MindSpore AI科学计算系列 | 三维形状表征
MindSpore AI科学计算系列 | 三维形状表征
**作者:**于璠 来源:知乎
背景
近年来,AI在二维图像的识别、分割、生成等任务中取得了丰硕的成果,然而,对于我们生活的三维世界,三维形状则更为普遍,因此,在Midjourney等图像生成活跃发展的今天,有必要考虑三维形状的表征和生成,本文将对三维形状的表示做一个简单的调研。
我们该如何高效、精确的表达一个三维物体?以下图的Stanford Bunny为例:

图1. Stanford Bunny
一个很朴素的想法,就是参考二维的图像中像素点的概念,将三维外形表示为一个个三维像素,这样在三维空间中,就可以像二维图像一样,采用卷积来处理,但是缺点也很明显,这种表达的效率非常低,我们主要关注的是物体表面,但是我们需要同时处理物体的内部和外部的信息,这些信息是大量冗余的,尤其是我们需要对物体进行非常精细化描述的时候,网格会打得很细,导致占据的存储空间大大增加。

图2. 三位像素点表示的Stanford Bunny
那么换一种想法,我们也可以用“拍照片”的方式描述一个三维形状,这样图像的处理方法、数据集就可以直接应用了,当然这种方式的缺点也很明显,照片拍摄的“死角”是很难避免的,导致信息的丢失。
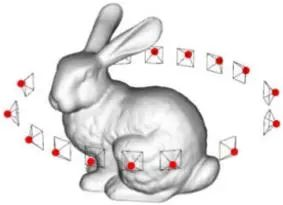
图3. “拍照片”方式下的Stanford Bunny
更进一步,我们用网格的方式也可以表达一个三维形状,在表面通过记录节点坐标和节点间的连接信息,形成一个表形的结构。这种表达方式无疑是十分高效的,在相对平缓的平面上,我们可以少布一些点,在外形变化剧烈的地方,可以多放一些,因此,这种方式在计算图像学里应用十分广泛,在工程上的CAE分析中,也常用于表征固体的变形、流体的表面压力分布等等。在AI领域中,网格的数据结构也与图的概念相符,因此GNN,MeshCNN等方法可以进行针对性的处理。
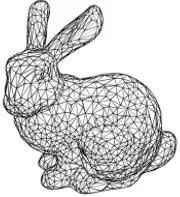
图4. 网格表示方式下的Stanford Bunny
三维网格需要同时记录网格点的坐标和连接信息,由于连接信息常常十分复杂,那么能不能只保留表面点的坐标呢?那就是点云了,点云是物体表面无序点的集合,可以同时表示物体局部和整体的形状信息,另外,点云的数据非常容易获取,可以通过扫描、采样等方式直接得到。当前已经有PointNet、PointNet++、PointTransformer等模型用于点云的分类、分割等任务。

图5. 点云表示下的Stanford Bunny
最后,将神经压缩的想法应用在三维外形上,可以形成三维形状的隐式表达。以NeRF的方式为例,神经网络的输入为观测的位置和角度,输出则为该视角上的RGB和体密度值(原文的解释为光线在改点终止的概率),这样我们只需要保证每个视角下的照片和NeRF的渲染结果相一致,那么就可以对三维外形进行全面描述。对于每一个三维外形,我们都可以训一个NeRF,这样NeRF的参数就可以作为一个三维外形的隐式表征。由于其与观察视角的相符性,因此NeRF的渲染结果可以在手机/网页浏览器/VR/AR上自由操作,然而,NeRF的对于训练资源的需求较高,训练耗时长,尤其是复杂光照等条件中。
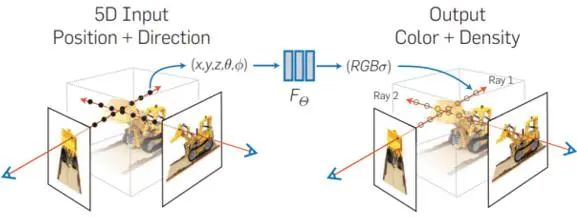
图6. NeRF(Neural Radiance Fields)
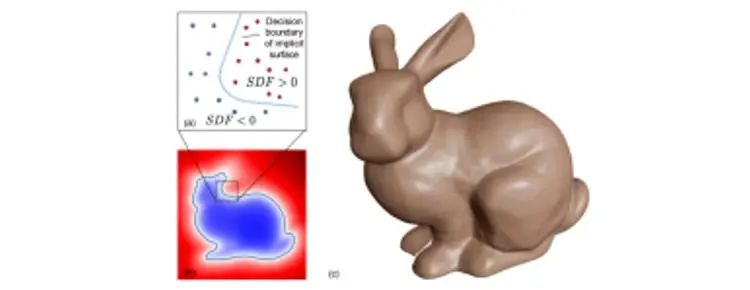
图7. NeRF表示下的Stanford Bunny
最后分享两个常用的三维外形数据集:
ModelNet40[1]**:**ModelNet40数据集包含合成对象点云。作为使用最广泛的点云分析基准,ModelNet40因其类别丰富、形状清晰、数据集构造良好等特点而广受欢迎。最初的ModelNet40由cad生成的40个类别(如飞机、汽车、工厂、灯具)的12,311个网格组成,其中9,843个用于训练,其余2,468个用于测试。从网格表面均匀采样相应的点云数据点,然后移动到原点进行了归一化处理。
ShapeNet[2]**:**ShapeNet是由斯坦福大学、普林斯顿大学和美国芝加哥丰田技术研究所的研究人员开发的大型3D CAD模型存储库。该存储库包含超过300万个模型,其中22万个模型被分类为3135个类,使用WordNet上下名关系排列。ShapeNet Parts子集包含31,693个网格,分为16个常见对象类(如桌子、椅子、平面等)。每个形状的基础真理包含2-5个部分(总共50个部分类)。
参考文献
[1] https://modelnet.cs.princeton.edu
往期回顾