基于昇思MindSpore实现知识图谱增强多模态类比推理
基于昇思MindSpore实现知识图谱增强多模态类比推理
**作者:**李锐锋 来源:知乎
论文标题
Multimodal Analogical Reasoning over Knowledge Graphs
论文来源
ICLR 2023
论文链接
https://openreview.net/forum?id=NRHajbzg8y0P
代码链接
https://github.com/mindspore-lab/models/tree/master/research/ZJU/mkg\_analogy
昇思MindSpore作为开源的AI框架,为产学研和开发人员带来端边云全场景协同、极简开发、极致性能、安全可信的体验,支持国内高校/科研机构发表1000+篇AI顶会论文。本文是昇思MindSpore AI顶会论文系列第40篇,我选择了来自浙江大学计算机科学与技术学院的张宁豫老师团队发表于ICLR的一篇论文解读,感谢各位专家教授同学的投稿,更多精彩的论文精读文章和开源代码实现请访问Models。

01
研究背景
类比推理是一种感知和利用两种情况或事件之间的关系相似性的能力,在人类认知中占有重要地位,并且在众多领域例如教育、创造发挥着重要作用。一些学者考虑将类比推理与人工智能进行结合,在计算机视觉和自然语言处理领域都进行了广泛应用。其中,CV领域将视觉与关系、结构和类比推理相结合,测试模型对于基本图形的的理解和推理能力;NLP领域通过词语的线性类比来验证模型的文本类比推理能力。上述任务大多遵循(a,b):(c,d)的形式对深度学习模型的类比推理能力作了初步分析,但都仅限于单模态,没有考虑神经网络是否有能力从不同模态中捕获类比信息。然而,Mayer认知理论指出,人类通常在多模态资源中能表现出更好的类比推理能力,那人工智能模型是否具有这种性质呢?
这篇论文提出了一个基于知识图谱的多模态类比推理任务,任务形式可以形式化为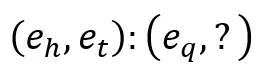 。本文构建了一个多模态类比推理数据集MARS和一个多模态知识图谱数据集MarKG作为支撑。为了评估多模态类比推理过程,本文基于心理学理论的指导,对多模态知识图谱嵌入基线和多模态预训练Transformer基线在MARS上进行了综合实验。本文进一步提出了一个新型多模态类比推理框架MarT,它可以随时插入任何多模态预训练的Transformer模型中,并能产生更好的类比推理性能。
。本文构建了一个多模态类比推理数据集MARS和一个多模态知识图谱数据集MarKG作为支撑。为了评估多模态类比推理过程,本文基于心理学理论的指导,对多模态知识图谱嵌入基线和多模态预训练Transformer基线在MARS上进行了综合实验。本文进一步提出了一个新型多模态类比推理框架MarT,它可以随时插入任何多模态预训练的Transformer模型中,并能产生更好的类比推理性能。
02
团队介绍
