论文精讲 | 基于昇思MindSpore的动作频率自适应视频时序动作提名生成研究,解决精确定位未修剪视频中的动作问题
论文精讲 | 基于昇思MindSpore的动作频率自适应视频时序动作提名生成研究,解决精确定位未修剪视频中的动作问题
**作者:**李锐锋 |来源:知乎
论文标题
Temporal Action Proposal Generation With Action Frequency Adaptive Network
论文来源
TMM 2023
论文链接
https://ieeexplore.ieee.org/abstract/document/10183357
代码链接
https://gitee.com/chunjie-zhang/afan-tmm2023
昇思MindSpore作为开源的AI框架,为产学研和开发人员带来端边云全场景协同、极简开发、极致性能、安全可信的体验,支持超大规模AI预训练,自2020年3月28日开源来已超过6百万的下载量。昇思MindSpore已支持数百篇AI顶会论文,走入Top100+高校教学,通过HMS在5000+App上商用,拥有数量众多的开发者,在AI计算中心、智能制造、金融、云、无线、数通、能源、消费者1+8+N、智能汽车等端边云车全场景广泛应用,是Gitee指数最高的开源软件。欢迎大家参与开源贡献、套件、模型众智、行业创新与应用、算法创新、学术合作、AI书籍合作等,贡献您在云侧、端侧、边侧以及安全领域的应用案例。
在科技界、学术界和工业界对昇思MindSpore的广泛支持下,基于昇思MindSpore的AI论文2023年在所有AI框架中占比7%,连续两年进入全球第二,感谢CAAI和各位高校老师支持,我们一起继续努力做好AI科研创新。昇思MindSpore社区支持顶级会议论文研究,持续构建原创AI成果。我会不定期挑选一些优秀的论文来推送和解读,希望更多的产学研专家跟昇思MindSpore合作,一起推动原创AI研究,昇思MindSpore社区会持续支撑好AI创新和AI应用,我选择了来自北京交通大学计算机与信息技术学院的张淳杰老师团队的一篇论文解读,感谢各位专家教授同学的投稿。
