一天适配Gemma,MindNLP凭什么紧追开源SOTA?
一天适配Gemma,MindNLP凭什么紧追开源SOTA?
作者:吕昱峰 |来源:知乎
2月21日,谷歌毫无预兆地发布号称“全球性能最强大、轻量级”的新一代开源系列模型Gemma。Gemma模型使用了和Gemini同源的技术,总共有2B和7B参数规格,每个规格又分预训练和指令微调两个版本。

2月22日,在大家还在对谷歌发布的“深夜炸弹”转发评论时,昇思MindSpore社区官宣Gemma适配完成。此时,距离Gemma发布时间还不到24小时。
熟悉AI领域的同学都知道,现在主要的AI研发还是依托GPU+友商框架路线,国产框架和国产硬件对SOTA模型的快速适配,是大家是否会选择使用的核心痛点,能够紧追SOTA,才有机会弯道超车。
所以,回到正题,一天适配Gemma,昇思MindSpore凭什么紧追开源SOTA?
完备的昇思MindSpore动态图
昇思MindSpore框架开源伊始,为了深度适配昇腾硬件,以及对于AI框架发展路线的选择(彼时并没有人能预料到易用性能够爆杀一切性能优势),因此2020年开源到2023年MindSpore 2.0发布一直都没有对动态图过多重视,对于其定位也是“动态图调试后转静态图训练推理”。但是时代的车轮轧过去,静态图终究要成为历史。LLM的日新月异,又要不断追赶。所以,人生苦短,早用动态图。
回到主题,昇思MindSpore的动态图经过内部的几次演进,形成了一个几乎完备的方案,下面展开讲讲。
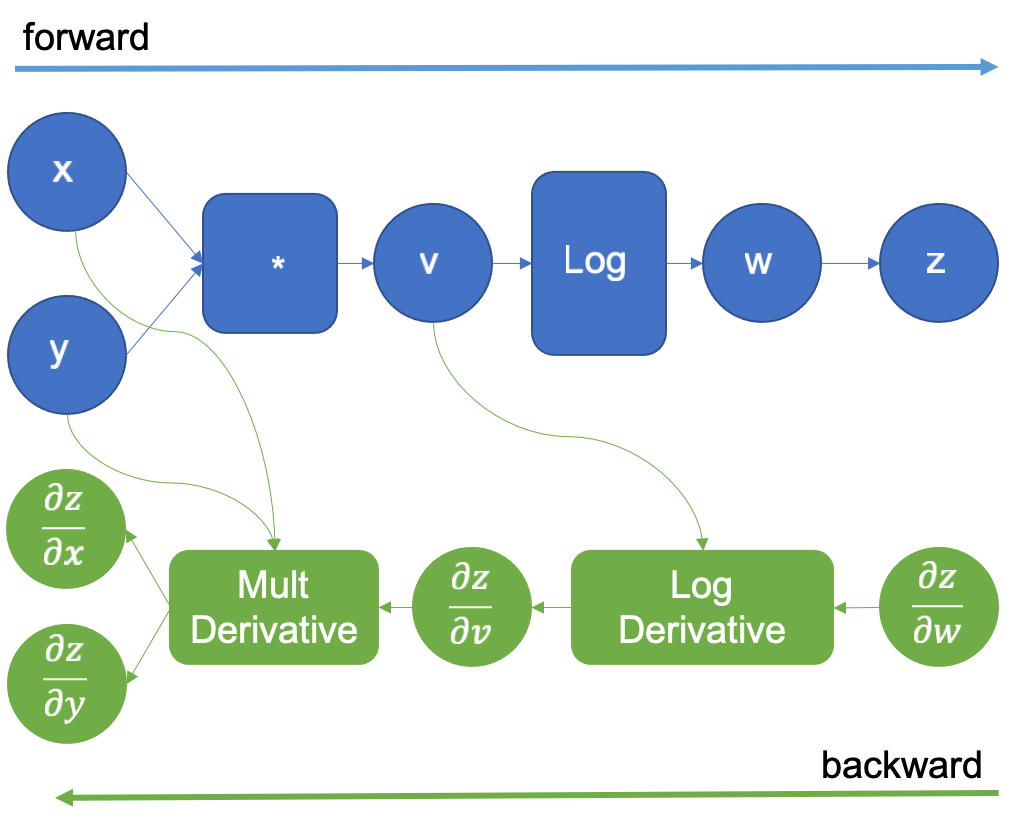
f(x, y) = log(x*y)的计算图
以一个简单的函数f(x, y) = log(x*y)为例,正向执行需要乘法(mul)和log两个算子(operator)完成,而反向过程则是通过链式法则求微分。
对于当下的深度学习框架使用者而言,绿色的反向传播部分均交由框架的自动微分(Autograd)功能完成,大家只需要关注正向逻辑,只要能够保证正向传播不断链即可(实际上诸多AI科研人员可能压根不care)。这给框架带来了几点要求:
- 没有语法限制(相对的静态图总有语法限制)
- 足够灵活,通常要使用各类Python库
- 性能尚可(没人要求极致性能)
