmniArch 利用傅里叶变换将时空信号转化为频率域。傅里叶编码器在每个时间步对输入的物理场进行频域转换,采用高频和低频分量的过滤机制,保留关键频率模式,从而实现跨维度、分辨率和网格形状的统一表示。通过快速傅里叶变换(FFT),实现频域特征的稀疏性和可分离性,利于后续的Transformer模块有效处理时间信息,减少模型的参数和计算开销,从而获得更好的训练和推理效率。编码阶段FFT的过程如下:
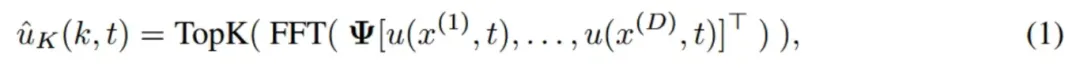
其中upred(x(d), t + 1) 为当前时间步物理场, u(x(d), t)为空间域特征。
在解码阶段,预测的频率域特征通过零填充适配目标形状,并通过逆傅里叶变换(IFFT)将频域特征还原到时空域,最终得到预测的物理场:
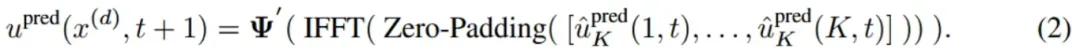
其中upred(x(d), t + 1) 为下一时间步物理场, uˆpred K (k, t)为频域特征。
1.2 Transformer 积分神经算子
OmniArch 基于Transformer backbone模拟积分神经积分算子,结合时间掩码(Temporal Mask),在时间轴上实现长距离依赖建模。Transformer 的多头自注意力机制允许每个时间步访问所有物理量及其先前的时间步,对每个时间步的全局依赖关系进行建模,实现对系统动态变化的精确捕捉。此外,Transformer 的自回归机制类似于传统多步法,通过加权求和动态更新状态,实现高精度预测。
Transformer 的自回归机制通过注意力权重通过先前时间步的加权和来更新当前状态:
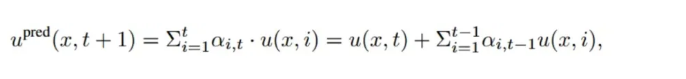
