论文精讲 | 基于昇思MindSpore的加速对抗训练算法,可显著减少训练时间
论文精讲 | 基于昇思MindSpore的加速对抗训练算法,可显著减少训练时间
**作者:**李锐锋 |来源:知乎
论文标题
Accelerate adversarial training with loss guided propagation for robust image classification
论文来源
Information Processing & Management
论文链接
https://www.sciencedirect.com/science/article/pii/S0306457322002448
代码链接
https://gitee.com/chunjie-zhang/atlgp
昇思MindSpore作为开源的AI框架,为产学研和开发人员带来端边云全场景协同、极简开发、极致性能、安全可信的体验,支持超大规模AI预训练,自2020年3月28日开源以来已超过657W+的下载量。昇思MindSpore已支持上千篇AI顶会论文,走入290+所高校进行教学,通过HMS在5000+App上商用,拥有数量众多的开发者,在AI计算中心、智能制造、金融、云、无线、数通、能源、消费者1+8+N、智能汽车等端边云车全场景广泛应用,是Gitee指数最高的开源软件。欢迎大家参与开源贡献、套件、模型众智、行业创新与应用、算法创新、学术合作、AI书籍合作等,贡献您在云侧、端侧、边侧以及安全领域的应用案例。
在科技界、学术界和工业界对昇思MindSpore的广泛支持下,基于昇思MindSpore的AI论文2023年在所有AI框架中占比7%,连续两年进入全球第二,感谢CAAI和各位高校老师支持,我们一起继续努力做好AI科研创新。昇思MindSpore社区支持顶级会议论文研究,持续构建原创AI成果。