01
研究背景
作为视频理解领域中的核心内容,视频时序动作提名生成任务旨在准确预测未修剪视频中人体动作实例的起始和结束时间,对于理解视频中的人类行为起到至关重要的作用。尽管近年来时序动作提名生成的性能有了显著提升,但大多数先前的研究忽略了原始视频中动作频率的变化,导致这些方法在处理高动作频率视频时性能不尽如人意。通过详细的数据分析,我们确定了两个主要问题:首先,高动作频率视频和低动作频率视频之间存在数据不平衡;其次,在高动作频率视频中,短时动作片段的检测性能相对较差。为了应对这些挑战,我们提出了一种灵活适应不同动作频率的有效框架,它可以无缝嵌入到现有的时序动作提名生成方法中,显著提高其性能。我们的算法可以基于昇思MindSpore官方文档示例以及我们提供的代码实现。
随着视频监控、手机等摄像设备的迅速发展,视频数据量迅速增加。人工处理如此庞大的视频数据几乎是不可能。如何使用智能视频理解算法来有效地收集、管理和利用这些视频数据,成为了研究热点。近年来,人体动作识别取得了显著进展,但它主要关注短时修剪的视频片段,难以应用于长时间未修剪的真实视频。因此,关注未修剪长视频的时序动作检测引起了广泛的关注。
该任务首先需要准确定位未修剪的长视频中人体动作实例的起始和结束时间,然后对这些动作进行分类。现有方法通常将这个任务分为两个子任务:时间动作提议生成(TAPG)任务和动作分类任务。TAPG的目标是预测未修剪视频中人体动作实例的起始和结束时间,而分类任务则是对这些动作实例进行分类。尽管在动作分类方面取得了显著的进展,但由于TAPG的召回率不足,时序动作检测的性能仍然有待改进。因此,如何精确定位未修剪视频中的动作是亟需解决的问题。未修剪视频的持续时间各不相同,同时其中的动作实例的持续时间也变化多样,这给时间动作提议生成带来了巨大的挑战。
