MindSpore AI科学计算系列 | 昇思MindSpore复数分布式并行实现探究
MindSpore AI科学计算系列 | 昇思MindSpore复数分布式并行实现探究
**作者:**于璠 来源:知乎
背景
分布式训练是一种在人工智能领域中常用的方法,是将大型模型的训练过程分散到多个计算设备(如CPU、GPU 或华为 NPU)上,用于训练大规模的深度学习模型。随着数据量的增加,单个计算节点可能难以处理庞大的数据量,并且需要更快的训练速度,这导致分布式成为了训练大模型中至关重要的一环。
昇思MindSpore中的AI科学计算子模块MindScience ,正在众多科学领域中发挥着重要的应用。从API角度来看,在AI科学计算中,涉及到一些独特的Numpy或Scipy库中的算子,如线性代数、快速傅里叶变换、插值等相关算子,这些模块中的众多算子都会涉及到复数类型(Complex)的运用。从场景上来看,复数也是AI科学计算经常使用的类型,如在电磁学和量子力学中,复数用于表示波动和场的属性。但另一方面,在大多数传统的AI应用中,如图像识别、自然语言处理或声音识别等,输入数据(图像像素值,文本编码,声波振幅)都是只需实数就能进行表达的,这些应用不需要复数来表示数据,AI框架更倾向于满足更广泛应用的需求。因此,当前主流的神经网络结构和学习算法都是基于实数的,对于复数的优化不如实数进行的全面和高效,不能满足AI科学计算场景下对复数的需求。目前,业界对于复数的支持处于初步发展阶段。本文从分布式并行的角度探讨对于复数的支持的痛点问题,列举了三个解决方案并分析其可行性。
**1、**复数分布式实现痛点问题分析
在分布式训练中,关于复数目前业界存在着一些痛点。在并行的过程中,往往涉及到不同计算节点之间的数据的交流与聚合,而通信算子负责这一步骤的进行,在多个计算节点中同步模型的参数,并进行梯度的聚合。业界常见的通信库如NCCL(NVIDIA Collective Communications Library),HCCL(Huawei Collective Communication Library)目前均不支持复数,这是在支持复数算子的分布式特性过程中的主要痛点。
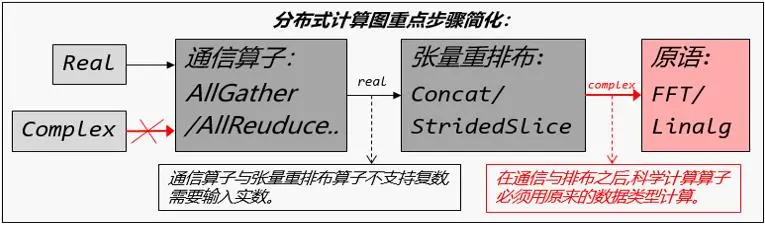
图1. 复数分布式流程简化示意图
1.1 通信算子
在进行分布式训练时,首要挑战是如何高效处理和协调众多计算节点上的数据和运算。分布式训练将大规模的数据集切分并分配到不同的计算节点上,这就涉及到对节点间的协作,通过同步和异步的运算来实现。同步要求所有节点在下一步计算之前必须等待其他节点完成当前的计算任务,保证每一步骤的一致性和数据的整合性,而这种方式可能会因为某些较慢的节点导致整体训练过程的延迟。
为了提高效率和缩短训练时间,分布式经常采用异步的方式进行,每个计算节点独立进行计算并更新参数。异步虽然可以显著加快训练过程,但也可能带来参数更新的不一致性,就需要设计同步机制确保全局一致性和训练的稳定性。通信算子是一系列专门设计的工具,用于在计算节点之间高效地传输数据和同步信息。无论是NCCL和HCCL,都包括一些常见的通信算子:
