开源之夏系列 | 基于昇思MindSpore实现的工业场景下裂缝的识别及宽度测量策略开发
开源之夏系列 | 基于昇思MindSpore实现的工业场景下裂缝的识别及宽度测量策略开发
开源之夏,是由中国科学院软件研究所发起,专为高校学生精心打造的活动。旨在鼓励广大学子积极参与开源软件的开发与维护,推动优秀开源软件社区的蓬勃发展。
目前,开源之夏2024已圆满结项!在本届开源之夏中,不少开发者跟随昇思MindSpore一起,在开源的世界里畅游,成功完成项目任务。在此,昇思 MindSpore 开源社区邀请了开源之夏的开发者们,分享他们在本次活动中的宝贵经验与心得。我们希望通过这些精彩的项目经历和实战技巧,能够激发更多创意火花,帮助大家提升技术能力。本文为昇思MindSpore 开源之夏项目经验分享系列第1篇。

项目基本介绍
1、项目名称:工业场景下裂缝的识别及宽度测量策略开发
2、项目导师:王晓丽
3、项目链接:https://summer-ospp.ac.cn/org/prodetail/24c6d0542
4、项目描述:裂缝作为隧道病害的一种,影响了铁路交通的安全运营,因此对隧道裂缝的有效检测至关重要。隧道裂缝图像普遍存在着低对比度,光照不均匀,噪声污染严重等问题。本项目对 1-5mm 的裂缝构建一个实例分割模型来进行精准识别。构建了包括 U-Net 及其变种(如 Res-UNet 和 Vgg-UNet)模型的实现和推理流程,同时使用了形态学分析的方法对图像中的区域进行精确分析。结合模型预测得到的裂缝区域,成功过滤掉了非裂缝区域的噪声。通过一系列后处理步骤,有效减少了伪裂缝的干扰,显著提升了裂缝检测结果的完整性和准确性。同时,分割模型在裂缝数据集的 mIoU 大于 70%,并且在华为云 AI-Gallery 平台上提供了可交互式的 Demo 。
项目选择初衷