张宁豫,浙江大学副教授,浙江大学启真优秀青年学者,在高水平国际学术期刊和会议上发表多篇论文,代表工作有KnowPrompt、DeepKE、EasyEdit、OceanGPT(沧渊)等,获浙江省科技进步二等奖,IJCKG最佳论文/提名2次,CCKS最佳论文奖1次, 担任ACL、EMNLP领域主席、ARR Action Editor、IJCAI 高级程序委员。
03
论文简介

多模态类比推理数据集MARS和背后的多模态知识图谱MarKG的构建过程如上图所示。首先,从两个文本类比推理数据集E-KAR和BATs中收集种子实体和种子关系;其次,将这些实体和关系映射到大型知识库Wikidata中并进行实体和关系的统一规范化;之后,从Google图片引擎以及多模态数据Laion-5B中检索实体图片并使用一系列的措施去过滤低质量图片;最后,从中检索高质量的类比数据来构建MARS数据集。
本文在一些基线模型上进行了测试,包括三个多模态知识图谱嵌入模型(IKRL, TransAE, RSME)和五个基于transformer的多模态预训练模型(VisualBERT, ViLT, ViLBERT, FLAVA和MKGformer)。
3.1 多模态知识图谱嵌入模型
对于多模态知识图谱嵌入模型,本文采用Pipeline的方式来求解类比推理问题。包括Abduction - Mapping - Induction等三个步骤。其中,Abduction用来预测类比示例 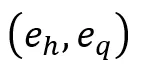 的潜在关系,Mapping将预测出的潜在关系映射到类比问题实体上,最后,Induction步骤用来预测最终的类比答案实体。
的潜在关系,Mapping将预测出的潜在关系映射到类比问题实体上,最后,Induction步骤用来预测最终的类比答案实体。
3.2 多模态预训练模型
本文将每个实体和关系视为特殊token添加到预训练模型的词表中,并使用可学习的向量来进行表示。受之前的研究启发,本文设计了类似于掩码语言建模的掩码实体和关系建模任务来学习这些向量,使其包含实体和关系的信息。如图4(b)所示,首先在MarKG数据集上预训练多模态Transformer模型。MarKG数据集中包含了实体的文本描述信息、图片信息以及实体之间的关系信息,这里期望模型可以从这些多源信息中学习到实体和关系的表示。为此,本文设计了一个提示模板,以完形填空的形式让模型预测 [MASK] 对应的实体或关系。此外,本文还为模型提供了实体的不同模态信息,包括文本描述和图片等。
在预训练结束后,采用带有显示结构映射的提示学习类比推理技术,来将预训练Transformer模型应用到下游数据集MARS上。如图4(c)所示,输入分为两部分,||左边的部分对应于Pipeline方式中Abduction的步骤,||右边的部分对应于Induction步骤,而Mapping步骤在模型内部完成。
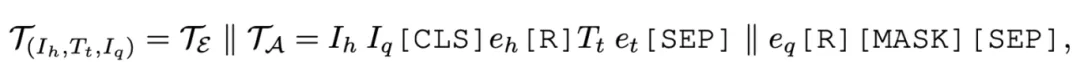
使用特殊token [R] 来代表类比示例实体之间的潜在关系,并将输入中包含的实体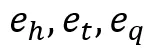 用预训练过程中学习到的实体embedding进行替代。最终,通过在特殊token词表空间中预测 [MASK] 对应的特殊token来得到类比答案实体。