1)AllReduce: 将每卡中AllReduce算子的输入Tensor进行求和操作,最终每卡的AllReduce算子输出是相同的数值。

图2. AllReduce通信算子示例
2)AllGather: 将每张卡的输入Tensor的第零维度上进行拼接,最终每张卡输出是相同的数值。

图3. AllGather通信算子示例
3)ReduceScatter: 将每张卡的输入先进行求和,然后在第零维度按卡数切分,将数据分发到对应的卡上。
4)Broadcast: 将某张卡的输入广播到其他卡上,常见于参数的初始化。
在分布式过程中,通信算子是必要的。由于当前主流通信算子不支持复数数据类型,导致应用科学计算算子的上层模型可能无法进行模型并行,模型的大小和推理的效率都可能受到影响。
1.2 张量重排布
昇思MindSpore 在并行化策略搜索中引入了张量重排布技术(Tensor Redistribution,TR),这使输出张量的设备布局在输入到后续算子之前能够被转换。在用户给算子配置了切分策略后,以分布式算子为单位对张量进行切分建模。依据切分策略,分布式算子中定义了推导算子输入张量和输出张量的排布模型的方法。
分布式算子会进一步根据张量排布模型判断是否要在计算图中插入额外的计算、通信操作,以保证算子运算逻辑正确。在张量重排布的过程中,涉及到Tensor的切分和聚合,这主要涉及到StridedSlice,Concat算子,当然也涉及不同计算节点间的通信,这依赖AllGather通信算子解决。为了让昇思MindSpore的分布式过程支持复数,张量重排布所涉及到的算子对复数的支持也是需要考虑的问题。
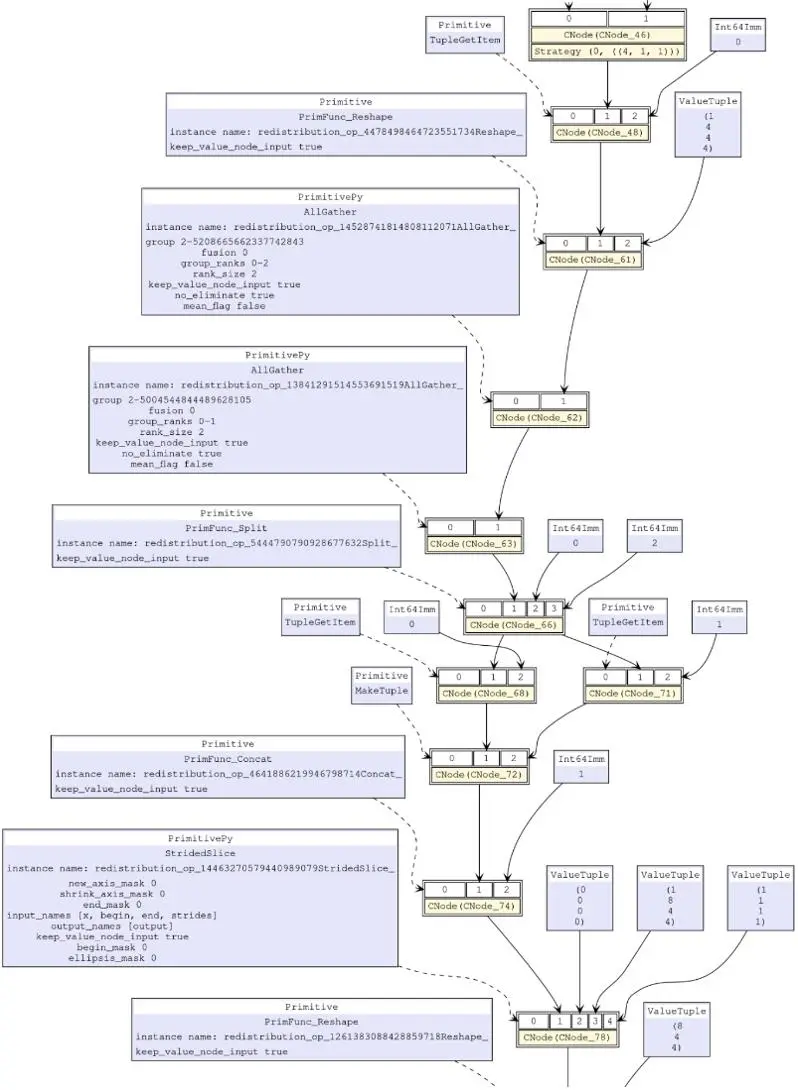
图4. 一次张量重排布加入的全部算子
2、可能的解决方案
2.1 在HCCL中添加支持
算子缺少支持类型,最直接的思路自然是使算子支持,也就是使通信算子和重排布算子本身添加复数类型的支持。这看似是最简单的方案,但是在已经构建好的框架中,为某个算子添加一种框架中未定义的类型支持,首先需要考虑框架本身对于该种类型的支持,就可能需要在整个框架的各处进行修改。如Nvidia通信库NCCL实际上也是不支持复数的。HCCL也无法支持复数,添加对复数的支持除了直观的工作之外至少还需要考虑以下问题:在通信库中添加类型支持是否是合适且合理的改动?添加复数的支持是否会影响对于已有实数的支持,给实数的场景带来额外开销?此外,对于张量重排布中涉及到的其他算子,是否也要进行算子级别的修改?在考虑复数类型支持的问题时,必须考虑到,复数属于个别应用场景,对于通常的AI训练情况下不具有普适性。
2.2 在AI框架调用通信算子时改变调用类型
首先必须明确,如果不打算使通信库直接支持复数,则框架侧对于复数的支持进行特判处理是不可避免的手段。作为参考,其他框架采用了在通信算子内部,进行实际操作之前使用一个名为view_as_real的函数将Complex64类型的张量转化为了Float32的张量。原本的复数张量的形状假如为[x,y,z],在转化后就会变成[x,y,z,2] ,也就是在张量末尾增加了大小为2的维度,同时数据类型的长度也发生了减半,占用的内存空间大小不变。之所以能如此操作,是由于Complex64的本身特性导致的:
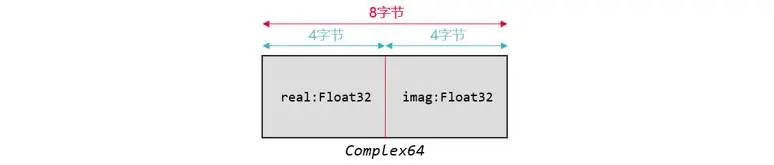
图5. Comple64内存占用示例
根据简单的数学知识,我们知道复数类型实际上是两个实数的复合,一个表示实部,一个表示虚部。对于Complex64这种数据,我们非常自然地使用两个Float32来分别表示它的实部与虚部,而在内存排布中,实际的效果就是每个虚数的实部与虚部相邻紧密排放,两个Float32的数据组成了一个长度为64的Complex。也就是说,一个Complex64的张量,其形状为[x,y,z] ,实际上可以看做是Float32类型且Shape为 [x,y,z,2] 的张量,其末尾升维的2正对应了一个Complex64到两个Float32的对应。由于实际上并没有发生转化,只是改变了“看待”张量的方式,该方案的转化函数名为view_as_real。
同时,通信算子和重排布算子实际上也有着一些特性,那就是大部分通信算子,如最常用的AllGather, 与其他算子如Broadcast, NeighborExchange, AlltoAll,还有所有的重排布算子都不进行数据的运算,只涉及数据的移动和拷贝。理论上此类算子只需要各计算节点上需要操作的起始数据地址,单位数据的长度(4字节、8字节或16字节数据),操作的单位数据个数(或者终止数据地址同理)就能完成计算,通信算子无需感知数据的具体类型,无论是将某64位数据看作Int64,还是Float64,或是Complex64都能完成相同的操作。

图6. 通信算子view_as_real转化逻辑
综合考虑后,该方案可以如下实施;在框架调用通信算子前进行检查,发现操作的张量类型是Complex64,就同步地修改张量的形状(升维,在末尾增加一个大小为2的维度)与类型(修改为Float32),将修改后的结果传入通信算子或张量重排布算子。此方案实施在昇思MindSpore上,需要具体考虑若干细节。比如昇思MindSpore中,张量的信息额外有相关的Info定义存储,由于我们不能干扰正常的其他调用,因此如何在修改时,只修改传入通信算子和重排布算子的内容,而不对张量本身的信息做修改?其次,张量的形状和类型信息在修改与传递时并不总是一体的,方案实施时必须保证形状和类型一定同时变化,否则就会造成严重问题。另外,该修改只是为了修改张量的信息,需要保证不对内存进行修改,否则会带来一部分的内存与时间开销。
我们也会考虑到,对于像AllReduce这类进行运算的通信算子,实际上调用的频率也相当之高,如何使其支持复数?如果是Sum求和操作,由于复数的相加逻辑就是实部与虚部分别相加,而Complex64转化为Float32后正好是实部与虚部交替存放,因此直接相加的结果正是一样的。但是对于更复杂的操作,比如最大/小值,或是乘积之类,则无从下手。在友商框架中,则是直接以不支持作结。如何支持AllReduce的更多种类操作,是一个更加复杂的问题。