我会不定期挑选一些优秀的论文来推送和解读,希望更多的产学研专家跟昇思MindSpore合作,一起推动原创AI研究,昇思MindSpore社区会持续支撑好AI创新和AI应用,本文是昇思MindSpore AI顶会论文系列第30篇,我选择了来自北京交通大学计算机与信息技术学院的张淳杰老师团队发表于信息处理与管理领域国际顶级期刊Information Processing & Management的一篇论文解读,感谢各位专家教授同学的投稿,更多精彩的论文精读文章和开源代码实现请扫下方二维码访问Models。

01
研究背景
深度学习模型在计算机视觉领域取得了良好的性能,但许多研究表明,深度学习模型在数字世界和物理世界都容易受到对抗样本的攻击,威胁了深度学习模型规模化应用的安全性。对抗训练作为最有效的防御方法之一,显著提升了深度学习模型在对抗环境中的性能。然而,由于生成对抗样本作为训练数据需要大量的计算资源,现有的对抗训练算法面临着计算效率较低的问题。
02
团队介绍
论文第一作者徐昌凯是北京交通大学计算机与信息技术学院23届硕士毕业生,研究方向为对抗攻击算法等。
北京交通大学数字媒体信息处理研究中心(Mepro)肇始于1998年,2012年入选教育部“创新团队发展计划”。该中心现有教师14人,博、硕士研究生100余人。该中心的研究领域为数字媒体信息处理,研究方向主要包括图像、视频编码与传输、数字水印与数字取证、媒体内容分析与理解等。2022年,实验室共发表高水平论文共61篇,其中包括本领域国际顶级汇刊IEEE Trans论文38篇,国际顶级会议如NeurIPS、CVPR、ECCV、ACM MM等论文23篇。
03
论文简介
对抗训练的总体思路是在训练数据中引入对抗样本,从而提升深度学习模型在对抗攻击下的性能表现,是最有效的主动防御方法之一。然而,现有对抗训练算法在生成对抗样本的过程中需要大量的计算资源,导致模型训练效率较差。为了缓解这一问题,本文提出了损失函数引导传播的加速对抗训练算法。
本算法在生成对抗样本的过程中,利用损失函数作为引导,自动地控制每一个训练实例在不同训练阶段的梯度传播次数,在保证模型性能的前提下,有效地减少了计算量。同时,本算法具有良好的可拓展性,可以与已有的加速对抗训练算法结合,在对模型性能要求较高的情况下实现了领先的加速效果。在三个公开数据集上的实验结果表明,本算法与其他基准算法相比,可以减少30%到60%的训练时间。
