开源之夏系列 | 基于MindSpore的BitsAndBytes量化框架实现
开源之夏系列 | 基于MindSpore的BitsAndBytes量化框架实现
开源之夏,是由中国科学院软件研究所发起,专为高校学生精心打造的活动。旨在鼓励广大学子积极参与开源软件的开发与维护,推动优秀开源软件社区的蓬勃发展。
目前,开源之夏2024已圆满结项!在本届开源之夏中,不少开发者跟随昇思MindSpore一起,在开源的世界里畅游,成功完成项目任务。在此,昇思 MindSpore 开源社区邀请了开源之夏的开发者们,分享他们在本次活动中的宝贵经验与心得。我们希望通过这些精彩的项目经历和实战技巧,能够激发更多创意火花,帮助大家提升技术能力。本文为昇思MindSpore 开源之夏项目经验分享系列第2篇。

项目基本介绍
1、项目名称:基于MindSpore的BitsAndBytes量化框架实现
2、项目导师:Candyhong
3、项目链接:https://summer-ospp.ac.cn/org/prodetail/24c6d0486?list=org&navpage=org
4、项目描述:在大模型时代,算法对计算机存储和算力的要求与日俱增,导致模型部署的成本也相应地成倍增加。量化、剪枝、蒸馏、神经架构搜索等方法是模型轻量化的常用方法,目的都是为了降低计算成本,提升计算性能,其中模型量化技术把模型中的高精度运算(比如FP32)替换为低精度运算(如INT8、INT4、FP4、NF4等),并通过插入反量化节点、量化感知训练等方法使量化过程中的精度损失尽可能更少,大大提升了特别是在端侧的显存压力,提高了模型推理的性能。
BitsAndBytes library(以下简称为“bnb”)是一个十分经典且常用的量化库,很早就被Hugging Face的Transformers套件所集成。它是一个封装CUDA自定义函数的轻量级Python wrapper,特别是8位优化器,矩阵乘法(LLM.int8())以及8位和4位量化函数。该库包括用于8位和4位操作的量化原语,bitsandbytes.nn.Linear8bitLt和bitsandbytes.nn.Linear4bit以及bitsandbytes.optim优化器模块。
项目要求基于昇思MindSpore自定义算子的GPU版本量化算子开发以及BitsAndBytes库对标量化能力实现。促进MindSpore NLP的量化特性的支持,提高套件的易用性,形成一个面向MindSpore NLP模型推理的量化库MindSpore BNB,这样在消费级显卡上也能愉快地进行LLM的推理了。
项目选择初衷
本科的时候通过华为“智能基座”项目了解到了MindSpore框架,在2022年10月开始担任重庆大学智能基座协会的负责人,对华为公司的ICT技术生态有了较为深入的了解,后来通过昇思MindSpore开源实习进入到MindSpore开源社区主要参与MindSpore NLP套件的开发,并成为MindSpore NLP SIG的主要成员,此前在MindSpore NLP套件负责人吕昱峰老师的指导下我主要自顶向下完成了多个LLM的模型迁移工作,模型微调工作、以及MindSpore NLP套件中Flash Attention算子在GPU后端的移植与调优。同样也是应MindSpore NLP开发的要求,需要拓展GPU后端的量化能力,同时我在之前关于Flash Attention算子的工作中也有了开发MindSpore的Custom自定义算子的经验,并且目前的研究也与模型量化相关,于是就参加了本次开源之夏的这个项目。
项目方案介绍
项目目的是基于bnb实现一个MindSpore可用的量化库,设计成一个量化接口集成在MindSpore NLP里,可直接对加载后的模型进行训练后量化(PTQ),提高模型的推理性能。为了实现上述目的,由于bnb是跟PyTorch紧耦合的,需要从CUDA算子开始,逐层向上迁移,处理因不同框架的不同特性导致的运行时不兼容。核心是通过MindSpore所支持的Custom自定义算子模版,将bnb库中实现的众多CUDA算子迁移到MindSpore NLP套件中,作为MindSpore BNB量化库的核心组成部分。