该方案的优缺点是比较明显的:由于没有对内存进行任何的修改,所以在运行时不会给程序带来任何额外的开销。但是,该方案的稳定性以及可维护性也是不可忽视的问题。该方案实施的可行性需要小心考虑。
2.3 在处理流程中增加类型转换算子
方案3与方案2的思路基本相同,但具体实施细节区别较大。方案2中,我们传给通信算子或是排布算子的数据实际上,其标注的类型与本质数据的类型是不同的,这将带来一定的不确定性。但如果我们将转化的操作显示的表示出来,在通信算子前添加一个类型转化的算子,在通信结束后添加一个类型转回的算子,就可以使图上每一个算子的输入与上一个算子的输出正确的匹配。在昇思MindSpore中增加view_as_real和view_as_complex 算子,对计算图进行修改,插入view类节点,从而使张量重排布的整个流程使用Float32类型运算,在运算后交给科学计算算子的数据类型又转回Complex64。
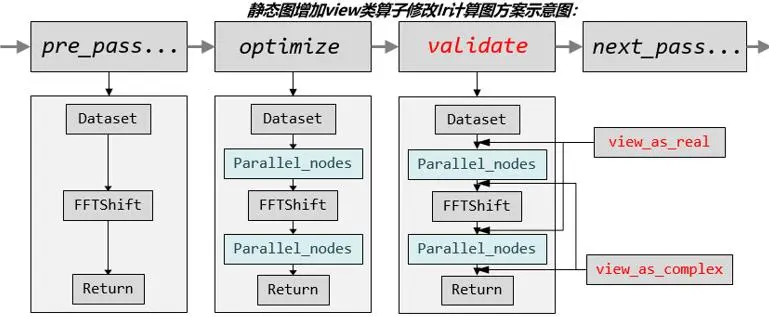
图7. 并行通信后修改ir图
由于昇思MindSpore的特性,在静态图时从后端C++侧进行计算图的整理与编译,导致该方案无法在python侧或用户侧进行实施,只能同步地后端C++侧进行修改,这引入了一些问题和挑战。在后端进行修改,需要层层追溯到昇思MindSpore框架后端中对于分布式进行通信算子和张量重排布的插入,保证前后计算图的连贯性和一直性,不影响其他原本的优化与加速,需要对框架的并行过程有具体到代码层面的深入了解,其难度不亚于重构。
同时,必须考虑view类算子对效率的影响。昇思MindSpore的张量重排布依情况可能调用的算子多而杂,存在多个通信算子与排布算子连环操作的情况,尽可能少地插入view类算子也是一个需要考虑的问题。该问题可以从两个角度进行考虑。如果能快速定位张量重排布的起始节点与结束节点,在起始之前与结束之后分别插入view类算子,就可以极大减少插入的数量,这样如何定位就成为了主要的挑战;或者改变思路,在进行节点融合时,当前后的节点不涉及计算时,就调整view类算子的位置,当view_as_real和_view_as_complex前后成对出现时就可以消去(相当于一对逆操作)。此时,就要注意如何进行算子的移动和调整,需要审慎对待。
目前,方案2与方案3都在开发中,预计近期,复数类算子的分布式功能就将在昇思MindSpore部署,供广大开发者使用。
**3、**总结归纳
当前科学计算算子如何支持分布式面临的主要挑战是对复数类型的支持。在科学计算领域,复数尤为突出和重要,在如线性代数、傅里叶变换等关键算子中扮演着重要角色。当前主流的通信库(如NCCL、HCCL)不支持复数数据类型,这对于使用科学计算算子支持分布式成为了关键的痛点。本文探讨了在昇思MindSpore+HCCL的环境中,通过直接在HCCL中添加复数支持,在AI框架调用通信算子时改变调用类型和处理流程中增加类型转换算子三种方式来支持科学计算算子的复数类型的分布式功能,为进一步支撑AI科学计算提供了思路和参考。
往期回顾