由于动态系统之间的数值差异,OmniArch在训练期间使用 nRMSE 来计算损失函数 Lsim:
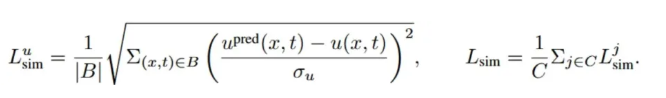
0****2
OmniArch 的微调:基于方程的物理对齐学习
微调阶段,OmniArch 引入了 PDE-Aligner 模块,旨在在微调过程中遵守特定的物理定律。
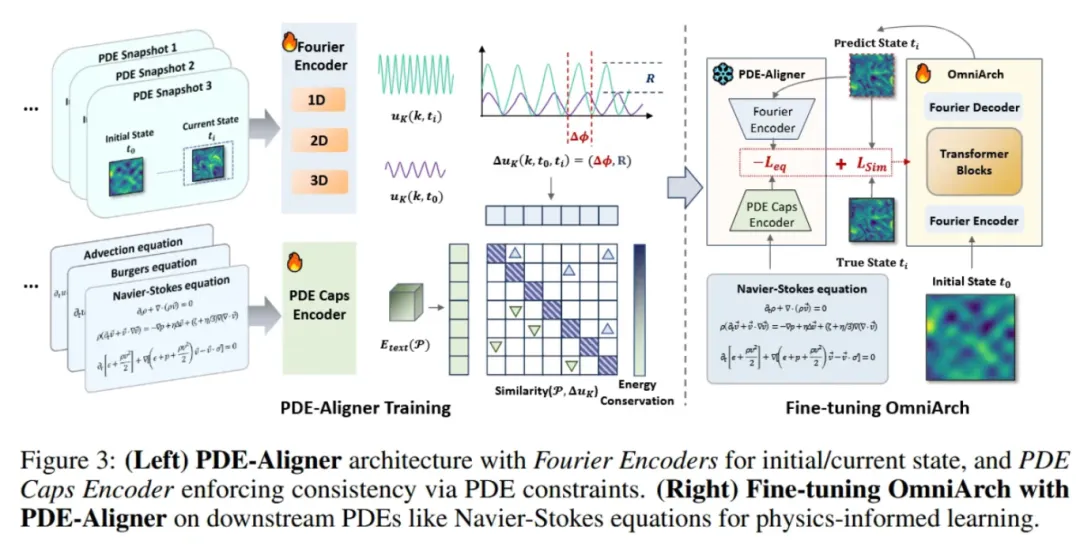
PDE-Aligner 结合对比学习框架,通过频域特征捕捉动态系统的语义,使用相位差和幅值比等指标对齐物理场预测与文本描述之间的关系。损失函数如下:
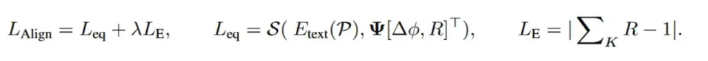
其中,Leq是方程相似性损失,表示文本和频域嵌入的相似性,LE是能量守恒损失,用于对物理场的能量变化进行约束, λ 是平衡能量守恒损失的超参数。通过最小化对齐损失函数,PDE-Aligner 在能量守恒的约束下将物理场的变化与文本描述对齐。
实验结果
在本研究中,数据集来源于公开数据集 PDEBench 和 PDEArena,涵盖了1D、2D 和 3D 数据集,例如Navier-Stokes、Burgers、diffusion-sorption、advection等方程,涉及流体动力学、扩散、对流、反应扩散等多种物理现象。为了全面评估 OmniArch 的性能,实验中选取了特定任务的专家模型(PINNs、U-Net、Fourier Neural Operator (FNO))和统一的预训练模型(PDEformer-1、Multiple Physics Pre-training (MPP) 、 SWIN-transformer )两大类模型作为baseline。