项目分析
为了确保迁移开发过程顺利,保障结果的可靠性,在进行编码之前先做三件事:1. 阅读bnb量化方法的论文,见 https://arxiv.org/abs/2208.07339 ,了解量化的具体原理,这样才知道正在做什么,哪一部分内容或者代码是最关键的。2. 要实现bnb库的迁移,了解MindSpore对量化相关操作的支持现状3. 本地编译bnb源码,了解项目构建过程、代码实现、开发所用工具链等信息。
0****1
技术原理
bnb中的量化方法主要是聚焦于对outlier离群值的处理,因为激活值中往往存在这样一些绝对值明显更大的离群值,离群值往往分布在少量特征中,即为离群特征。以激活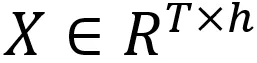 和权重
和权重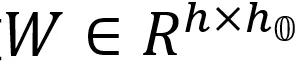 的矩阵相乘为例,特征维度就是指h这个维度。不论是 per-token(针对激活 x 而言:每行对应一个量化系数) 还是 per-channel (针对权重 w 而言:每列对应一个量化系数)量化,都会受到这些离群值的很大影响。既然只有少量的特征包含离群值,LLM.in8() 的思路是把这些特征拿出来单独计算,只对剩余特征做量化。
的矩阵相乘为例,特征维度就是指h这个维度。不论是 per-token(针对激活 x 而言:每行对应一个量化系数) 还是 per-channel (针对权重 w 而言:每列对应一个量化系数)量化,都会受到这些离群值的很大影响。既然只有少量的特征包含离群值,LLM.in8() 的思路是把这些特征拿出来单独计算,只对剩余特征做量化。
LLM.int8()是一种采用混合精度分解的量化方法。先做一个矩阵分解,对绝大部分权重和激活用8bit量化(vector-wise)。过程中对离群特征的几个维度保留16bit,对其做高精度的矩阵乘法。计算示意图如下:
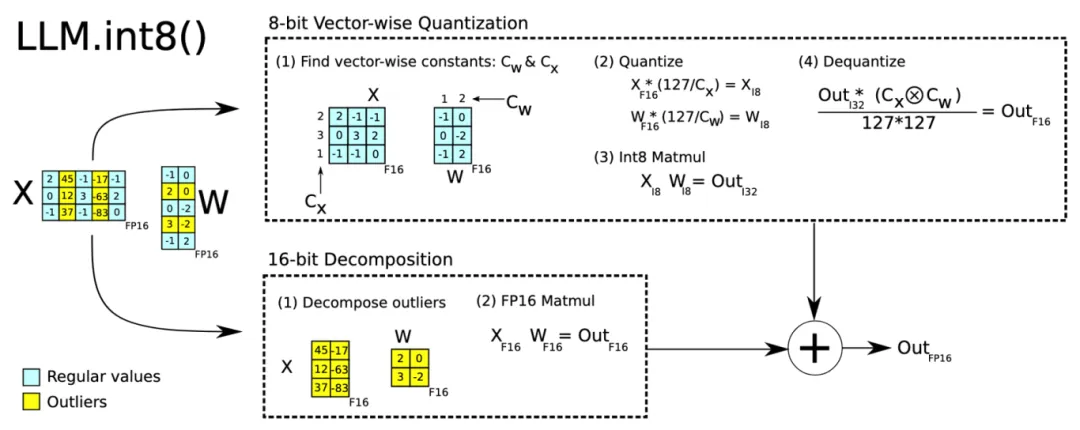
图 1 LLM.int8()计算示意图[1]
主要通过三个步骤完成计算过程:
1、从输入的隐状态中,按列提取离群特征。
2、对离群特征进行 FP16矩阵运算,对非离群特征进行量化,做 INT8 矩阵运算。
3、反量化非离群值的矩阵乘结果,并与离群值矩阵乘结果相加,获得最终的 FP16 结果。
0****2
MindSpore低精度量化支持
可以从官方文档中查阅到,MindSpore目前还没有4位的数据类型,所以本项目聚焦于将bnb中的8位量化能力迁移到MindSpore中,将bnb中的CUDA算子通过Custom算子自定义算子接入到MindSpore框架,以此为基础实现Linear8bitLt,并结合MindSpore NLP套件实现相应的Linear替换策略,使大模型能够使用此量化方法简单方便地进行模型的压缩和推理,提升MindSpore在GPU算子上的兼容性。
图 2 mindspore.dtype[2]
0****3
bnb****项目分析
在迁移项目之前,首先要分析清楚bnb量化逻辑从模型到算子的具体流程以及部署过程中的细节。关于bnb的详细构建步骤可以参考huggingface官网的文档 https://huggingface.co/docs/bitsandbytes/main/en/installation 额外需要注意,明确项目所需依赖版本与MindSpore NLP中的要求是否冲突,并摒弃掉所有跟PyTorch有关的依赖,实测项目开发时bnb的最新版本bnb 0.43.2.dev0 (现在源码编译的最新版本是0.44.2.dev0)需要python >= 3.10,否则安装依赖会失败。 把核心的构建流程迁移到MindSpore BNB的构建脚本中来,几乎是一样的,只是安装的依赖会不同,见 https://github.com/hypertseng/mindbnb/blob/main/scripts/build.sh 与 https://github.com/hypertseng/mindbnb/blob/main/requirements-dev.txt