这时候似乎静态图确实已经格格不入,而昇思MindSpore从静态图起家的技术栈是否需要完全摒弃也是一直有争议的话题(个人是动态图绝对拥趸)。事实上业界框架基本上都选择了完全转型动态图,但是任何一个大型系统的演进总会背着包袱,而包袱是负重还是补给便要考校研发人员的实力。
昇思MindSpore则选择了尽可能复用静态图原有能力,保留性能优势。
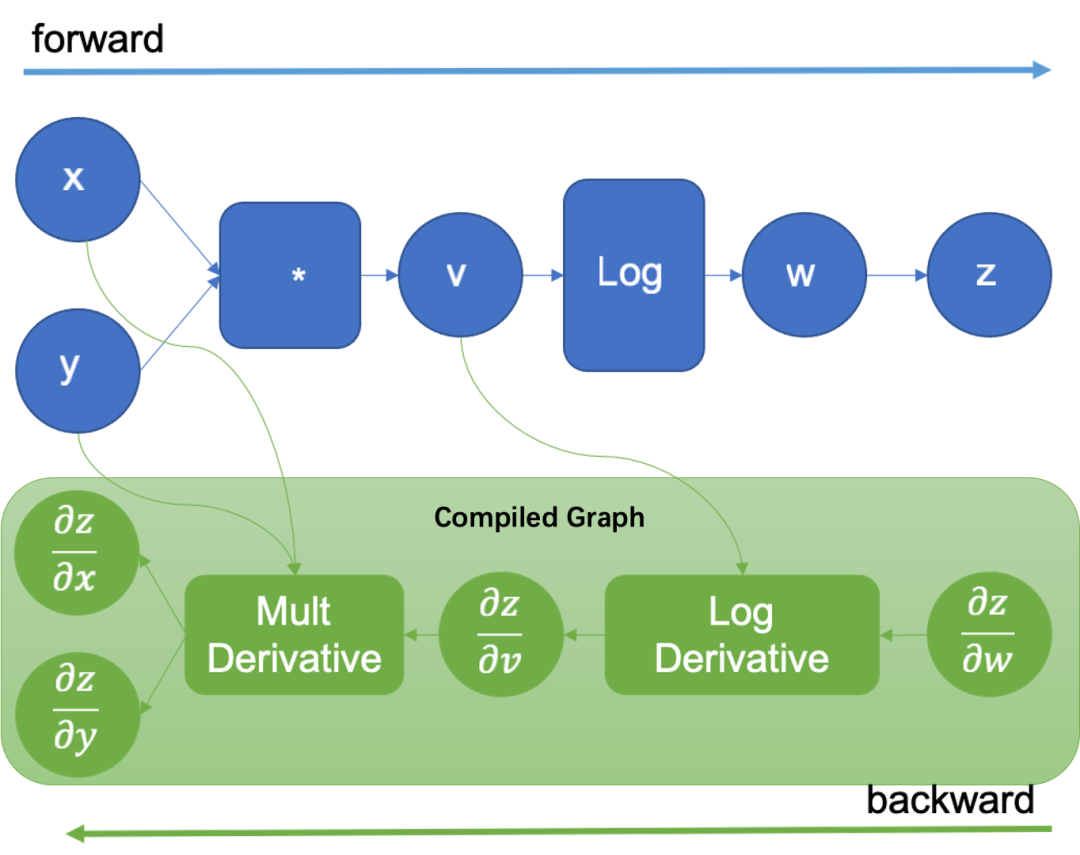
正向动态,反向成图示例图
从框架用户的角度出发,易用性和性能一直都是不能两全的trade-off,但是仔细分析可以发现,大家要的灵活性,全部都集中在蓝色部分,也就是正向执行,而反向传播由于不可见,可以选择不同的方案。因此,最终昇思MindSpore的动态图选择了——正向Eager执行,反向成图。这样带来的好处显而易见:
- 用户使用友好,调试方便
- 训练性能保持优势
即便是由于早期自动并行设计导致昇思MindSpore的算子粒度非常碎而导致kernel by kernel执行并不快的情况下,反向成图也能使正反向执行速度和PyTorch持平甚至更优。而另一方面,事实上PyTorch也在朝静态图演进,最终殊途同归,大家都走向了动静融合的路。
更易用的API接口
架构设计的合理是基础,接下来要做的,就是**“宠着用户”**了。既然开发者使用友商框架的习惯已经无法更改,那就加入。当然,这会引发诸如“真假自研”、“一模一样还用你干什么”之类的话题。又因为其他框架接口直接被使用,因此在接口设计上的取舍自是很难。
AI框架的接口一般由几部分构成,这里就和设计策略一起直接列出来:
- 网络构造接口,包括nn、ops,全面对齐友商框架;
- 自动微分接口:保持自研;
- 高阶封装Trainer:借鉴业界主流Trainer;
- Dataset:保持自研。
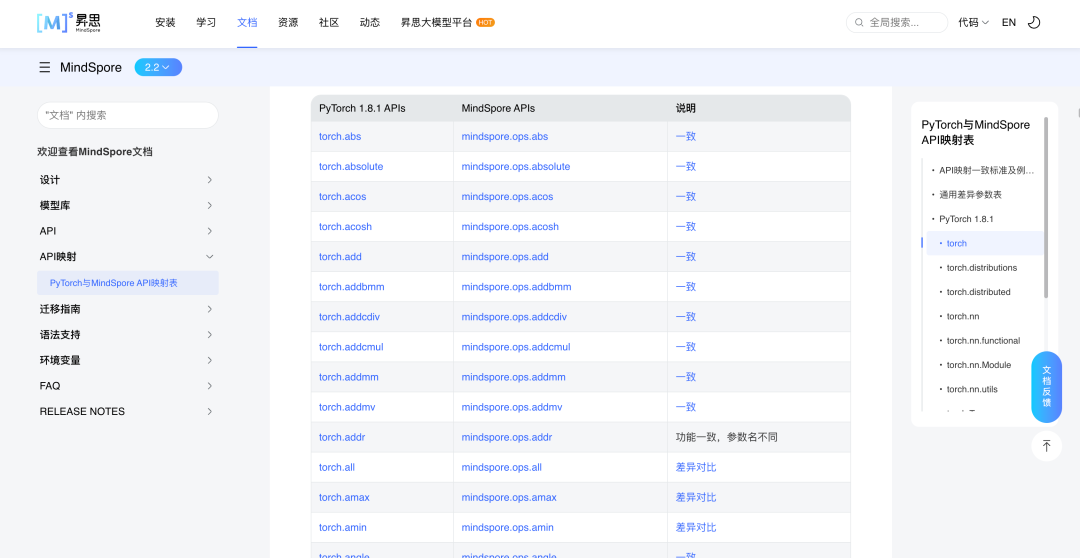
可以看到在技术核心仍旧选择了自研,而保证足够易用的API接口则要和友商框架全面对标。这里我留个链接和截图,可以看到昇思MindSpore和友商框架的接口映射情况。而这也是能够做到模型快速迁移的基础。(https://www.mindspore.cn/docs/zh-CN/r2.2/note/api\_mapping/pytorch\_api\_mapping.html)
全面拥抱Hugging Face的MindNLP套件
