AI数据框架大横评
AI数据框架大横评
前言
近年来,大型神经网络模型在人工智能领域引起了巨大的轰动和关注。这些大模型以其惊人的知识面和问答效果,迅速被应用于搜索引擎、客服等广泛领域,推动着AI时代提前到来。
为了取得更好的效果,大模型的规模也在不断扩大,从几百万到数十亿个参数的巨型模型如雨后春笋般涌现。所带来的最直接后果便是训练时间的指数倍增加。为了应对这个挑战,英伟达、华为等硬件厂商相继推出了自己的高端AI芯片,将算力推向了一个新的高度。但如何使能芯片算力,便取决于AI框架所提供的能力。
AI框架作为网络模型和设备芯片的中间层,起到一个承上启下的作用。能够将复杂的硬件操作,封装成抽象的高阶接口,供用户使用。这样一来,算法工程师可以更加关注设计网络模型结构本身,而无需关注硬件的运转。

AI框架涉及数据处理、计算图编译、算子、分布式并行等多种技术,本系列文章将只关注其中的数据框架部分,通过介绍并对比主流AI数据框架的架构,方便大家更好的理解其底层原理,发挥框架的全部能力。
架构设计
想要了解一款软件的能力和适用场景,从其架构设计可见一斑。偏高阶的实现能够支持动态变化,对用户更加易用;而偏底层的实现能够细粒度控制系统行为,性能更加高效。如何在易用性和性能之间抉择,是每一个AI框架都面临的挑战。
- MindSpore
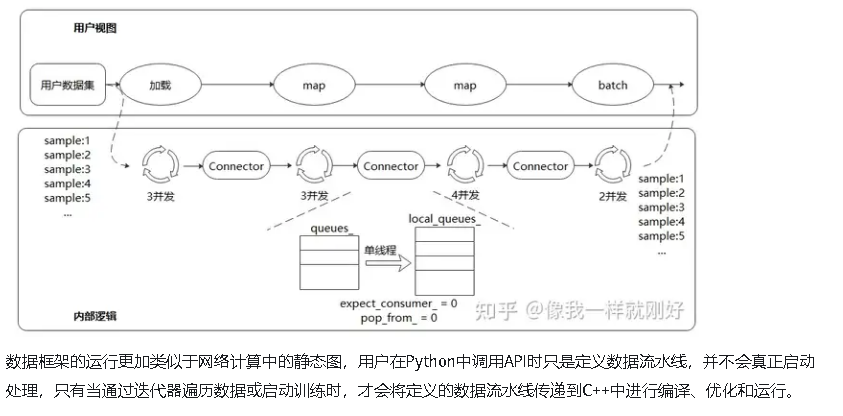
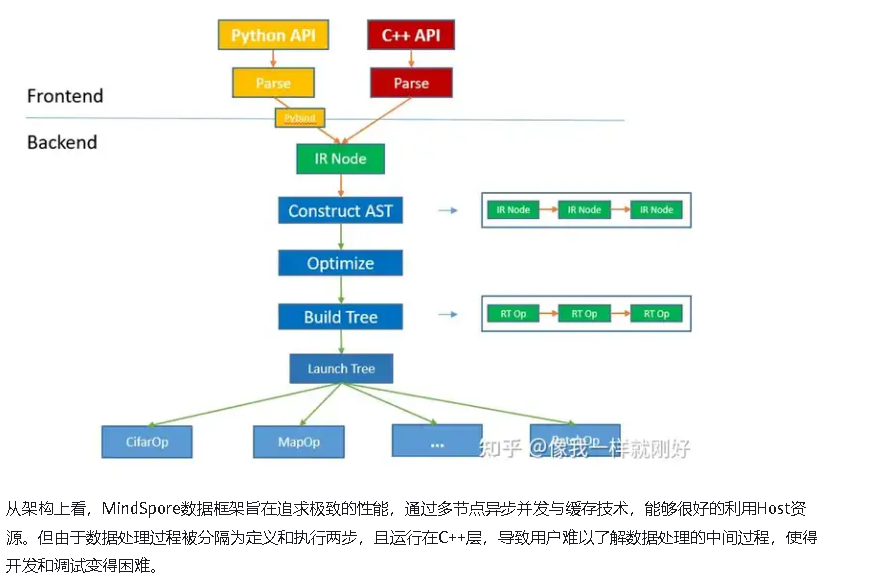
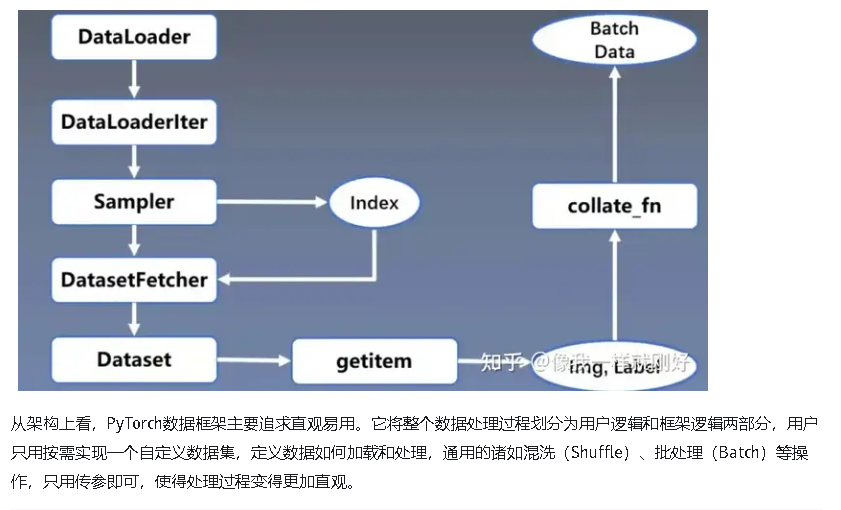
MindSpore的数据框架被设计为多节点异步并发的流水线。其中数据加载(Load)、混洗(Shuffle)、变换(Map)、批处理(Batch)被定义成流水线中的节点。数据从源节点产生,经过中间节点的处理,流向末节点,最后被发送到设备(GPU/Ascend)上参与网络运算。各节点彼此独立,异步并发运行,能够同时处理多条数据,节点之间通过缓存队列同步。