项目实现思路
安装部署好bnb之后,为了探究量化的过程,需要从transformers的from_pretrained接口出发,可以打断点调试,观察bnb是如何在加载预训练模型的过程中完成对权重的量化的。主要分为以下三部分:
1、加载模型,在replace_with_bnb_linear函数中将模型中的linear层替换为bnb中实现的新的低比特linear层(Linear8bitLt),为了使模型推理结果更稳定,这里会保持lm_head层为高精度。下图是具体的函数调用位置,transformers将量化策略、layer替换方法等集成到了一个单独的quantizer模块中,bnb为可用的量化方法中的一种。

图 3 replace_with_bnb_linear函数
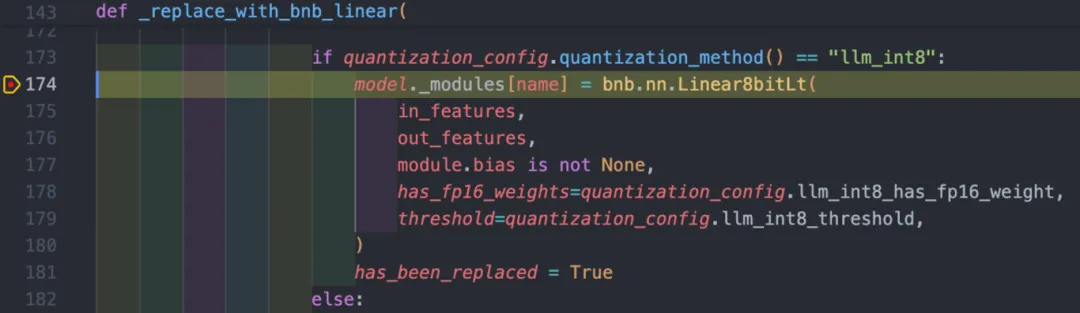
图 4 _replace_with_bnb_linear函数
2、在加载预训练权重时,对高精度权重进行量化,将量化后INT8的权重给到module,bnb新实现了一个Int8Params类,重载了to方法,于是在to(device)时,to方法中会调用.cuda()函数,并在里面实现量化权重的计算。
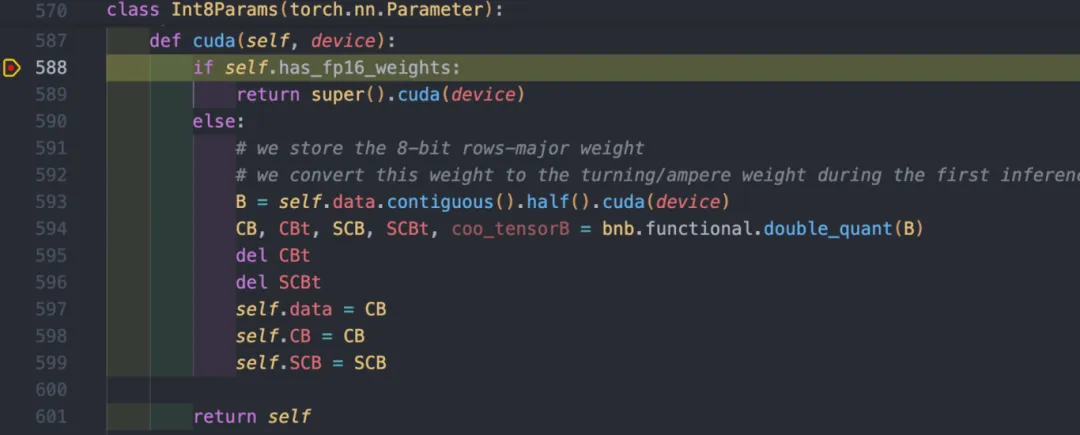
图 5 cuda函数中实现量化计算
3、推理时使用量化算子进行高效的低精度计算,如下:
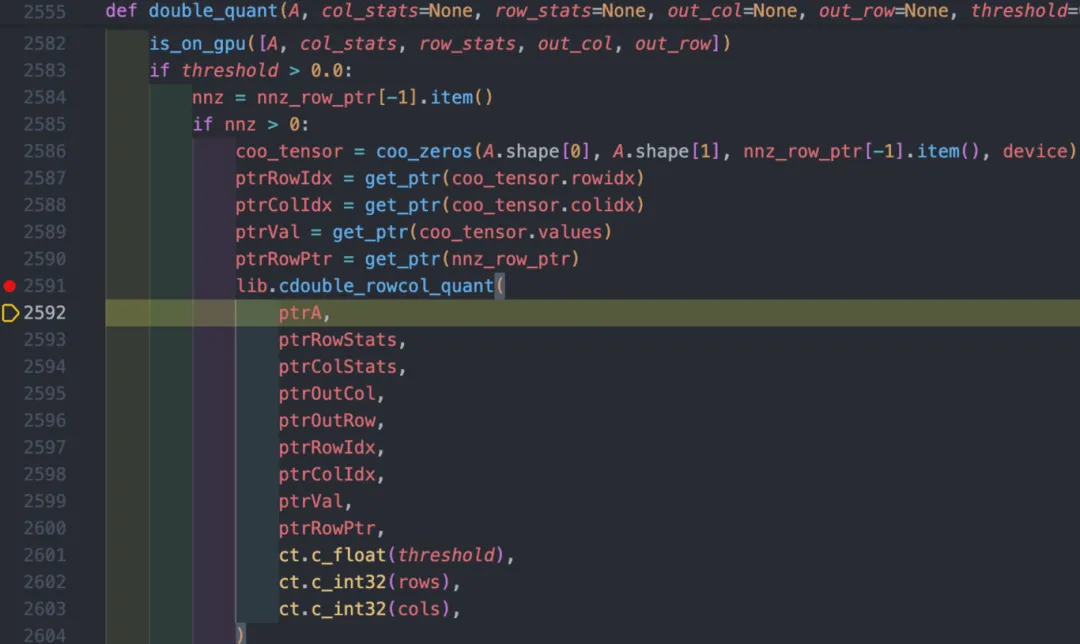
图 6 double_quant量化
这里以cdouble_rowcol_quant为例,从Linear8bitLt layer到这个算子的函数调用栈为:Linear8bitLt=>bnb.matmul=>MatMul8bitLt=>double_quant=>lib.cdouble_rowcol_quant,这是一种由上至下的执行路径,这样的执行路径还有多条,但在开发过程中可以先解决其中一条路径,总结出方法经验,再采用DFS式的开发逐个击破。
以上就是项目迁移和开发的基本思路。在实际开发过程中还有许多需要处理的问题。最重要最关键的是算子的接入问题。
由于bnb中本身包含了大量量化过程中会使用的高度优化的CUDA核函数,并把它们封装成算子,又由于算子被进一步封装为python文件调用的接口,写在pythonInterface.cpp里,bnb项目构建时会将众多算子根据接口文件中的实现打包,根据当前是否使用GPU和系统安装的CUDA工具链的版本,预编译生成一个动态链接库文件。原本bnb是通过ctypes库来加载dll动态链接库,便可直接访问pythonInterface.cpp中定义的c++函数。问题就在于如何尽可能复用底层CUDA算子代码,并在Python侧提供一种高效的算子调用方式。
接上CUDA算子之后,再逐层向上修改因为框架差异而导致的不兼容代码,比如大量关于device的操作、关于GPU设备信息的获取操作、因算子调用方式不同导致参数传递不匹配等种种问题,修改多个层次的代码,从算子到量化算法,到低精度乘法layer,再到低精度的Linear layer,最后再定义好合适的layer替换方法,就基本可以实现完整的LLM量化过程了。
最终方案
在MindSpore BNB的实现中,对于大部分算子,采取能用则用的原则,尽量不更改这部分复杂的内容。在算子接入上,选择走Custom AOT类型算子的路线,在Custom模版中传入 .so 文件的路径,由Custom接口去加载动态链接库中的c++函数,这样便能像使用一般python函数一样调用相应的量化算子了。
开发过程中遇到的兼容性问题有很多,在此列出有代表性的几种,并给出MindSpore BNB的实现方案。
01
MindSpore Tensor如何正确地传递给CUDA算子?