有了几乎对齐的API接口固然可以快速进行模型的迁移适配,但是如何保证正确性、使用体验的一致性都是能够决定是否有人愿意真的用你的关键因素。这里到了我的主场,就展开讲一下MindNLP的设计。
首先,我们选择全面拥抱Hugging Face。其实一度想要直接贡献给Hugging Face社区,但是由于某些客观原因(之前贡献给einops的PR最后也被close了)。但是我们不会放着最大的大模型社区而不去对接。所以策略是什么呢?
- All in 动态图
- 全面适配Hugging Face主要开发库,如Transformers、Peft、Trl等。
- 直接使用datasets库,配合MindSpore Dataset组件达成数据集的满足度。(这里附上上一篇文章https://zhuanlan.zhihu.com/p/659489670)
- 直接使用Hugging Face测试用例进行昇思MindSpore版本测试。
有了以上四条主要策略,可以和Hugging Face社区达成深度的绑定,借助社区的海量资源来促进MindNLP和昇思MindSpore的生态。也能够从易用性、数据、模型角度尽最大可能满足真正的需求。
当然,我们会有一些小trick,比如:
- 花了两天把checkpoint文件的直接加载搞定,再也不用先转换再加载了;
- 结合hf-mirror提供国内下载Hugging Face社区模型的能力,AutoModel一键加载
- 利用Arrow格式做memory map的数据加载
因为选择了动态图+拥抱Hugging Face社区的路线,我们几十个高校的同学一起已经搞定了60+模型的快速迁移适配,最快单个模型1小时通关(Pass Hugging Face所有ut)。
社区贡献者
总结
动态图的适应是真的舒适,但是只有动态图可能永远只能做小弟,这时候,自上而下的设计,还是要全面为真正的用户着想。
最后关于MindNLP,需要用的功能尽管提issue,顺带star一下也可。(https://github.com/mindspore-lab/mindnlp)
此外,我们还在持续号召社区贡献,参与大模型任务赢大奖,海量任务等你来!(https://gitee.com/mindspore/community/issues/I835ND?from=project-issue)