**1、自身收益:**参与这个项目的最重要原因之一是为了提升自己的能力,尤其是图像处理和深度学习领域的技术。在研究工作中,尤其是在实际应用中,深度学习技术有着广泛的应用场景,而这个项目正好涉及了隧道裂缝检测的实际问题,结合了图像分割和深度学习模型的实现,能帮助我在这些技术上进一步提升。此外,项目使用了 MindSpore 框架,这对我来说是一个全新的挑战。通过这个项目,我不仅能够更深入理解和掌握 MindSpore 框架的使用,还能够积累在实际问题中应用该框架的宝贵经验。更重要的是,这些技能和经验将为我未来的科研工作和职业发展打下坚实的基础,使我能够应对更复杂的研究任务和技术挑战。
**2、兴趣驱动:**我对计算机视觉和机器学习充满兴趣,尤其是在实际场景中的应用。在本科阶段,我学习了相关课程,并了解了计算机视觉和机器学习的基本原理与技术。这些课程为我奠定了坚实的理论基础,随着对该领域的学习加深,我逐渐意识到这些技术不仅仅是学术研究的热点,也是解决实际问题的关键工具。隧道裂缝检测项目不仅能够应用我在学术上所学的知识,还能让我在实践中不断探索和尝试。
**3、开发能力:**在评估自己的开发能力时,我认为这个项目是我目前能力范围内可以完成的任务。虽然这个项目涉及一定的技术难度,但我相信通过自己的努力和学习,能够在规定的时间内完成各项任务。此前,我也做过一些与图像处理相关的项目,积累了一些实践经验,这让我对解决实际问题有了一定的信心。另外,我在深度学习框架如 PyTorch 的使用上也有一定的了解和经验,这将帮助我快速适应项目中对深度学习模型的实现和优化要求。即使面对新的技术或框架,我也具备足够的学习能力和解决问题的信心。
**4、导师沟通:**与导师的初步沟通中,我得到了许多宝贵的指导与鼓励。导师对该项目的认可和对我的能力给予的信任,使我更加坚定了参与这个项目的决心。导师对项目的充分支持,让我更加有信心能够在规定的时间内顺利完成任务,同时也促使我更加注重实际问题的解决。我相信通过与导师的紧密合作,我能够不断克服挑战、提升自己的能力,并为项目的成功做出贡献。
项目方案介绍