以get_colrow_absmax函数为例。函数中会调用算子,如下:
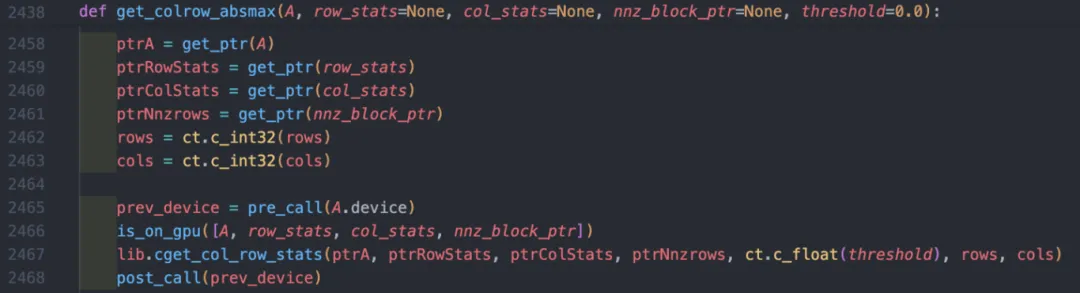
图 7 get_colrow_absmax函数
其中lib是通过预先编译CUDA算子得到的.so文件进行加载得到的,ptrA, ptrRowStats, ptrColStats, ptrNnzrows都是通过get_ptr函数获取的指针。而get_ptr函数需要从Tensor中获取数据的指针,如下所示:
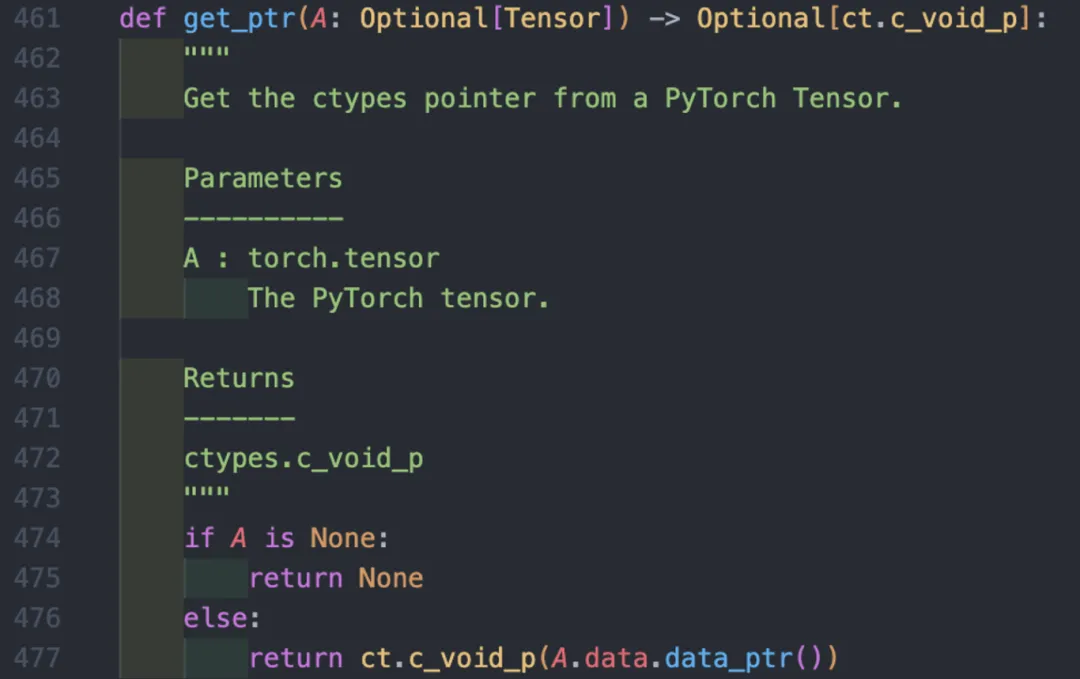
图 8 get_ptr函数
图 7中调用的cget_col_row_stats是一个cpp到python的接口函数,主要用来给CUDA函数传递参数,转换数据类型,在其中会调用getColRowStats算子,算子中会调用相应的核函数。
最大的问题是MindSpore的Tensor根本不支持获取数据的指针,没有提供data_ptr()这样的函数接口。解决思路如下:
1、在python中实现
a)获取mindspore Tensor data的指针?(暂时无法实现)
b)通过numpy实现,先通过asnumpy()获取numpy array,再获取numpy数组的指针,最终将numpy数组的指针传入算子,计算完之后再进行一遍相反的过程得到mindspore Tensor 。(影响速度和显存)
2、在c++中实现
Mindspore Custom自定义算子方案是将参数都识别为void *放在数组中,在算子内部再根据具体kernel输入数据类型用static_cast进行强制类型转换。对于这个问题,可以直接在python中传递mindspore Tensor给Custom算子,在Custom算子中再进行类型转换。
