昇思MindSpore原生论文 | 一种基于MindSpore框架的讽刺识别模型CGL-MHA
昇思MindSpore原生论文 | 一种基于MindSpore框架的讽刺识别模型CGL-MHA
论文标题
An Innovative CGL-MHA Model for Sarcasm Sentiment Recognition Using the MindSpore Framework
论文来源
arXiv: 2411.01264
论文链接
https://arxiv.org/abs/2411.01264
代码链接
models/research/arxiv_papers/CGL-MHA at master · mindspore-lab/models
昇思MindSpore作为开源的AI框架,为开发人员带来端边云全场景协同、极简开发、极致性能的体验,支持国内高校/科研机构发表1700+篇AI顶会论文。为鼓励基于昇思MindSpore进行原生创新,昇思开源社区转载、解读系列原生arXiv论文,本文为昇思MindSpore AI arXiv论文系列第4篇。
作者:QIN ZHENKI,LUO QINING,NONG XUNYI
感谢各位专家教授与同学的投稿,更多精彩的论文精读文章和开源代码实现请访问Models。更多内容请访问: https://gitee.com/mindspore/community/issues/I9W2Z3

研究背景
在自然语言处理(NLP)领域,讽刺检测作为一项重要的情感分析技术,受到了学术界和工业界的广泛关注。随着社交媒体的普及,大量用户生成内容中包含讽刺性表达,使得自动化情感分析变得更具挑战性,进一步推动了讽刺检测技术的研究与应用。近年来,深度学习的引入为讽刺检测带来了革命性的进展。特别是卷积神经网络(CNN)和循环神经网络(RNN)等端到端模型,不仅简化了讽刺检测的流程,还显著提高了模型的准确性。 然而,随着数据量和模型复杂度的提升,模型的存储和计算成本也不断攀升,尤其在资源受限的环境中,传统深度学习模型可能面临较大的应用挑战。 为了解决高计算需求问题,Transformer模型及其多头注意力机制逐渐被引入到讽刺检测任务中,以其并行处理能力和长距离依赖建模能力取得了显著进展。然而,Transformer模型同样存在局限性,比如大量的参数和高昂的计算开销,这在嵌入式设备或低资源环境中可能难以实现。针对这一问题,研究人员不断探索更高效的模型结构,希望在确保讽刺检测精度的同时,降低模型复杂度并提升计算效率。
作者介绍
本项目研究成果来自广西警察学院大数据与警务技术实验室,主要作者为QIN ZHENKI,LUO QINING,NONG XUNYI,团队主要研究方向为自然语言处理、知识图谱、大语言模型,对MindSpore有丰富的实践经验,多次在昇腾AI创新大赛、鲲鹏应用创新大赛取得佳绩,其中在昇腾MindSpore AI创新大赛获广西区三等奖。
论文简介