本项目需要开发一个用于工业隧道裂缝检测与宽度测量的实例分割模型。随着隧道建设与维护需求的不断增长,裂缝检测作为结构健康监测的重要环节,成为确保隧道安全的关键技术。本项目基于 MindSpore 框架,采用 U-Net 及其变种(如 Res-UNet、Vgg-UNet)进行图像分割任务,结合形态学分析方法,精确识别裂缝区域。
项目分析
0****1
问题定位
隧道裂缝的检测与宽度测量是结构监测中的核心任务之一。传统的人工检测方法效率低、准确度有限,且成本较高。通过机器学习和深度学习方法,能够实现高效的自动化检测,从而减少人工干预,提高检测精度与速度。裂缝的宽度测量是评估隧道结构健康状态的重要指标,尤其在 1-5mm 范围内的裂缝尤为关键。本次项目从端到端的角度考虑,即需要通过输入一张带有裂缝的隧道照片,最终输出一张带有检测得到裂缝信息的照片,这符合计算机视觉任务里的:图像分割,因此需要针对图像分割任务进行调研,选取模型进行实现。。语义分割(semantic segmentation)是图像处理和机器视觉领域中一个重要的任务,旨在对图像进行全面的理解。具体而言,语义分割将图像中的每一个像素进行分类,赋予其特定的标签。
0****2
数据来源
本项目使用了隧道裂缝的标注数据集。数据集中的图像为隧道裂缝的灰度图,通过手动标注或自动化工具标定裂缝的边界和宽度信息。为提高模型的泛化能力,数据集包含了不同类型、不同尺寸、不同分布的裂缝样本。
0****3
挑战
**1、小尺寸裂缝的检测:**裂缝的宽度通常较小,分辨率较低的图像可能导致裂缝信息丢失,影响模型性能。
2、噪声干扰: 在实际场景中,裂缝图像中存在较多噪声,尤其是非裂缝区域的杂散信息(如灰尘、裂缝的背景结构等),需要精确过滤。
3、裂缝连通性: 在一些图像中,裂缝由于噪声或者分割错误而出现断裂,需要通过形态学操作处理裂缝的连通性问题。
项目实现思路
0****1
模型选择
本项目基于 U-Net 架构进行裂缝的实例分割,U-Net 在医学图像分割等领域表现优秀,能够较好地处理像素级别的分割问题。为了提升模型的性能,本项目引入了 U-Net 的变种(如 Res-UNet 和 Vgg-UNet),这些变种通过不同的骨干网络提高了模型的特征提取能力。