按这种方法,在pythonInterface.cpp中从算子接口处(如cget_col_row_stats函数)往下以MindSpore自定义算子的方式修改,一直改到ops.cu(定义CUDA算子的文件),再修改程序加载动态链接库lib的方式。(工作量巨大,细节多,修改的过程中容易引起其他不可预料的问题)
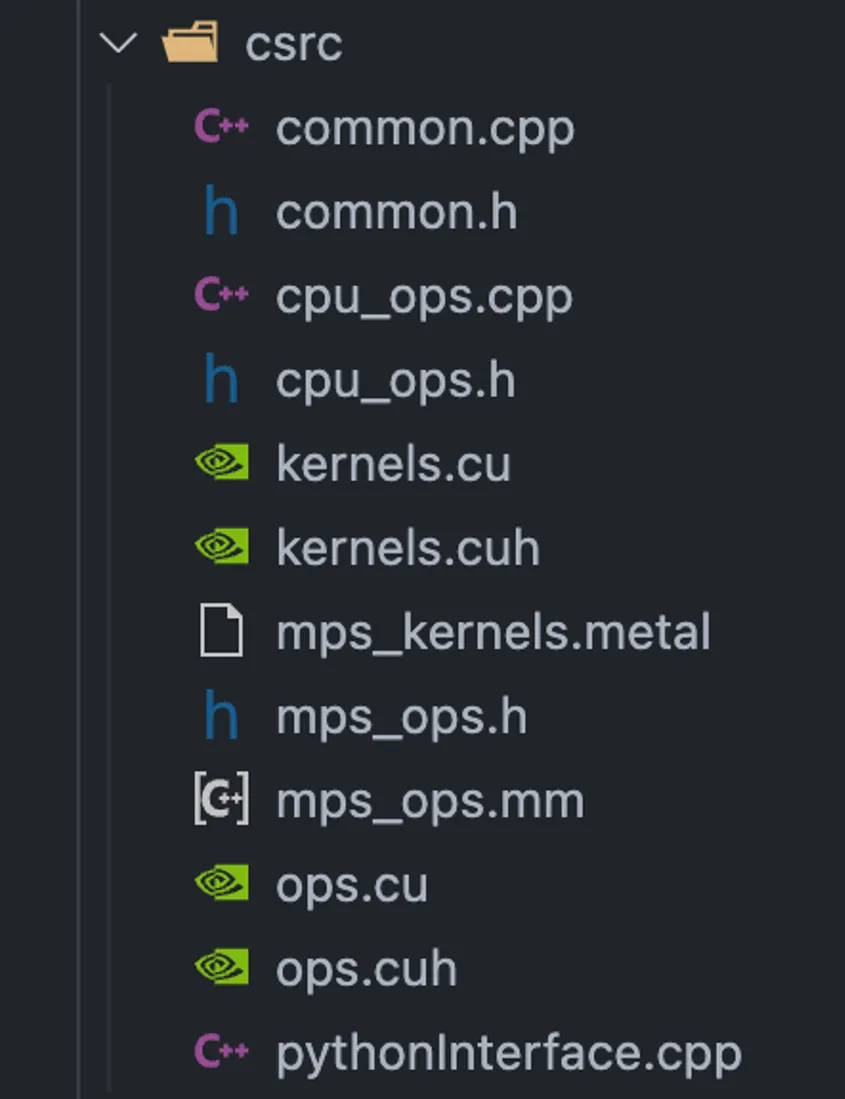
图 9项目中与算子及其接口有关的文件
将get_ptr函数做如下更改,尝试第1种解决方案时遇到的问题:
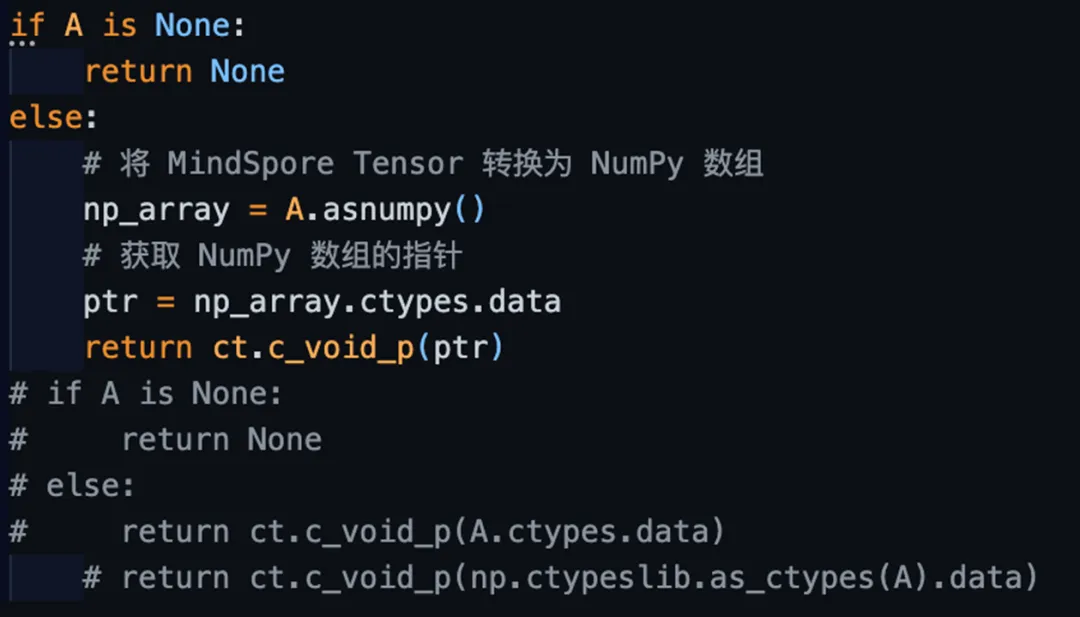
图 10 修改get_ptr函数
发现算子执行时报访存错:
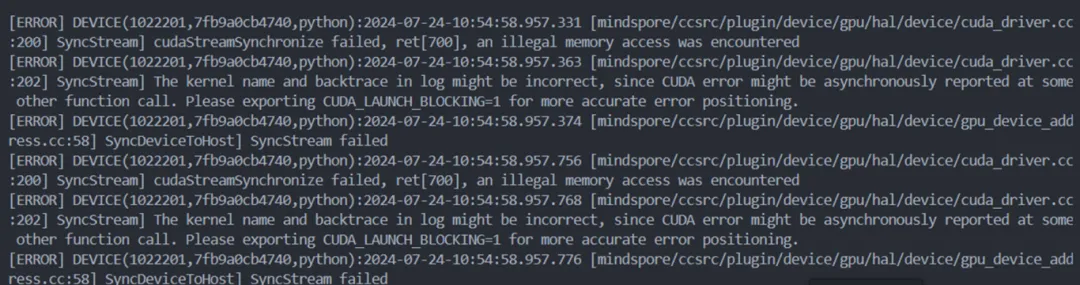
图 11 访存错误
又尝试在函数外将Tensor转为numpy数组,在get_ptr内只完成numpy数组到c指针的转换,没有报错,但执行算子后数组的值没有改变。
原因可能是numpy获取的指针为另一个拷贝数组的指针,导致原数组的值没有改变,在 numpy 数组指针 ptr 被传递到 CUDA 操作后,numpy数组已经被销毁或释放,就可能导致非法内存访问。
最终的解决方案还是使用Custom自定义算子,原理是因为Custom算子定义模版中会将Tensor以 void* 来传递,于是在原先的ops算子外再进行一层抽象,遵循Custom自定义算子的实现规范,下图是针对getColRowStats算子实现的custom_cget_col_row_stats自定义算子的示例。
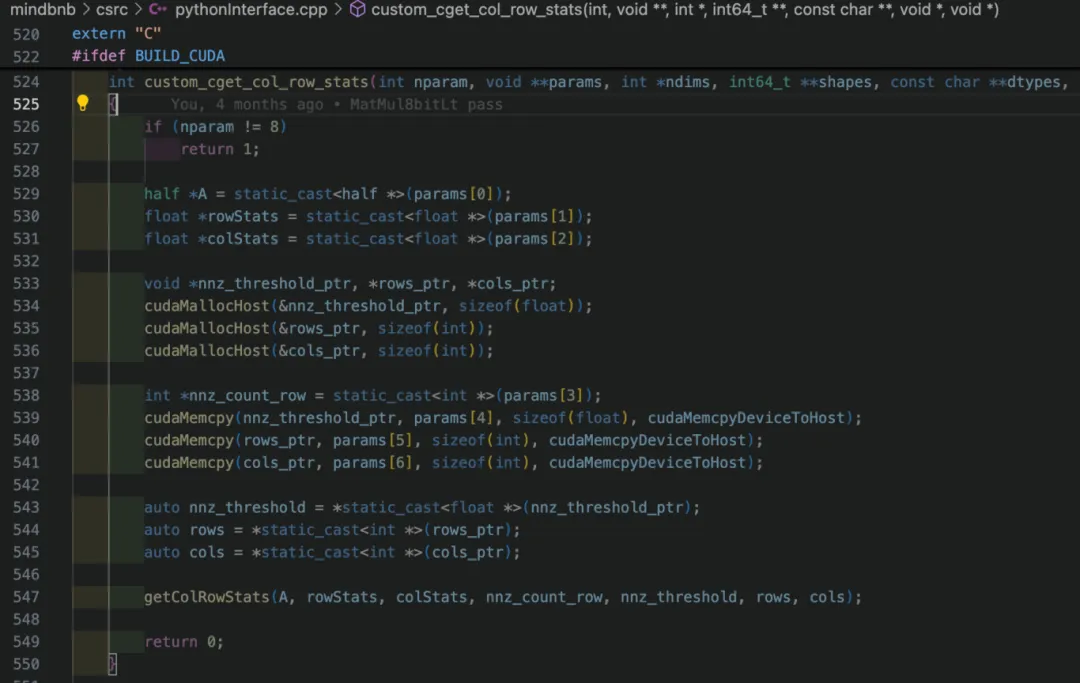
图 12 Custom自定义算子实现示例
而原本的cget_col_row_stats是这样执行的:

图 13 bnb的算子接口函数示例
