昇思MindSpore原生论文 | 一种新型的边缘计算模型访问控制和隐私增强方法
昇思MindSpore原生论文 | 一种新型的边缘计算模型访问控制和隐私增强方法
论文标题
A Novel Access Control and Privacy-Enhancing Approach for Models in Edge Computing
论文来源
arXiv
论文链接
https://arxiv.org/abs/2411.03847
代码链接
https://github.com/mindspore-lab/models/tree/master/research/arxiv\_papers/Style-IP
昇思MindSpore作为开源的AI框架,为开发人员带来端边云全场景协同、极简开发、极致性能的体验,支持国内高校/科研机构发表1700+篇AI顶会论文。为鼓励基于昇思MindSpore进行原生创新,昇思开源社区转载、解读系列原生arXiv论文,本文为昇思MindSpore AI arXiv论文系列第3篇。
作者:Peihao Li
感谢各位专家教授与同学的投稿,更多精彩的论文精读文章和开源代码实现请访问Models。更多内容请访问: https://gitee.com/mindspore/community/issues/I9W2Z3

研究背景
随着边缘计算的快速发展和广泛应用,它在分布式计算、实时数据处理以及智能设备互联互通方面展现出了显著优势。然而,边缘计算环境中数据和模型的安全性与隐私保护问题也日益突出。边缘计算场景中深度学习模型和数据的分布式特性使得它们更加容易受到攻击者的利用,可能导致模型盗窃和数据泄露等问题。相关研究表明,超过80%的在边缘应用中部署的机器学习模型可能被攻击者通过直接访问或简单的动态分析技术提取,这对用户隐私构成了严重威胁,并可能导致知识产权的重大损失。这些威胁不仅危及单个边缘设备的安全,还可能扩展到整个边缘计算网络,进而影响整个系统的可靠性和可信度。
在边缘计算环境中,解决模型和数据安全问题主要依赖传统的加密和认证方法,例如基于公钥基础设施(PKI)的认证和对传输过程的对称加密。然而,这些方法在面对边缘计算环境的动态性和异构性时表现出明显的局限性。研究表明,传统的访问控制方法难以应对边缘设备频繁的连接变化以及异构网络环境中所需的适应性。此外,模型水印技术虽然能有效标记所有权,但它是一种被动的保护手段,无法防止未经授权的访问,且不足以主动保护知识产权。另一方面,现有的隐私保护技术在边缘计算场景中面临重大挑战。传统的技术,如同态加密和差分隐私,由于边缘设备计算资源有限且对实时处理有较高要求,难以在边缘环境中部署。因此,亟需开发创新的解决方案,以增强边缘计算环境中模型和数据的安全性与隐私保护。
作者介绍
论文第一作者为Peihao Li,研究方向为人工智能安全,知识产权保护, 对MindSpore和PyTorch这两个流行的深度学习框架有丰富的实践经验,深入研究过基于深度学习模型的智能感知、后门学习、拆分学习、模型知识产权保护等关键技术。
论文简介
随着边缘计算技术的广泛应用以及深度学习模型在这些环境中的日益普及,模型和数据的安全风险与隐私威胁日益加剧。攻击者可以利用各种技术非法获取模型或滥用数据,导致知识产权侵犯和隐私泄露等严重问题。现有的模型访问控制技术主要依赖传统的加密和认证方法,然而这些方法在动态环境中的灵活性和适应性方面存在显著限制。尽管模型水印技术在标记模型所有权方面取得了一些进展,但它们在主动保护知识产权和防止未经授权访问方面的能力仍然有限。为了解决这些挑战,我们提出了一种专门针对边缘计算环境的全新模型访问控制方法。该方法利用图像风格作为许可机制,将风格识别嵌入到模型的操作框架中,从而实现内在的访问控制。因此,部署在边缘平台上的模型仅能对特定风格的许可数据进行正确推理,对于任何其他数据则无法进行有效推理。通过限制输入数据的类型,该方法不仅防止了攻击者对模型的未经授权访问,还增强了终端设备上数据的隐私保护。