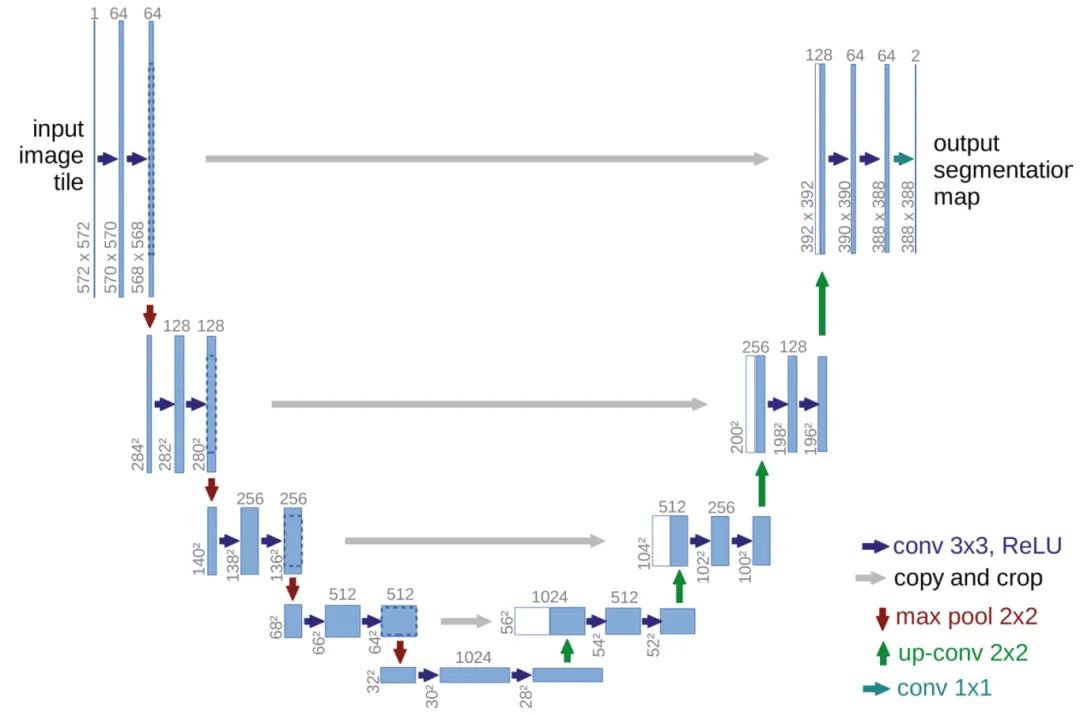
首先介绍最经典的 U-net 模型,U-Net 是一种经典的语义分割模型,最初用于医学图像分析。其网络架构采用 Encoder-Decoder 结构,左侧的 Encoder 部分用于提取图像特征,右侧的 Decoder 部分通过上采样重构图像。自 2015 年提出以来,U-Net 衍生出了多种改进版本,如 Res-UNet、UNet 3+ 等。U-Net 的网络结构使其在处理低对比度和噪声较大的图像时具备良好的表现,因此在本项目中得到采用。网络结构如下图所示:
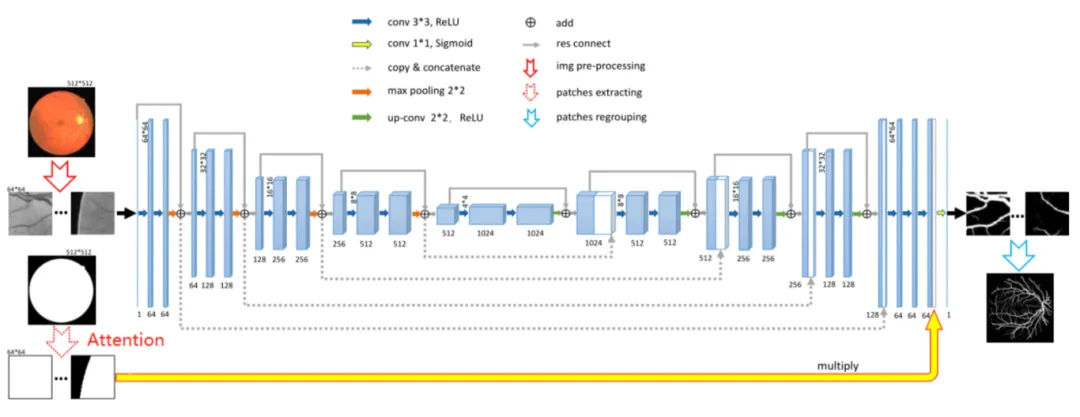
 Res-UNet 是在 U-Net 基础上引入残差连接的改进模型,广泛用于视网膜血管分割等任务。该模型通过将 U-Net 中的每个子模块替换为包含残差连接的模块,增强了网络对深层特征的学习能力。在本项目中,借鉴 ResNet、Attention 和 U-Net 的结合,提升了模型在复杂场景下的分割精度。详细的网络结构如下图所示:
Res-UNet 是在 U-Net 基础上引入残差连接的改进模型,广泛用于视网膜血管分割等任务。该模型通过将 U-Net 中的每个子模块替换为包含残差连接的模块,增强了网络对深层特征的学习能力。在本项目中,借鉴 ResNet、Attention 和 U-Net 的结合,提升了模型在复杂场景下的分割精度。详细的网络结构如下图所示:
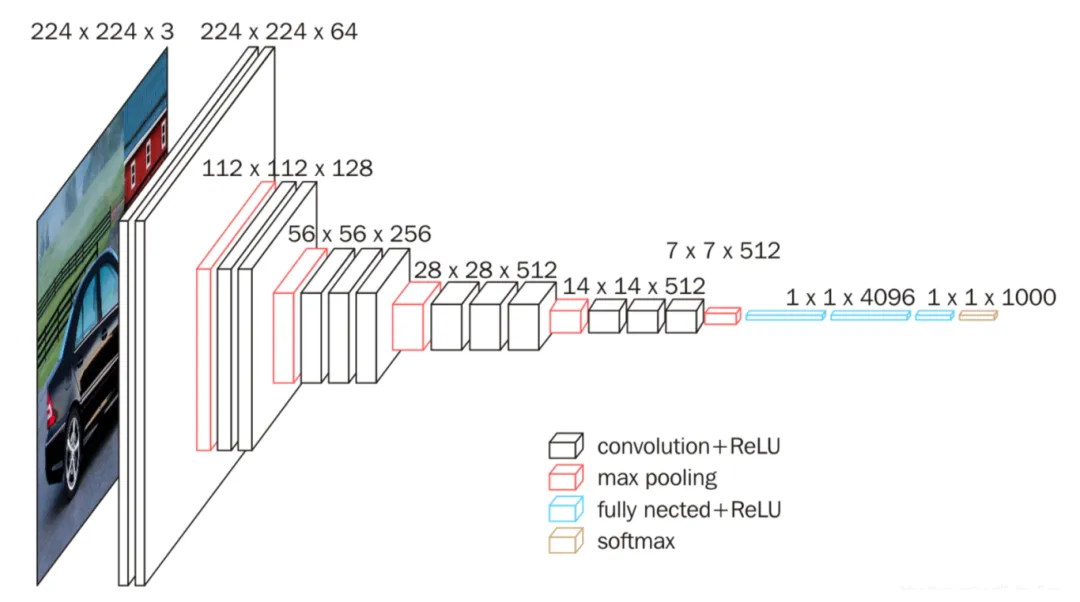
Vgg-UNet 将 U-Net 的 Encoder 部分替换为 VGG-16 网络结构,进一步提升特征提取的效果。VGG-16 的输入为 224×224 的 RGB 图像,输出为 1000 个分类预测值,主要用于大规模图像分类任务。VGG-16 通过全连接层的卷积化处理,保留了更多的空间信息,使其能够生成输入图像的二维热力图。该模型在裂缝检测中有助于精确定位裂缝位置,并提高了分割结果的空间分辨率。下图展示了 VGG-16 的网络结构:
02
数据预处理
数据预处理的核心是增强图像的质量,主要包括:
1、去噪: 采用滤波等技术去除图像中的噪声。
2、图像增强: 通过旋转、缩放、镜像等方式扩充数据集,提升模型的泛化能力。
03
模型训练与优化
1、损失函数: 采用交叉熵损失与 Dice 系数损失相结合的方法,强化对裂缝区域的精确分割能力。
**2、优化算法:**使用 Adam 优化器进行梯度更新,同时设定早停策略防止过拟合。
3、评估指标: 主要使用 mIoU(平均交并比)作为评估指标,目标是达到 70%以上的 mIoU 值。
0****4
结果分析与改进
在模型训练过程中,进一步通过学习率调整、批量大小优化等方法,提高模型的性能。同时,通过图像的后处理步骤(如形态学闭运算),对分割结果进行精细调整,提升裂缝区域的连通性和准确性。
最终方案
0****1
模型构建
本项目以 Res-UNet 和 Vgg-UNet 为基础模型。其中 Res-UNet 它在 U-Net 基础上引入残差连接的改进模型,该模型通过将 U-Net 中的每个子模块替换为包含残差连接的模块,进而增强了网络对深层特征的学习能力。Vgg-UNet 模型将 U-Net 的 Encoder 部分替换为 VGG-16 网络结构,来进一步提升特征提取的效果。vgg16 通过堆叠多个较小的卷积层和池化层来构建深层网络,保留了更多的空间信息。为了更好的捕捉图像中的裂缝信息。因此,本项目基于 MindSpore 2.2.14 版本对两者均进行了训练,并对二者推理结果进行了集成。
0****2
模型训练
本项目共用 3192 组数据,利用 MindSpore 的自定义数据集功能,实现了一种 Multi-Class 的数据集格式,通过固定的目录结构获取图片和对应标签数据。将裂缝的兴趣区域通过 mask 标签标注为白色,背景部分则以黑色表示,示意图如下。