在自定义算子中能够成功获取到输入的Tensor,并全都用void *来传参,在函数的内部再来处理数据类型的问题。解决了之前的问题,将cget_col_row_stats类接口统一重新实现,用类custom_cget_col_row_stats接口来代替,并仍然可以通过加载动态链接库的方式访问每一个自定义算子。
02
cublas Context问题
igemmlt函数中存在通过device获取相应的Context对象,而Context是定义在CUDA算子头文件ops.cuh中的一个类,主要目的是在构造函数中创建cublas handle,但是MindSpore中设备是由框架调度的,并没有device这个概念。
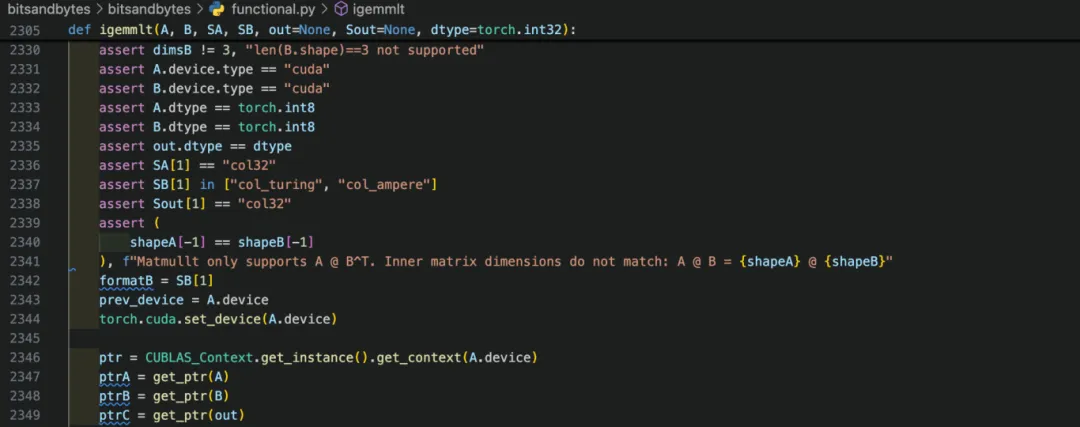
图 14 igemmlt函数获取cublas Context
解决方案是在算子接口层处理handle,直接在需要时在内存中创建,所有需要handle的函数共享这个Context对象。
03
性能问题
在基本完成所有编码工作,确保精度对齐PyTorch实现之后,发现性能上存在着较大差异。下图是使用MindSpore Insight做profiling分析的算子与核函数耗时饼图。
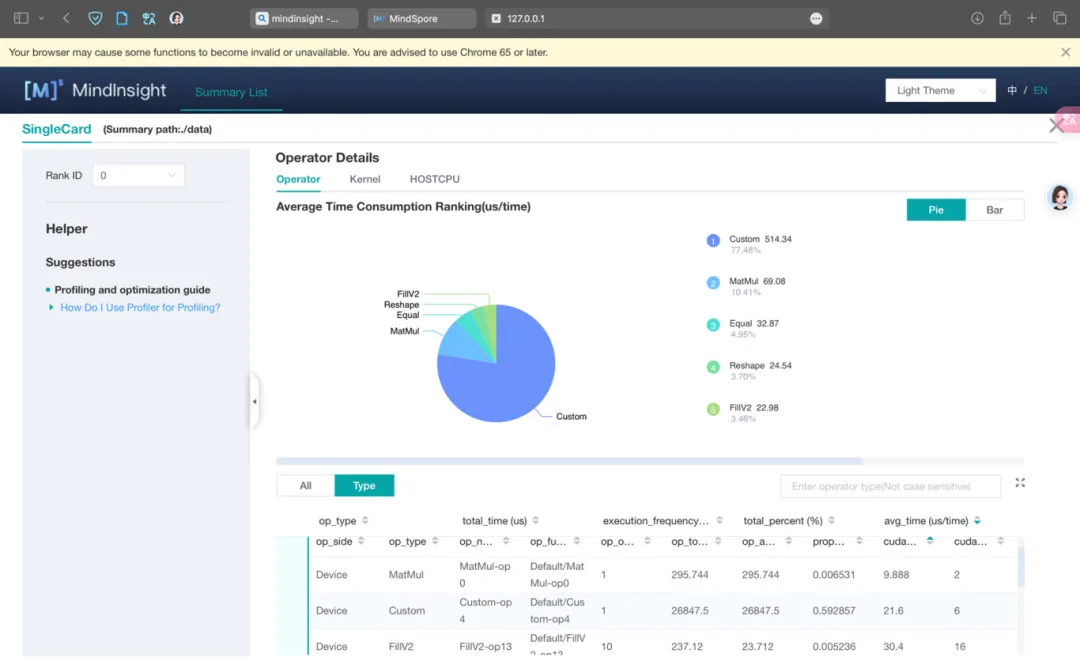
图 15 算子耗时分析
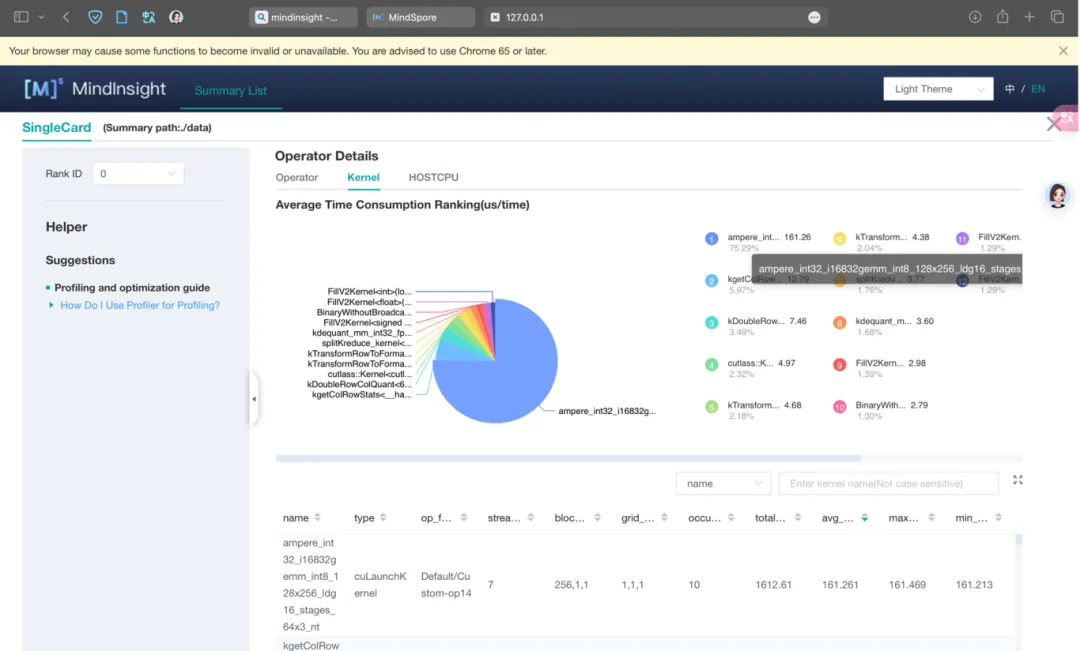
图 16 kernel耗时分析
用tracing查看完整的计算过程,发现算子执行的间隔很长,最终发现原因主要有3点:
1、开发时将torch.empty()替换为了np.empty(),造成执行效率低下,后替换为高效的实现如下图:
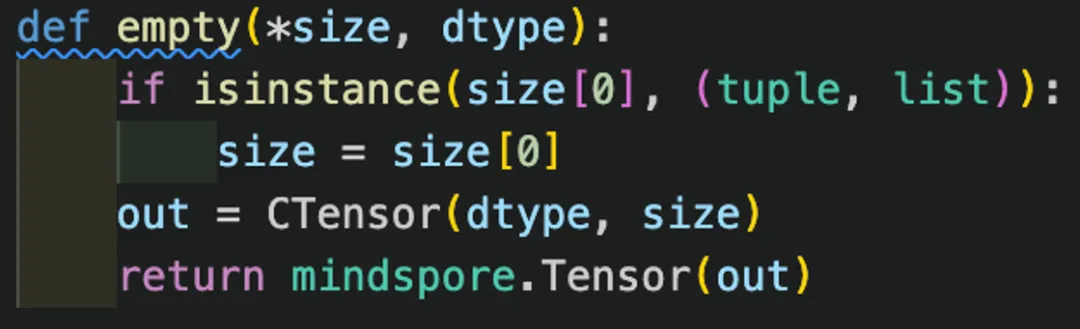
图 17 高效empty函数实现