大多数TAPG模型主要关注预测时间动作实例的边界或动作锚定框的置信度分数,或者两者兼顾。然而,在这个过程中,大多数方法都忽视了未修剪视频中动作频率的变化,而在真实世界中这种情况是十分常见的。因此,研究如何适应不同的动作频率视频并提高在高动作频率视频上的性能变得至关重要。
02
团队介绍
论文第一作者唐业鹏是北京交通大学计算机与信息技术学院23届博士,研究方向为计算机视觉、视频理解、时序动作定位等。
北京交通大学数字媒体信息处理研究中心(Mepro )肇始于1998年,2012年入选教育部“创新团队发展计划”。该中心现有教师14人,博、硕士研究生100余人。该中心的研究领域为数字媒体信息处理,研究方向主要包括图像\视频编码与传输、数字水印与数字取证、媒体内容分析与理解等。2022 年,实验室共发表高水平论文共 61 篇,其中包括本领域国际顶级汇刊 IEEE Trans.论文 38 篇,国际顶级会议如 NeurIPS、CVPR、ECCV、ACM MM 等论文 23 篇。
03
论文简介
本文介绍了一项关于视频时序动作提名生成技术的研究。该技术在视频分析、智能监控分析等领域扮演着至关重要的角色,其目标是从未剪辑的长视频中对人类的行为进行定位。未修剪视频的持续时间各不相同,其包含的动作实例持续时间也不同,这给时序动作提名生成任务带来了巨大挑战。
大多数时序动作提名生成模型主要关注预测时间动作实例的边界或动作锚定框的置信度分数,或者两者兼顾。然而,这些方法都忽视了未修剪视频中动作频率的变化问题。通过数据分析,我们总结了两个主要问题:
1.数据不平衡导致高动作频率视频性能不佳。模型往往在低动作频率视频上表现良好,而无法很好处理高动作频率视频。