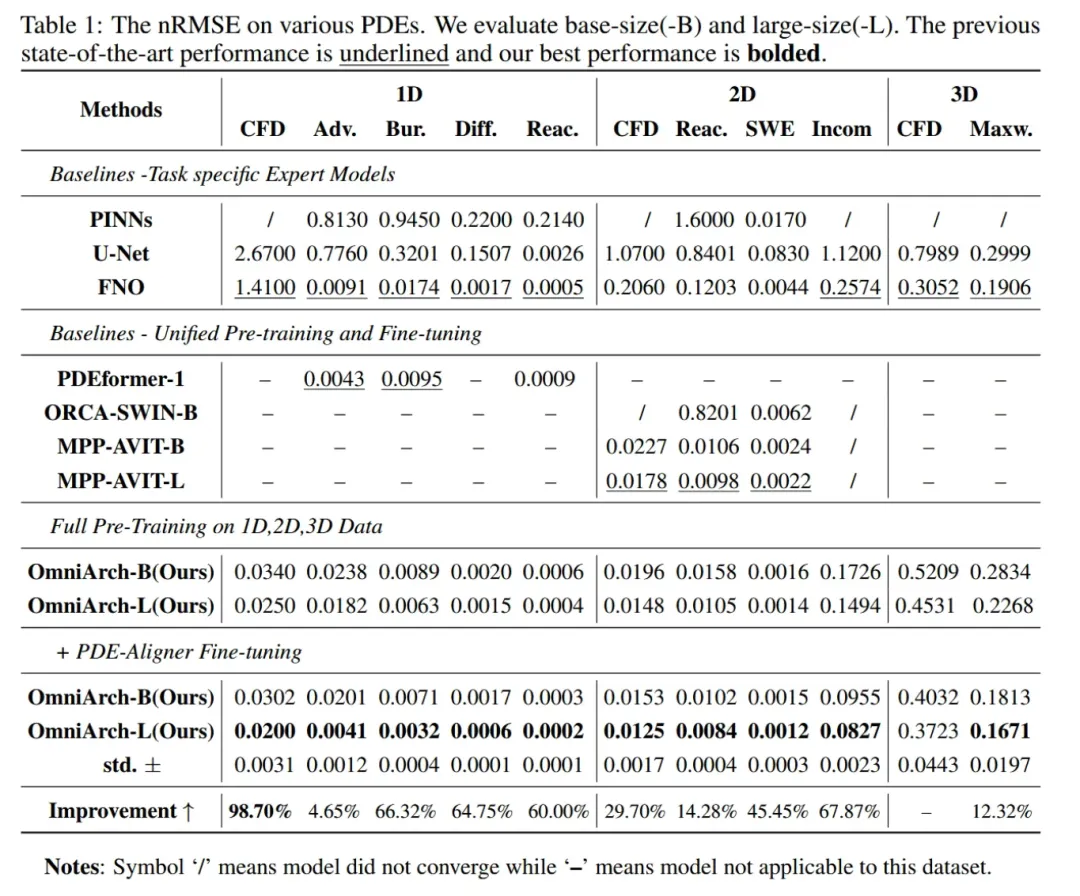
如表1所示,实验结果表明,OmniArch 在处理涉及复杂物理系统、多物理量和不同尺度的任务时,展现了显著的优势,尤其在多物理场景中,相较于传统模型,OmniArch 在1D、2D、3D数据上均达到了更低的预测误差和更高的精度。
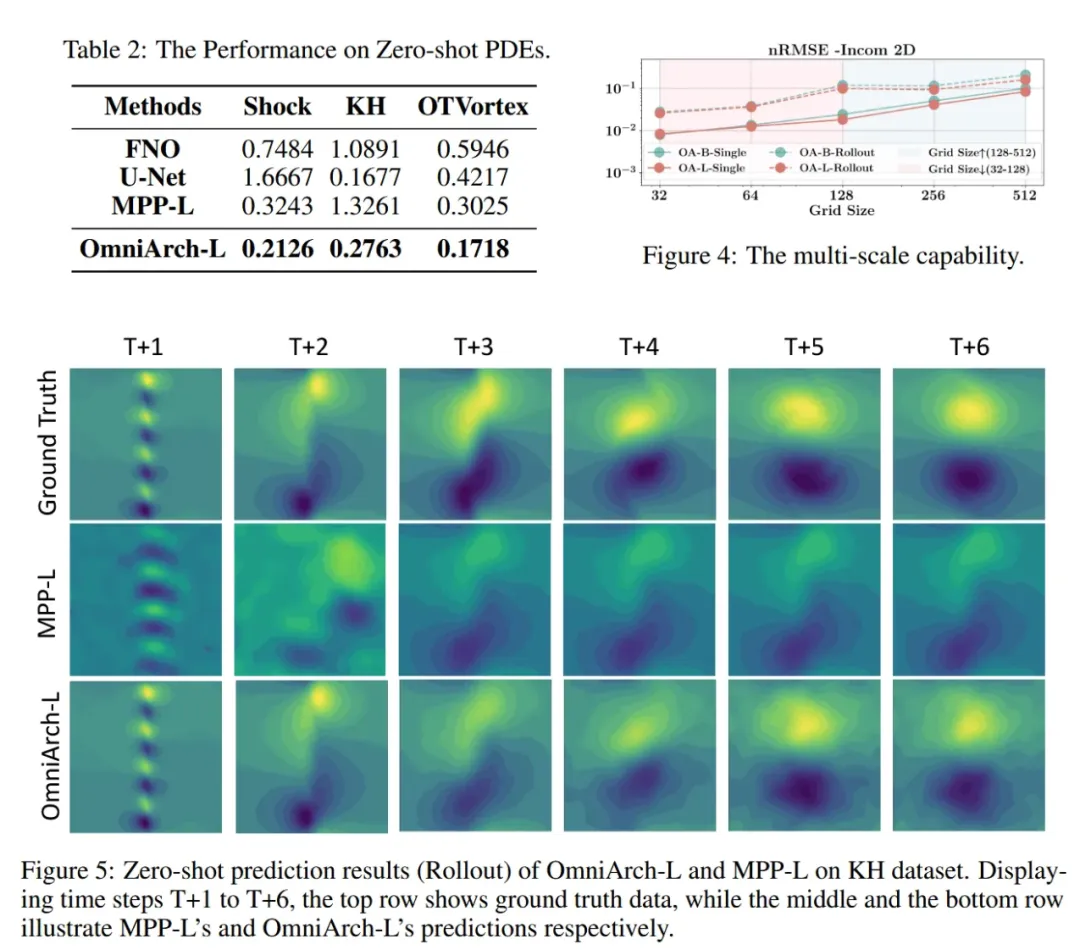
OmniArch 的多尺度推理能力也得到了充分的验证。图4展示了 OmniArch-Base 和 OmniArch-Large 在 2D Incom 上的多尺度推理性能,模型在不同分辨率的网格数据上表现出色,OmniArch 可以处理不同网格大小的输入,而无需重新训练,即使网格大小为 512,最大 nRMSE 仍低于 0.2。实验发现,256256的网格有时会比128128的网格达到更好或相当的性能。
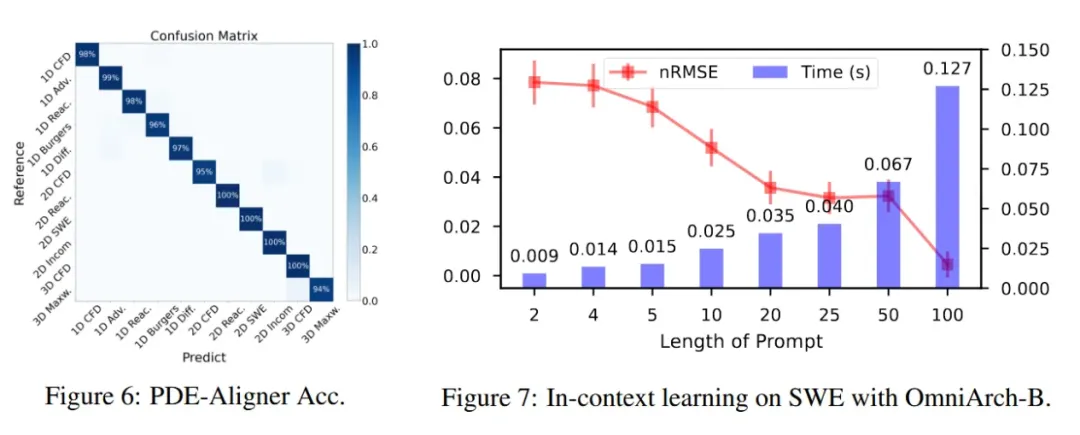
为验证PDE-Aligner的物理信息感知能力,本文设计了探针实验,通过附加分类头对物理场进行分类。实验结果显示,PDE-Aligner能够基于方程文本信息和物理场特征准确识别物理场类型,在全部十个类别中均达到94%以上的分类准确率(图6)。
在2D PDE实验中,即使在零样本场景中,面对领域外的 PDE 系统,OmniArch 也能有效捕获低频和高频模式,超越了 MPP 等以前的2D模型(如图5所示)。如表 2 所示,除 OmniArch 之外的所有模型在零样本迁移中往往表现不佳,这表明 OmniArch 对傅立叶编码器和统一训练方法的使用增强了其跨不同偏微分方程的泛化能力。