0****3
对推理结果进行后处理
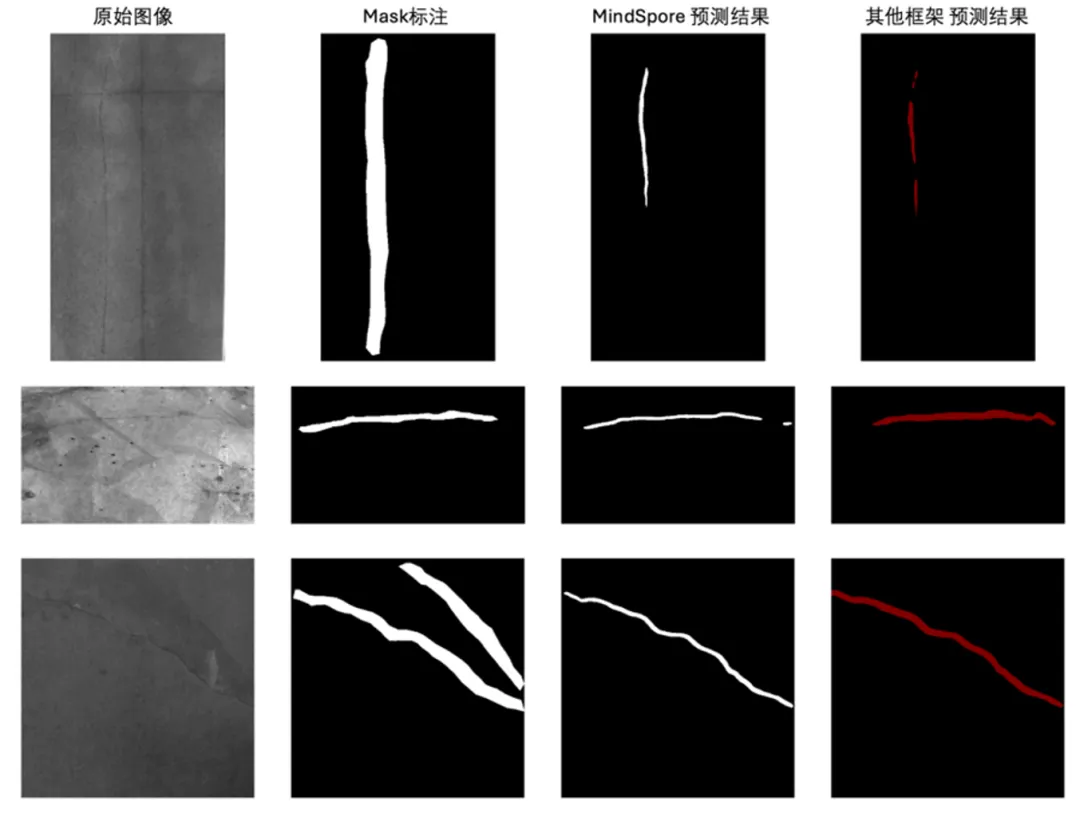
推理结果如图中所展示,展示内容从左到右依次为:原始图片、裂缝兴趣区域 mask 的真实标签(ground truth)、在 MindSpore 框架下使用 Res-Unet 和 Vgg-Unet 推理后集成的结果,以及其他框架下利用 Vgg-Unet 的推理结果。
然后,使用数字图像处理技术来进一步提升裂缝预测精度。首先利用改进的高斯差分算法 XDoG (Extended Difference of Gaussians) 来对图像进行边缘检测,该算法巧妙的引入参数来控制了截止频率较高的高斯滤波器的强度,以及对阈值函数进一步修正(通过引入 tanh 函数)来实现了较好的边缘检测结果。然后利用阈值进行二值化边缘,接着对原图取反色,方便后续的去除噪声操作。最后以兴趣区域作为蒙版,对图像进行裁剪得到兴趣区域内的边缘信息。
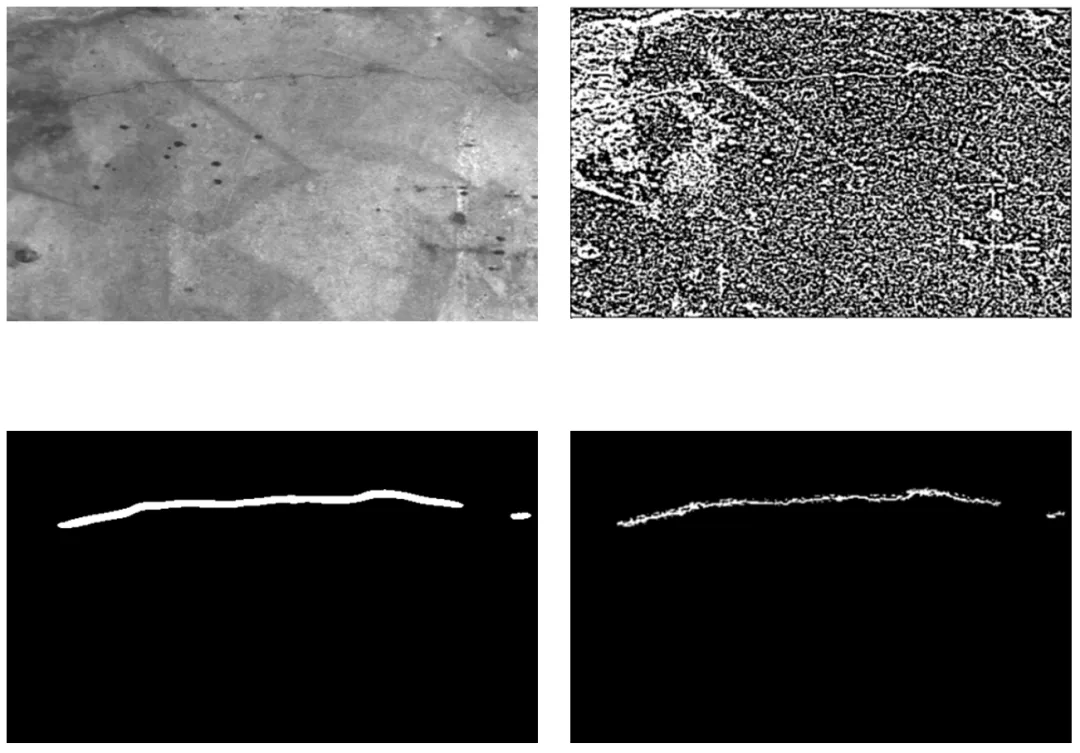
最后,利用 RegionProps,根据形态学信息来对图像进行分析。通过轮廓面积、长宽比、离心率、圆度等参数,去除兴趣区域内非裂缝的噪声。使用形态学闭操作,先进行膨胀再进行腐蚀,确保裂缝区域的连通性,避免因噪声或分割误差导致裂缝出现断裂的情况。

项目总结
本项目基于 MindSpore 框架,构建了裂缝数据集,针对隧道裂缝检测任务,实现了 vggnet 为骨干和 resnet 为骨干的 unet 网络。结合强化高斯差分算法、形态学分析进行后处理,从而提升了裂缝边缘提取的精度。
同时在华为云 AI-Gallery 平台上提供了可交互式的 Demo ,链接如下:https://pangu.huaweicloud.com/gallery/asset-detail.html?id=bdbaa83e-a8d1-4665-9c61-50333f4985a4