04
实验结果
本文在MNIST、CIFAR10和CIFAR100三个公开数据集上进行了实验,对比分析了损失函数引导传播的加速对抗训练算法(ATLGP)和不同基准算法的性能及训练效率。本文给出了在多种超参数设置下AT、ATTA与ATLGP的实验结果,更加全面的展示了这三种方法在性能与训练时间上的关系。
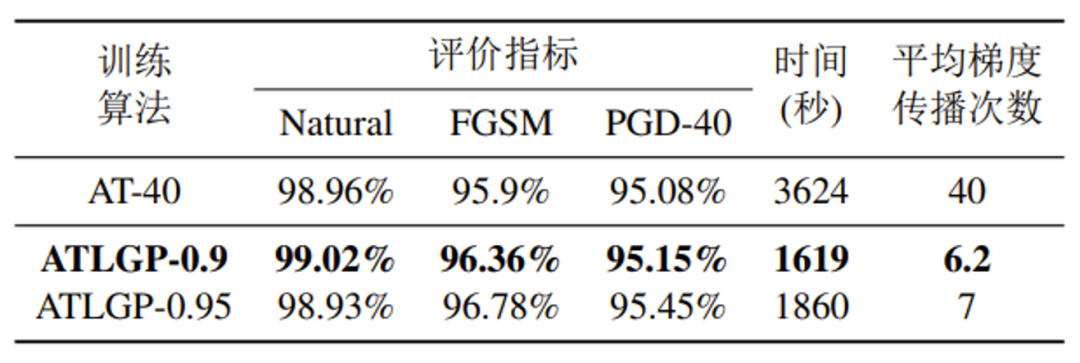
表 1 AT与ATLGP在MNIST上的性能对比
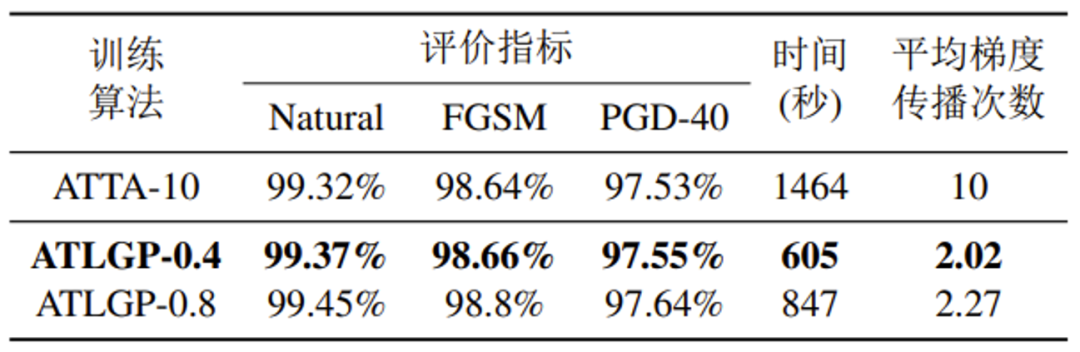
表 2 ATTA与ATLGP在MNIST上的性能对比
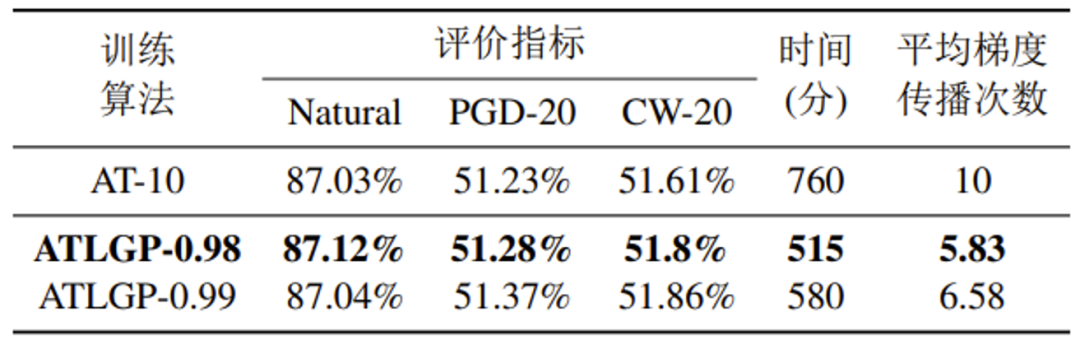
表 3 AT与ATLGP在CIFAR10上的性能对比
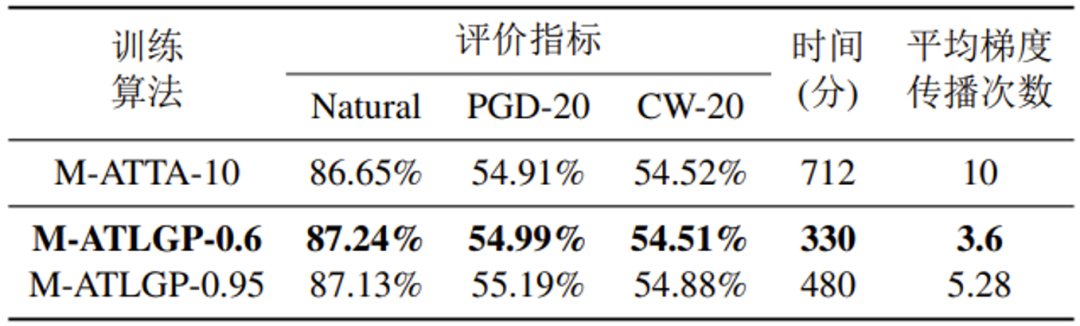
表 4 M-ATTA与M-ATLGP在CIFAR10上的性能对比
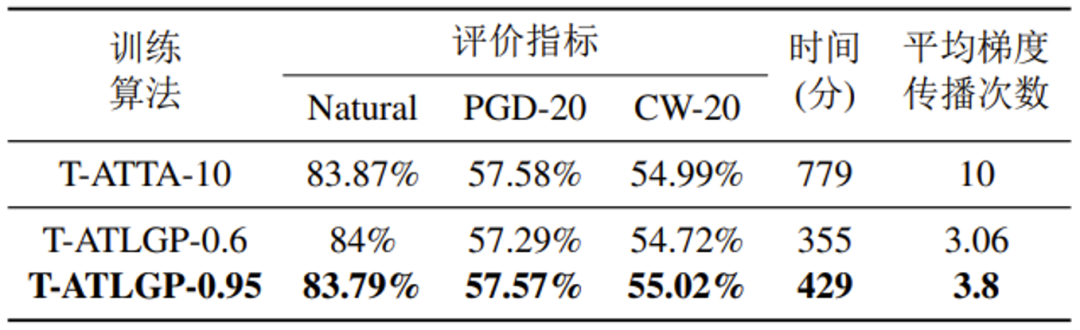
表 5 T-ATTA与T-ATLGP在CIFAR10上的性能对比
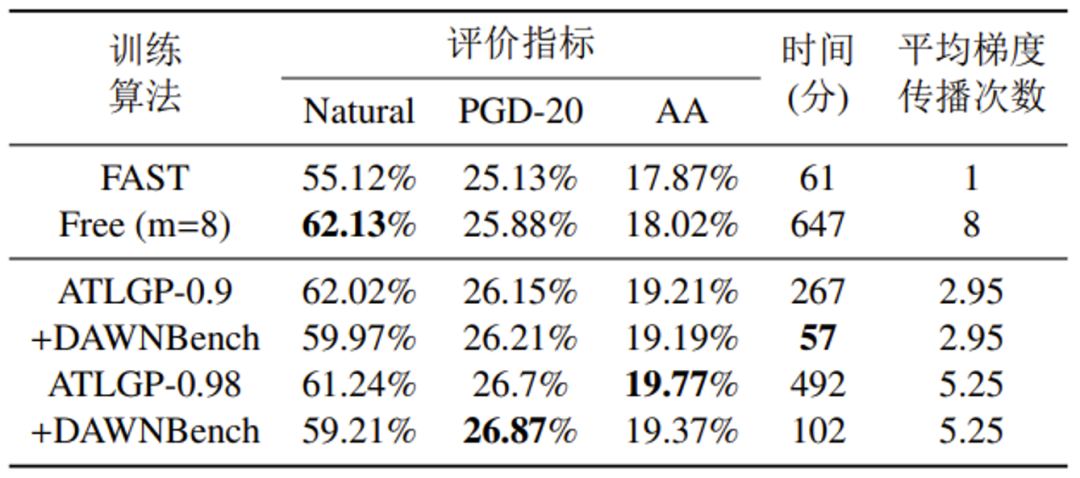
表 6 ATLGP和其他基准算法在CIFAR100上的性能对比
05
总结与展望
本文提出了损失函数引导传播的加速对抗训练算法ATLGP,在三个公开数据集上的实验证明了其具有较高的对抗准确率和良好的加速效果。ATLGP的加速性能进一步证明了损失函数引导的合理性。此外,ATLGP还具有良好的泛化性,可以很容易地与ATTA结合,在更高的对抗准确率下具有非常先进的加速性能。ATLGP充分地考虑了每个训练实例间存在的“对抗差异性”,并引入了阈值β来定量地描述了内层最大化问题的局部最优解。“对抗差异性”可能广泛存在于不同的数据集中,数据分布越复杂,对抗差异性越明显,如从MNIST到ImageNet。基于此本文推测,ATLGP在更复杂的数据集上也会有良好的加速表现。
往期回顾