2.大量短时动作限制了在高动作频率视频上的性能。在高动作频率视频中有比低动作频率视频更多的短时动作实例。定位这些短时动作实例很困难,类似于目标检测中的小物体。
为解决上述问题,我们提出了一个动作频率自适应的时序动作提名生成框架。一方面,我们通过专家学习方式来减轻数据不平衡。具体来说,我们将整个视频数据集分成几个子集,每个子集具有较少不平衡的数据分布。通过这种方式,我们可以确保在这些子集上训练的专家模型在数据不平衡方面受到的影响较小。为了整合来自专家模型的知识,我们随后通过知识蒸馏训练一个统一的学生模型,该模型适应不同动作频率的视频。
同时,我们设计了一个动作频率分类器来辨别高动作频率视频,再对其进行精细检测,提高短时动作的预测性能。我们的方法可以方便地应用在现有时间动作提议生成模型之上。我们在两个经典模型(BMN和DBG)上验证所提出的方法,并在四个基准数据集进行了性能评估。充分的实验结果证明了我们方法的有效性和通用性。
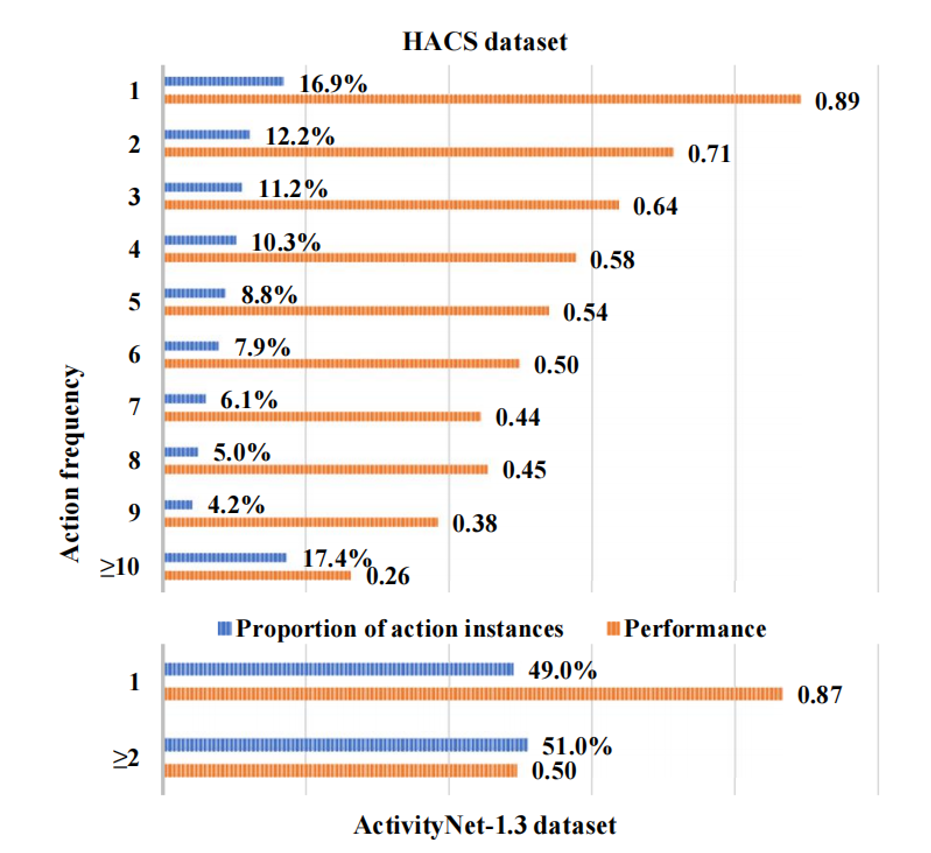
现有模型在不同动作频率视频的性能对比
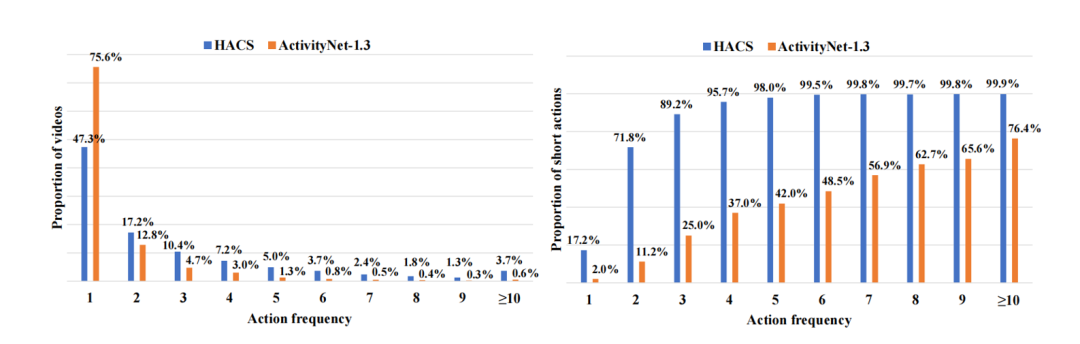
现有数据集的不同动作频率视频的分布
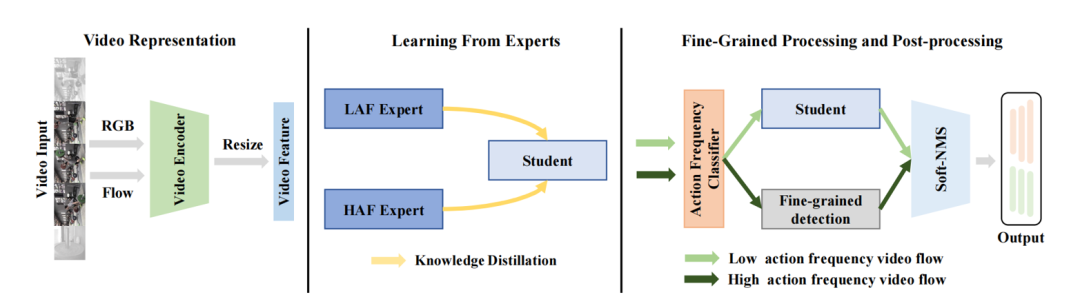
框架图
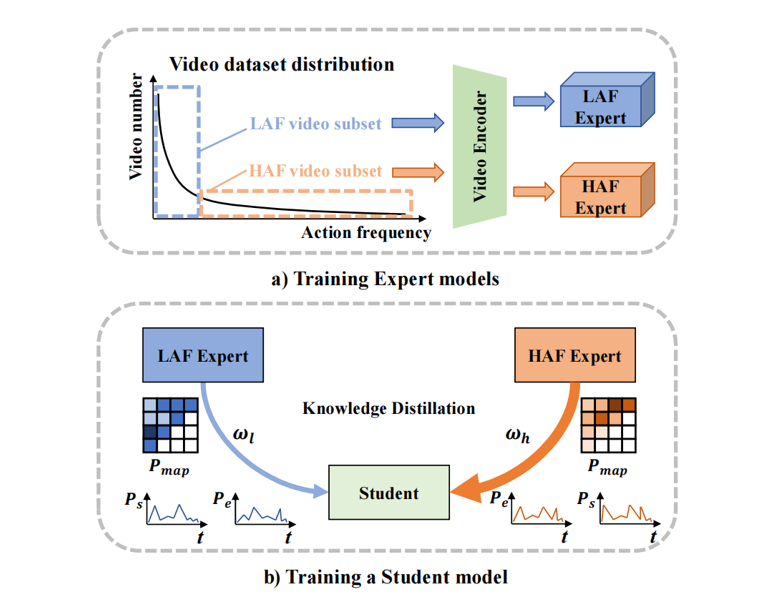 专家学习模块
专家学习模块
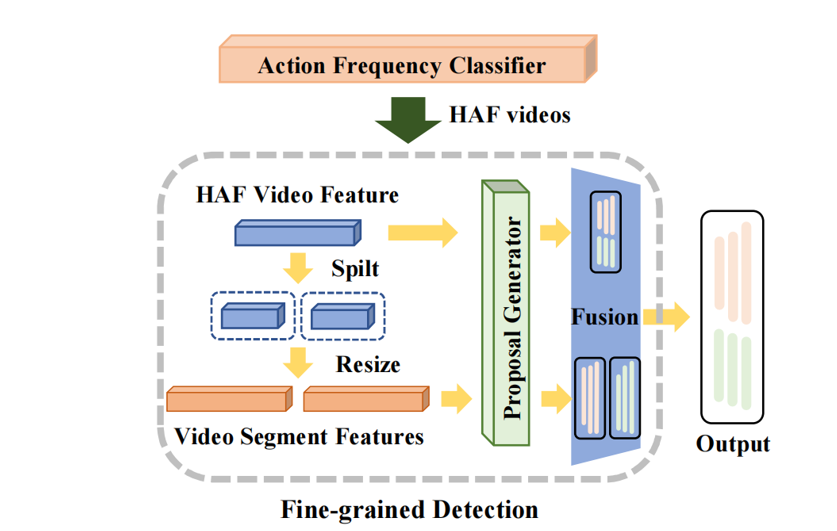
精细化处理模块
04
实验结果
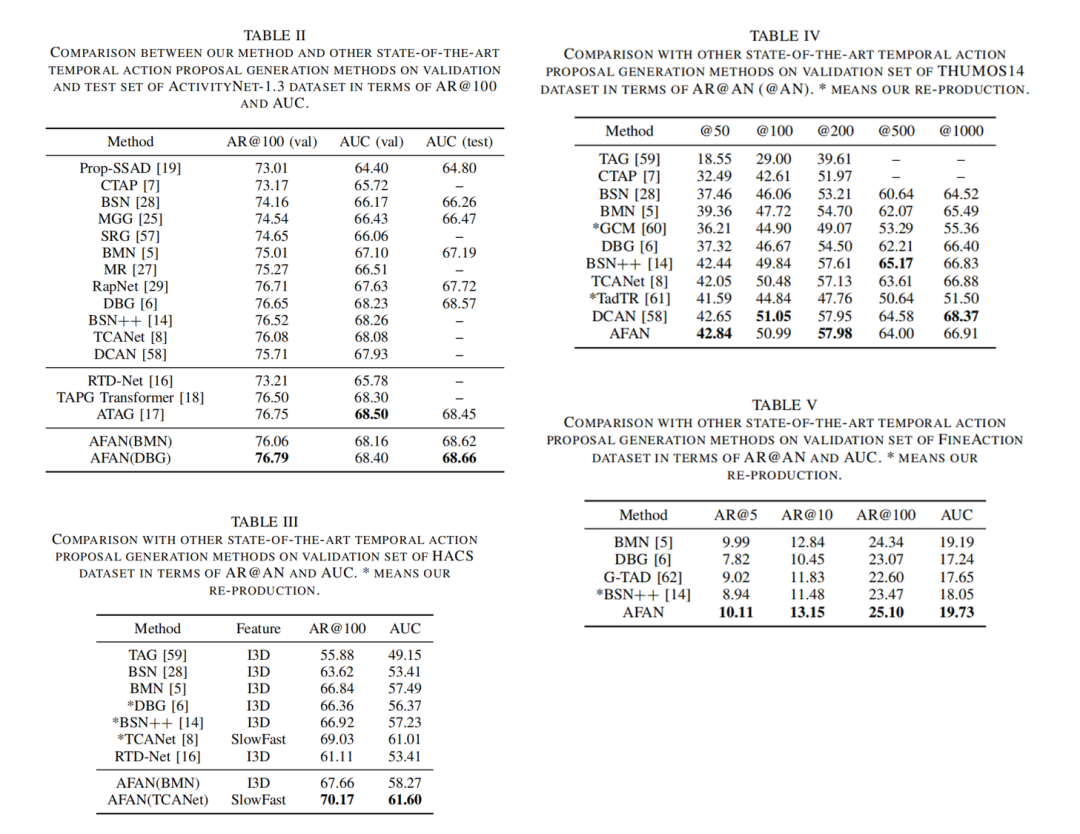
我们在常用的视频时序动作提名生成数据集THUOMO14、ActivityNet-1.3、Fineaction和HACS上,与先进的时序动作提名生成算法进行了对比,并进一步对实验结果进行了分析研究。