随着自然语言处理(NLP)技术的快速发展,讽刺检测的准确性和效率成为当前研究的重点话题。本研究提出了一种创新的CGL-MHA模型,旨在平衡讽刺检测任务中的模型效率与性能。该模型采用卷积神经网络(CNN)作为初步特征提取模块,识别文本中的局部模式和n-gram特征,有效捕捉可能包含讽刺信息的短语。在序列建模部分,编码器引入了门控循环单元(GRU)和长短期记忆网络(LSTM),前者专注于捕捉短期依赖关系,而后者能够处理长距离的上下文信息,两者的结合增强了模型对讽刺性文本的复杂依赖关系的理解。模型整体处理流程如下图所示:
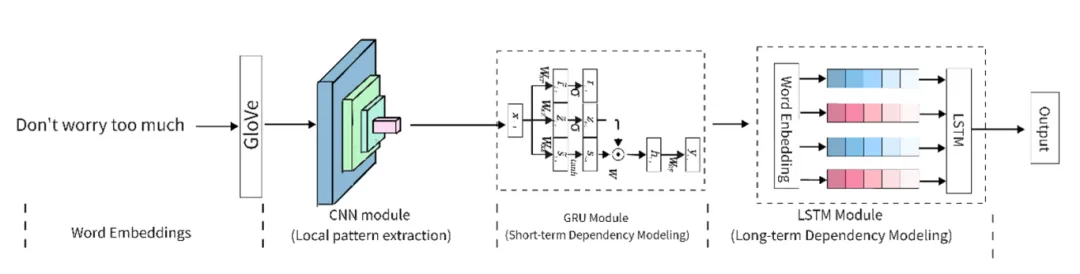



多头注意力机制可以动态聚焦于讽刺性强的文本部分,提升模型对讽刺表达的敏感度和解释性。
实验结果
本研究在多个讽刺检测数据集上评估了CGL-MHA模型的性能,主要使用Headlines公开数据集。实验结果显示,CGL-MHA模型在讽刺检测任务中的准确率和F1分数显著优于传统基线模型(如CNN、GRU和SVM),验证了模型架构的有效性。
实验结果显示,CGL-MHA模型在Headlines数据集上取得了81.20%的准确率和80.77%的F1分数。相比传统的讽刺检测模型,CGL-MHA利用CNN提取局部特征、GRU和LSTM捕捉短期和长期依赖关系,再加上多头注意力机制的聚焦能力,使得模型能够有效识别文本中的讽刺表达。
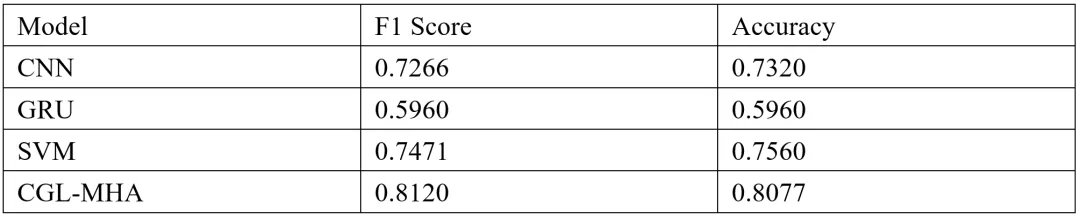
Table 1 对比实验结果
此外,我们还进行了消融实验,以评估模型各组件(CNN、GRU、LSTM和多头注意力)对整体性能的贡献。实验结果表明,去除任一组件都会导致模型性能的显著下降,尤其是多头注意力机制和预训练的词嵌入层对模型的讽刺检测效果起到了关键作用。
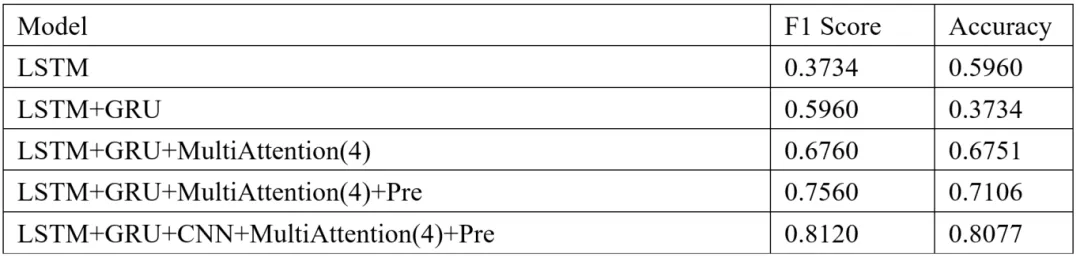
Table 2 消融实验结果
综上所述,CGL-MHA模型在准确率和F1分数上均表现出色,并通过昇思MindSpore框架实现了高效的训练和优化。实验结果证明了该模型在讽刺检测任务中具有较强的应用潜力和优势。
总结与展望
本研究提出了一种基于昇思MindSpore框架的创新型讽刺检测模型CGL-MHA,通过结合CNN、GRU、LSTM和多头注意力机制,显著提升了讽刺检测的准确性和效率。实验结果表明,该模型在Headlines和Riloff数据集上的准确率和F1分数均优于传统方法,验证了模型在复杂文本特征提取和讽刺表达识别中的有效性。消融实验进一步证明了多头注意力机制和GRU-LSTM模块对讽刺检测性能的提升作用。在未来工作中,我们计划进一步优化模型结构以降低计算复杂度,使其更适合资源受限的环境。同时,探索多模态讽刺检测(如结合文本、图像和音频等信息)将是一个有前景的方向,因为讽刺表达往往不仅依赖于文本内容,还依赖于语气、表情等非语言特征。此外,昇思MindSpore的分布式计算和硬件加速显著缩短了模型训练时间,使得CGL-MHA在大规模数据上的应用更具实用性。我们期望CGL-MHA模型能够在讽刺检测和其他复杂情感分析任务中展现出更强的性能和应用价值。