用预训练过程中学习到的实体embedding进行替代。最终,通过在特殊token词表空间中预测 [MASK] 对应的特殊token来得到类比答案实体。
3.3 MarT框架
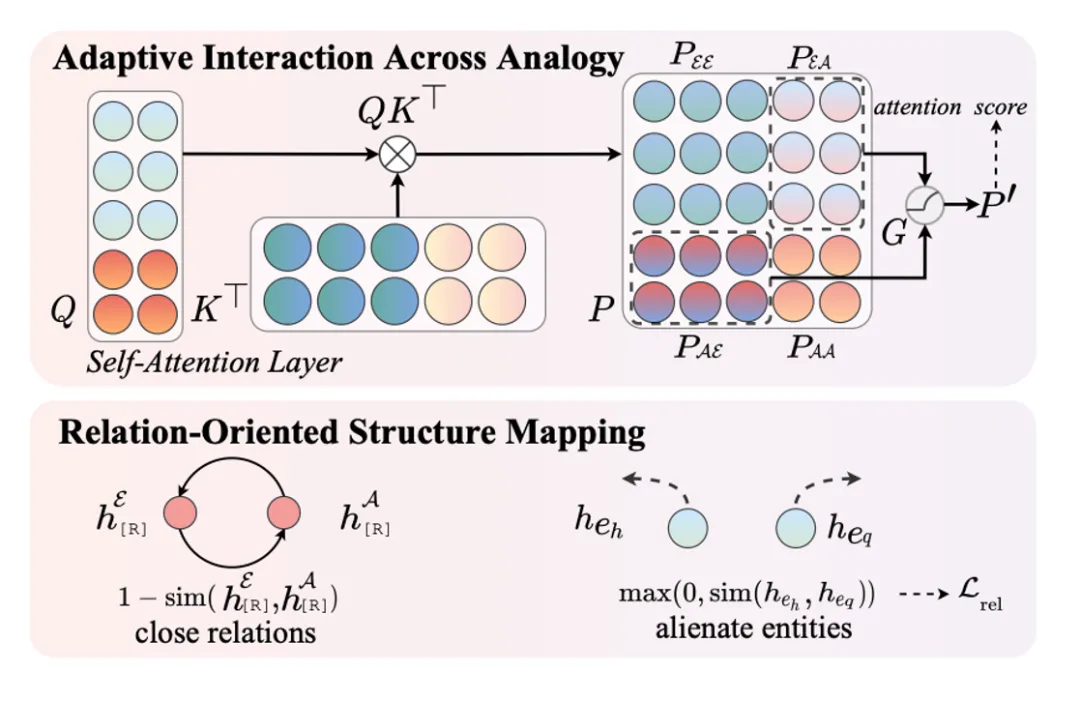
MarT框架
尽管上述方法可以使得预训练Transformer模型可以建模多模态类比推理任务,但只是浅层的考虑了Abduction和Induction步骤,忽略了类比示例与类比问题-答案对之间的细粒度关联。因此,本文进一步提出了用于Transformer模型的MarT框架,它包含了自适应类比交互和面向关系的结构映射等两个模块。
3.4 自适应类比交互
之前通过设计类比提示模板讲类比示例与类比问题-答案对拼接送入的Transformer模型,在Attention计算时两部分会进行一定程度交互。然而,类比示例对于类比答案的预测至关重要,但反过来类比问题-答案对对于类比示例的建模可能帮助甚微。此外,不同样例中类比示例提供的帮助不同。因此,本文使用自适应关联门来调节Attention计算中两部分的交互程度,将Attention计算拆解过程进行了拆解:

04
实验结果
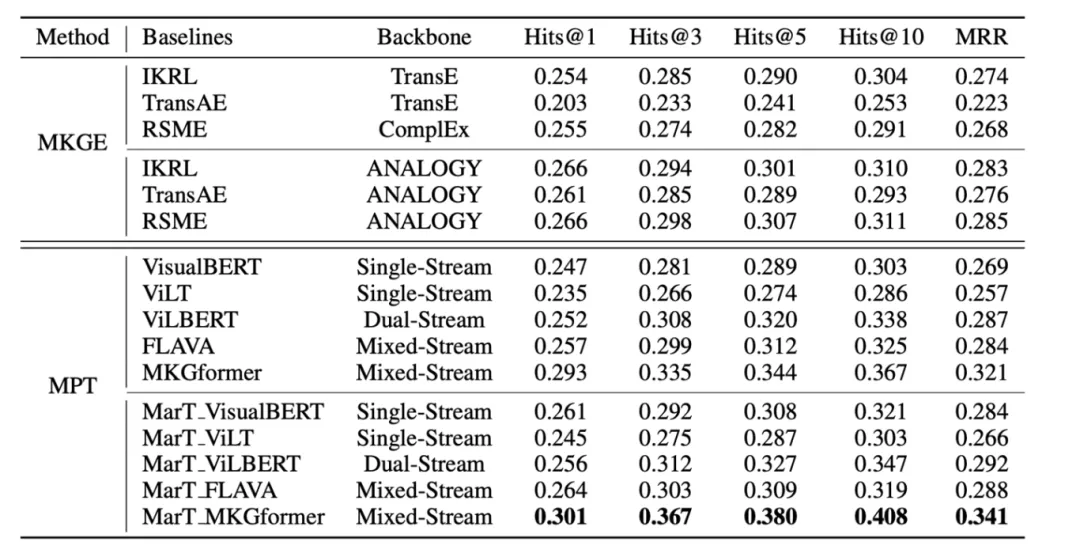
如下表所示,MKGE的方法和MPT的方法在MARS数据集上取得了可比的性能;在模型中加入类比模块后,性能都有了大幅的提升,具体表现为MKGE方法使用ANALOGY作为Backbone时Hit指标和MRR指标都有了明显提升,MPT方法加入了MarT框架后提升也十分显著;MarT_MKGformer表现出了最优越的性能,原因可能是MKGformer是针对多模态知识图谱任务设计的,对此类任务更为敏感。本文提供了一个排行榜https://zjunlp.github.io/project/MKG\_Analogy/ 。
05
总结与展望
在人类智能中,类比是一个很基本的能力,在某种程度上,可以认为是人类智能的源头之一。人们通过将一个概念或情境与另一个相似的概念或情境进行比较,来理解和解决问题。这种方法可以帮助人们通过熟悉的概念来理解抽象的概念,并使用自己在这些概念中获得的经验来解决问题。本文提出了基于知识图谱的多模态类比推理任务,对此任务进行了形式化的定义并提供了一个多模态类比推理数据集MARS和多模态知识图谱数据集MarKG。在多个知识图谱嵌入模型和预训练Transformer模型上的实验表明了这个任务的困难性和可挖掘性。
随着人工智能和深度学习技术的不断发展,昇思MindSpore作为一个高效、灵活且强大的框架,展现出广阔的应用前景。昇思MindSpore框架具有以下几个显著优势:高效的计算加速:与硬件深度整合,充分利用计算资源,显著提高了模型训练速度。自动混合精度:在训练过程中自动选择适当的数值精度,降低内存使用,提高计算效率。展望未来,昇思MindSpore生态系统有望不断扩展,涵盖更多行业应用。