通过对多种动态系统进行自回归预训练,OmniArch表现出类似大语言模型的上下文学习能力,可从有限的时间步长序列中学习神经算子。实验表明,观测序列越长,预测精度越高且方差越小。然而,较短的观测序列相比完整序列可将推理速度提升至10倍(图7),在精度和效率间实现良好平衡。
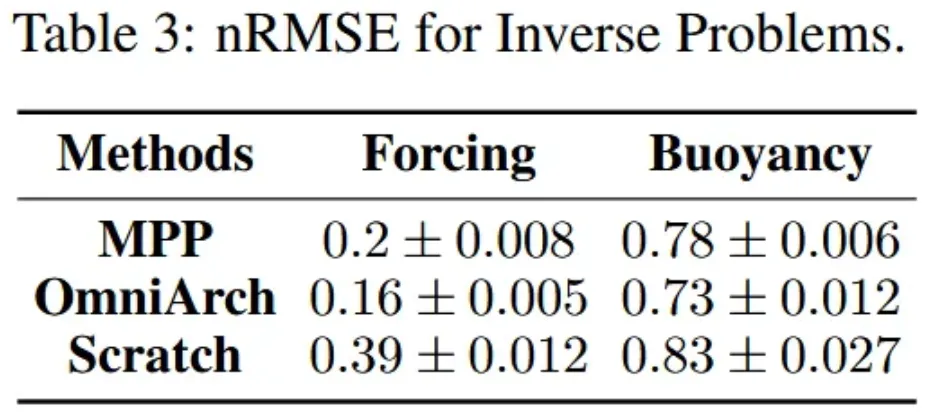
在逆问题方面,如表3所示,OmniArch在参数估计任务中显著优于MPP。相比之下,从零训练的模型产生最高的误差率,这不仅验证了预训练-微调范式的有效性,更证明OmniArch不仅擅长正向模拟,还能够准确推导复杂系统中的潜在动力学特征。
基于昇思Mindspore框架实现的OmniArch具有一定的效率优势,其Base版本在NPU上推断速度约为每秒60个时间步,相比传统数值求解器推断速度提升超过一个数量级。
总结与展望
本研究提出了专为科学计算领域设计的基础模型OmniArch,通过创新性地整合PDE-Aligner进行微调,在PDEBench测试集上实现了最优性能。实验结果表明,该模型展现出类似大型语言模型的零样本迁移能力,这一特性对扩展模型应用范围具有重要意义。尽管OmniArch在多个方面取得突破性进展,但在处理三维PDE系统时仍面临挑战。这不仅指明了未来研究方向,也为进一步优化模型架构提供了重要洞见。作为PDE学习领域的基础模型,OmniArch有望推动科学机器学习与深度学习的深度融合,为解决更广泛的科学计算问题奠定基础。
模型应用部署
该模型已经在团队建设平台上线,网址:
北航、浙大、百度、华为、中山等单位共同承担人工智能科学计算共性平台研发和门户运营。