不同数据集上的时序动作提名性能对比
实验结果显示,我们的动作频率自适应方法能够有效提升现有时序动作提名生产方法。在ActivityNet-1.3数据集上,我们的模型AFAN(BMN)在验证集和测试集的AUC方面分别比基准方法BMN高出1.06%和1.43%。为了进一步验证我们方法的有效性,我们还基于先进的时序动作提名生成模型DBG进行实验验证。DBG同时生成起始、结束和动作置信度图以评估所有动作提议,与BMN相比,它可以生成更灵活的动作提议。由于具有更好的动作提议生成器DBG,我们的AFAN(DBG)在ActivityNet-1.3数据集上取得了更高的性能。
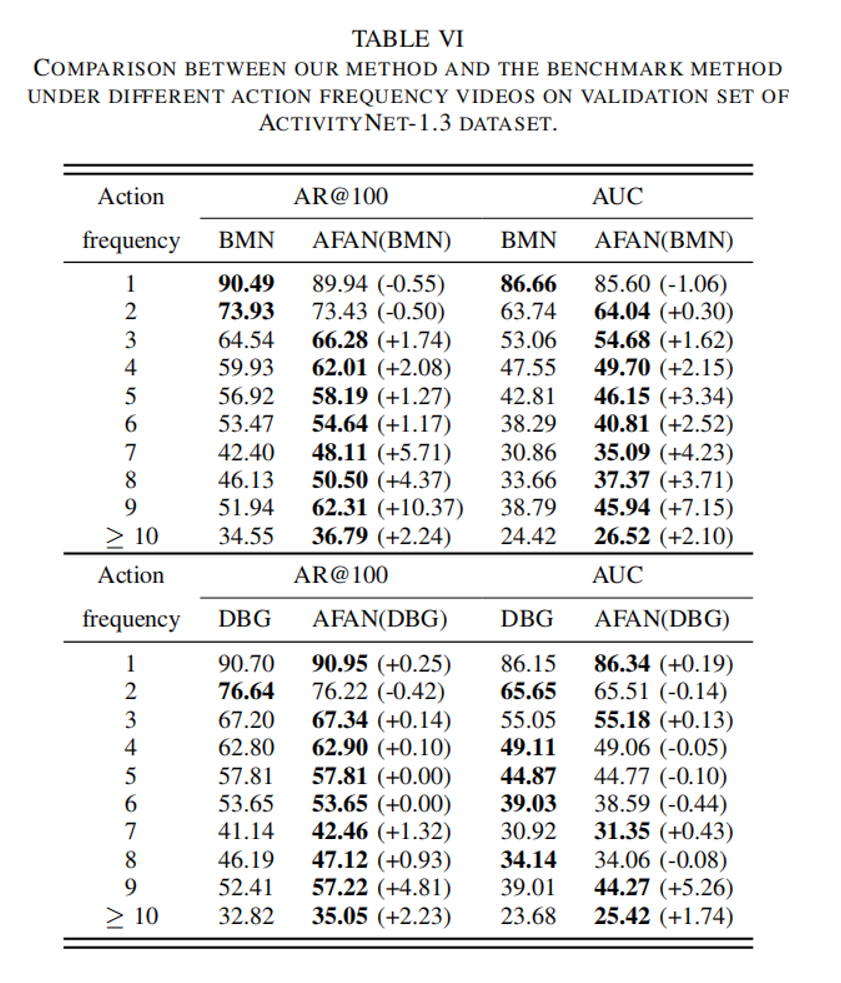
不同动作频率视频的性能对比
此外,我们还分析了不同动作频率视频下的性能以及与相应基准方法进行比较。实验结果显示,我们的动作频率自适应方法能够有效提升高动作频率视频的性能。通过加权知识蒸馏来减轻数据不平衡问题时,低动作频率视频的性能(数量上占主导地位)会略有下降,但仍然保持较高的水平。因此,我们的方法保持了基线方法在低动作频率视频上高性能。而对于高动作频率视频,我们的方法明显优于基准方法。因此,我们的方法在整体性能上取得了更好的表现。
05
总结与展望
本文介绍了一种动作频率自适应视频时序行为提名生成的方法,旨在高质量地完成未剪辑视频中人类动作的定位任务。该方法针对未剪辑视频动作频率变化问题进行研究。通过数据分析,发现现有方法受限于数据不平衡和高频率视频中的短时动作。为此,设计了专家学习模块和精细化处理模块分别用来减小数据不平衡问题和短时动作的影响。在四个基准数据集上进行的大量实验证明了我们方法的有效性和通用性。我们的方法为视频时序行为提名生成的研究提供了新思路,有助于现实场景的应用。
往期回顾