2、为了获取GPU有关信息,多次通过subprocess运行nvidia-smi速度缓慢,遂后续执行一次就在内存中记录相关信息,降低频繁执行nvidia-smi造成的时间开销。
3、频繁规律调用asnumpy导致流水线等待,经过仔细排查,发现程序中并没有直接使用asnumpy,最终发现在下图位置因为自定义算子返回的是Tensor,所以这里has_error是只含一个元素的Tensor,这里直接比较它的值,隐式调用了asnumpy。asnumpy会把值从GPU拷贝回CPU,造成流水线等待。为了解决此问题,直接给自定义算子加一个参数has_error,在自定义算子内部,将CUDA算子执行的返回值赋给has_error,使逻辑判断等号两边的数据类型一致,避免隐式调用asnumpy。
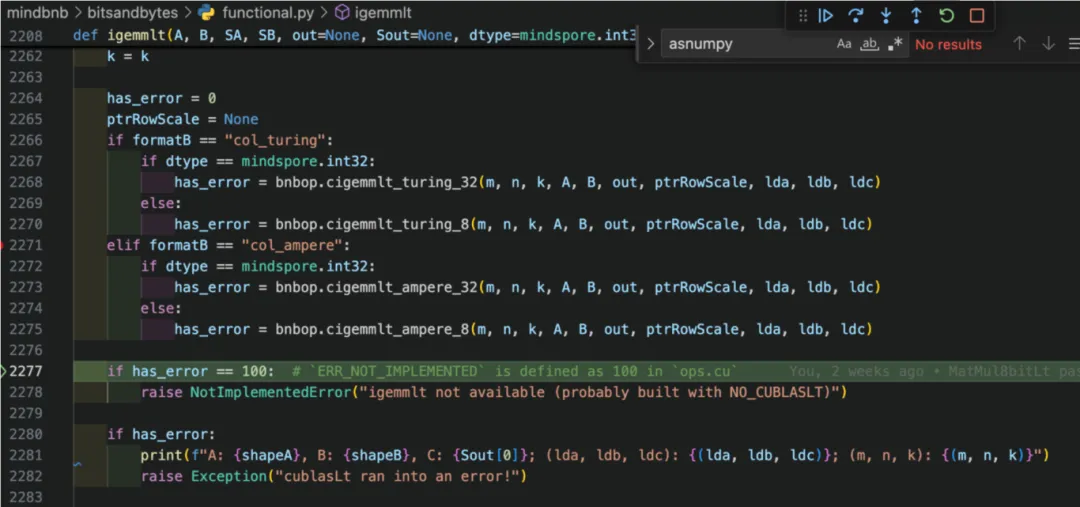
图 18 隐式调用asnumpy
最后能达到与PyTorch实现相近的性能。
项目总结
本项目完成了基于MindSpore的BitsAndBytes量化库的实现,工作主要包含自定义算子的编写、框架迁移、易用的量化接口实现,并在算子、layer、模型层面都进行了精度的测试比对验证。用户只需要在加载模型后,把模型传入我实现的quant_8bit()函数,即可高效实现8bit量化。源代码、构建脚本以及演示脚本等均已开源,见 https://github.com/hypertseng/mindbnb 。
很高兴能参加开源之夏2024,让我持续积累开源社区的开发经验,做自己感兴趣的项目,感谢昇思MindSpore与中科院软件所提供的宝贵实践平台!
参考文章:
[1] Dettmers T, Lewis M, Belkada Y, et al. LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale[A]. arXiv, 2022.