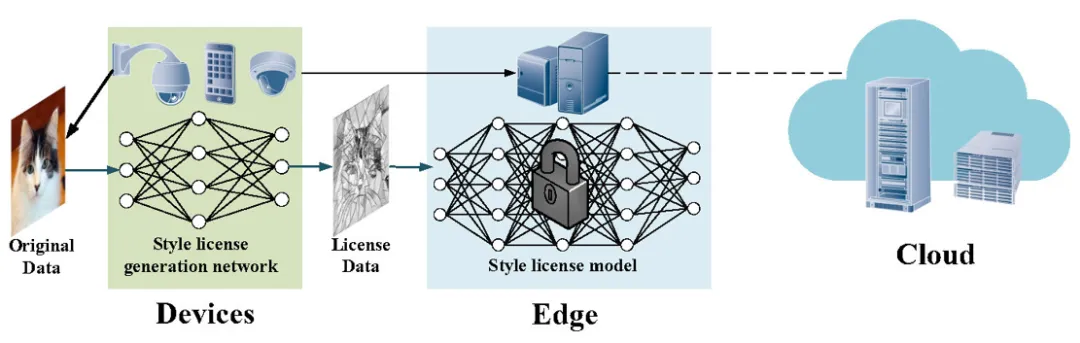
图1 方法整体架构图
这里,我们详细描述了本文提出的全新访问控制方法。如图1所示,我们以图像分类任务为例,阐述该方法的具体工作流程。首先,我们训练一个轻量级的风格许可生成网络,该网络旨在将终端设备收集的原始数据转换为具有特定风格的许可数据。接着,许可数据被传输到边缘平台,由模型进行推理。该模型通过使用原始数据、风格数据和许可数据训练,并基于我们提出的风格许可损失函数进行优化。该模型的特点是只能对符合授权风格的数据进行有效推理。
通过这种方法,我们实现了两个关键目标。首先,我们将访问控制机制直接嵌入到部署在边缘平台上的深度学习模型中。这种集成方式确保了即使攻击者获得了模型的参数和架构,他们也无法在没有正确风格许可的情况下使用该模型,从而主动保护了模型的知识产权,防止未经授权的使用。其次,在边缘计算场景中,终端设备通常容易受到中间人攻击、侧信道攻击以及网络流量监控等威胁。我们的方法通过在传输前将原始数据转换为风格化数据,减少了这些风险,从而在一定程度上增强了原始数据的隐私保护。接下来将对该方法进行更为详细的解释。
为了确保模型仅在风格许可数据上有效,而在其他数据上无效,我们为风格许可模型设计了一个专门的训练方案和损失函数。风格许可模型的训练过程涉及三个数据集:包含许可风格图像的风格数据集、原始非风格化图像的原始数据集、通过将原始图像转换为许可风格得到的风格化原始图像数据集。为了实现我们的目标,我们开发了一个专门的损失函数,旨在风格许可模型的训练过程中实现收敛,损失函数公式如下:


实验结果
我们通过评估风格许可模型的准确性来验证我们提出方法的可用性,所有实验结果都是基于MindSpore框架得出的。首先,我们在 VGG16、ResNet18 和 MobileNetV2 上使用 MNIST、CIFAR-10 和 FaceScrub 基准数据集训练了传统的分类模型,并将它们的准确性作为基准指标。随后,我们使用风格数据集(Styled Dataset)、原始数据集(Original Datasets)及其相应的风格化原始数据集(Styled-Original Datasets)训练了风格许可模型。然后,我们将风格许可模型在原始数据和许可数据上的准确性与基准模型进行了比较。实验结果如图2所示。
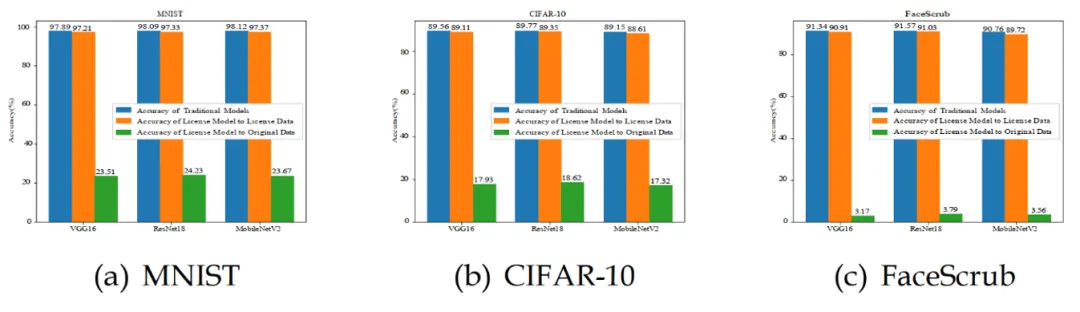
图2 风格许可模型在原始数据和许可数据上的准确率与基准模型的对比
如图2所示,风格许可模型在许可数据上的准确率与基准模型在所有三种神经网络和数据集上的准确率非常接近。相比之下,风格许可模型在原始数据上的准确率明显低于基准模型的准确率。这一结果表明,我们的方法能够有效地保持模型准确性,同时防止未经授权的使用,从而验证了该方法的高可用性。
总结与展望
本文提出了一种基于数据风格的深度学习模型内在访问控制方法,适用于边缘计算环境。该方法为模型定制了一个许可证生成器,并设计了一种独特的训练损失函数用于风格许可证模型,确保训练完成的模型只能有效推理特定风格的许可证数据,而对其他数据则无效。通过将许可证生成器部署在终端设备上,将模型部署在边缘平台上,该方法主动防止了未经授权的访问,保护了模型的知识产权,并增强了终端设备上的数据隐私保护。实验结果表明,该方法在许可证数据上的准确性保持较高,同时显著降低了模型在原始数据上的准确性,有效防止了未经授权的访问。
MindSpore作为一个新兴的深度学习框架,显示出了其灵活性和易用性,特别是在支持多种硬件平台上。本研究利用了MindSpore的特性来实现和验证提出的模型,发现其提供了强大的工具链和丰富的API集合,有助于快速原型设计和模型迭代MindSpore有潜力成为深度学习框架中的佼佼者之一。
MindSpore提供了丰富的功能和工具,可以帮助开发者们更快地实现自己的想法。社区的活跃也为解决问题和分享经验提供了一个良好的平台。希望更多的开发者能够加入进来,共同推动MindSpore的发展,并创造出更多有意义的应用。