import osimport pandas as pdfrom torch.utils.data import DataLoaderfrom torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None,
target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
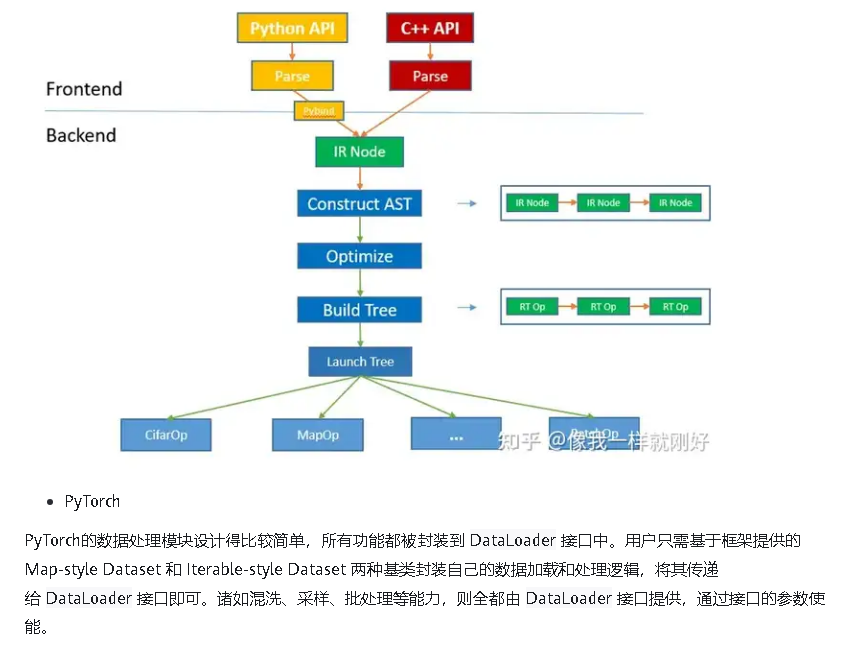
但相反,由于操作的过度封装,用户无法精细地调控整个处理过程,一旦需要添加某种框架不具备的能力,只能通过修改自定义逻辑来实现,使得自定义数据集代码往往庞大而臃肿。并且整个处理过程都同步执行,一旦处理逻辑比较复杂,性能将会很差,虽然可以通过DataLoader的多进程并发提高处理速度,但由于并行的粒度为整个处理流程,无法只调节某个节点,使得资源的消耗将会更大。
- TensorFlow
TensorFlow的数据框架也为多节点流水线结构,但与MindSpore略微有些不同。框架默认不提供缓存队列,而是得由用户通过tf.data.Dataset.prefetch在节点间添加;数据集接口不提供并发能力,需要配合tf.data.Dataset.interleave实现文件级并发加载。但也正是得益于这种静态设计,使得TensorFlow能够在流水线编译阶段实现操作融合优化、AutoTune自动调优等功能,使得处理性能遥遥领先。
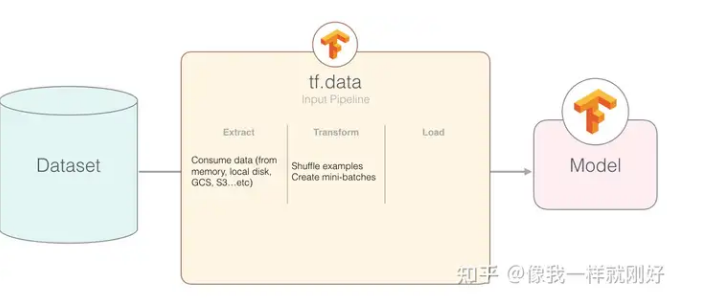
从架构上看,TensorFlow的数据框架延续了其框架整体的静态设计,追求极致的性能。在此基础上,为了提高框架整体的易用性,实现了调优能力的自动化,降低了用户学习门槛。但需要注意的是,与PyTorch截然相反,TensorFlow提供的用户自定义能力相对匮乏,常用的数据处理变换(Transforms)也不够完善,并且由于Python的GIL限制,自定义逻辑的执行效率也不高,所以不太适合用来实现过多自定义功能。
总结
本节主要对比了主流AI框架的整体架构设计,接下来的章节将更加细粒度的介绍如何使用它们来实现自己的数据处理逻辑。