[2] MindSpore[EB/OL].https://www.mindspore.cn/docs/zh-CN/master/api\_python/mindspore/mindspore.dtype.html#mindspore.dtype.
随访
**昇思MindSpore:**请简单介绍一下自己和你的开源经历吧。
**曾子瑄:**大家好,我是曾子瑄,目前在中国科学院软件研究所读硕士一年级,此前担任过重庆大学智能基座协会昇思MindSpore的负责人,我的开源工作主要贡献在MindSpore社区的MindSpore NLP套件中。
**昇思MindSpore:**你是从什么渠道了解到昇思MindSpore的,为什么选择了昇思MindSpore呢?
**曾子瑄:**最早是在2021年,那时我还在读大一,那时智能基座5月份在重庆大学举办了“DevRun智能基座鲲鹏昇腾高校行”,因此我对以鲲鹏昇腾为代表的中国技术生态有了了解,也是第一次了解到MindSpore框架。后来在学校的一些课程中,例如机器学习基础、深度学习与大数据技术、自然语言处理等智能基座合作课程上,再次与MindSpore相遇,并在课程作业中,参考昇思社区提供的技术文档,使用MindSpore进行了初步实践,发现MindSpore上手容易,功能强大,能方便地进行AI应用开发。
后来在智能基座社团中又多次组织与MindSpore相关的活动,对开源社区有了更多的了解与更深刻的认识,发现昇思开源社区十分活跃,有许多门槛不同开源活动可以参与,比如MSG、开源实习、开源之夏以及各种比赛等,不仅能积累项目开发经验,还能获得一定奖励。于是,我后面也参加了MindSpore NLP套件的开源活动,并持续依托MindSpore NLP套件为平台,参加了MindSpore的开源实习和开源之夏活动。
**昇思MindSpore:**12月14日的昇思峰会上,您被评为杰出开发者,由此可以看到您为昇思MindSpore和昇思MindSpore开源社区做出了很多贡献,能否简单介绍下您贡献的内容?
**曾子瑄:**我在MindSpore开源社区的工作都与MindSpore NLP套件紧密结合,也是作为MindSpore NLP SIG的核心成员先后完成了四个大模型的迁移工作,一个Falcon大模型微调案例开发,GPU后端的Flash Attention算子在MindSpore NLP的接入与调优,实现了两倍以上的推理速度提升。今年开源之夏做了bitsandbytes量化库迁移到MindSpore NLP的工作,降低了模型推理对显存的需求,提升了计算性能,增强了模型部署在端侧的可行性。
**昇思MindSpore:**请问您的贡献在工作和学习中有什么结合,有什么印象比较深刻的事情?
**曾子瑄:**我把开源实习的工作融合进了我的本科毕业设计里面,综合成了一个模型迁移、模型应用,再到优化的过程,毕业设计成绩优秀,在开源之夏完成的量化库迁移的工作也与我现在的研究方向有关,总体上说开源社区的经验与我日常的学习工作是相互促进的关系,我能从实践中锻炼工程能力,捕捉到产业需求风向,从而影响到我对研究方向的把握,我在昇思社区的开源活动中学习到的技能对于以后工作或者科研来说也是十分有帮助的。
比较印象深刻的是在开源之夏的项目开发过程中,因为需要迁移的bitsandbytes库本身软件耦合程度高,关于算子接入的问题刚开始一直没找到合适的解决方案,后来摸清楚了项目本身的构建和执行逻辑,再跟MindSpore布道师和负责MindSpore自定义算子接口的工程师一起讨论,得出了基本解决方案,随后顺利地完成了程序中由上至下一条核心执行线路的移植,奠定了项目完成的基础。
**昇思MindSpore:**在参与昇思MindSpore开源社区中,有什么比较深刻的感受/体会/收获吗?
**曾子瑄:**整体上收获还是蛮大的,归纳一下,大概是三点:一是个人实践能力的提升,特别是对于大型工程的分析和debug能力,还有对于具体技术问题的解决能力;二是开拓视野,参与昇思开源社区学习到了众多人工智能领域的最新前沿知识,了解了最新的产业动态,知道了现在大家都在做什么,指导了自己以后应该怎么做;三是机会和资源,我在MindSpore社区中得到了许多锻炼机会,昇思开源实习与开源之夏活动都是很好的实践平台,包括受邀参加峰会,这对我个人的成长,不仅仅是在技术层面,是有好处的。另外开源社区的开发经历以及获得的一些荣誉,在找实习、和保研过程中也起到了很大的帮助。
**昇思MindSpore:**对于昇思MindSpore开源社区,有没有什么比较推荐的地方?
**曾子瑄:**在这里给MindSpore NLP打个广告,MindSpore NLP是一个优秀的NLP开源开发套件,模型库丰富,开发接口与huggingface transformers对标,上手快,易用性好,并且提供了丰富的应用案例与实践教程,欢迎对nlp技术与大模型技术的开发者们加入MindSpore NLP SIG,随着SIG一起成长,逐步成为SIG的领衔成员,NLP领域的出色工程师。另外,昇思开源社区开设了昇思MindSpore技术公开课,内容丰富新颖且全面,是学习大模型的一个良好课程,并包含了许多使用MindSpore开发大模型的技术案例,加上社区提供的开源活动和比赛,实现以练促学,成长速度遥遥领先。
**昇思MindSpore:**作为过来人,有没有什么话想对过去的自己/学弟学妹/刚加入昇思MindSpore的开发者说呢?
**曾子瑄:**昇思开源社区是一个很好的平台,汇聚了对AI感兴趣的开发者们,大家在一起交流技术问题,一起打比赛做项目,产生良好的沟通与交流,在社区中可以获取到你想要的资源,也有提供免费的算力。我觉得对于年轻的朋友们,特别是对相关技术领域积累还比较少的同学们,可以加入到昇思开源社区,大胆尝试,边学边实践,可以从一些门槛比较低的比赛或者活动入手,如果熟悉了MindSpore的基本开发,可以尝试申请开源实习,选择自己感兴趣的任务进行实践。有了独立完成某个项目子模块的开发能力之后,可以申请开源之夏项目。这是一条很高效的成长路径,相信这是对个人的成长很有帮助的,在这个过程中会结识志同道合的朋友,在技术圈积累人脉,获得很多除物质之外的更珍贵的东西,这是我的成长路径,与大家共勉。希望大家积极主动、勇敢追求,昇思社区永远欢迎你们。