MindSpore AI科学计算系列(30):详解伏羲模型
MindSpore AI科学计算系列(30):详解伏羲模型
前言
自从盘古weather[1]在中长期气象预报精度首次超过传统数值方法,业内开始挖掘气象大模型在这个领域的潜力,基于图神经网络的GraphCast[2]在同化数据ERA5上有着10天内预报高准确率的性能表现。本文介绍的伏羲大模型[3]由复旦大学人工智能创新孵化研究院推出,采用了一种级联的模型架构,可以提供15天的全球预报,具有6小时的时间分辨率和0.25°的空间分辨率,同样是利用39年的ECMWF ERA5再分析数据集开发的。在纬度加权均方根误差(RMSE)和异常相关系数(ACC)的性能评估中,其在15天的预报中可以和ECMWF集合平均(EM)的预报结果相媲美,成为第一个实现这一成就的机器学习模型。
背景
ECMWF的高分辨率预报(HRES)被认为是全球最准确的天气预报模型之一。它的水平分辨率为0.1°,具有137个垂直层次,可以提供为期10天的预报。然而,天气预报天生具有不确定性,原因如下:
1. 有限的分辨率:天气预报的准确性受NWP模型分辨率的影响。较粗的分辨率可能无法完全捕捉到较小尺度的天气现象。
2. 对物理过程的近似:NWP模型依赖参数化方法来表示模型分辨率以下尺度上发生的复杂物理过程,这些参数化方法引入了不确定性。
3. 初始状态的小误差会随着时间放大,导致显著的预报差异。
4. 大气的混沌特性:天气是一个混沌系统,意味着微小的变化可能随着时间产生显著影响。这种对初始条件的敏感性增加了预报的不确定性。
5. 预报提前时间的增加:预报提前的时间越长,不确定性就越大。这是由于各种不确定性和误差的累积效应。
为了解决预报不确定性,像ECMWF这样的天气中心运行集合预报系统(EPS)。ECMWF的EPS包括多个预报,这些预报在初始条件和物理参数化上略有变化。通过运行这些集合成员,可以评估可能结果的范围并估计预报的不确定性。
尽管集合预报具有好处,但由于需要运行多个带有扰动条件的模拟,因此计算代价较高。近年来,有越来越多的努力将传统的NWP模型替换为机器学习模型用于天气预报。基于机器学习的天气预报系统相比NWP模型具有几个优势,包括更快的速度和可能通过使用再分析数据进行训练提供比未校准的NWP模型更高的准确性。为了促进不同机器学习模型之间的比较,引入了WeatherBench基准来评估中期天气预报(即3-5天)。WeatherBench通过重新网格化ERA5再分析数据[4],从0.25°分辨率转换为三种不同的分辨率(5.625°,2.8125°和1.40625°)。
伏羲模型是一种自回归模型,使用前两个时间步的天气参数作为输入,预测下一个时间步的天气参数。模型的时间步长为6小时,通过迭代生成具有不同提前时间的天气预报。由于纯数据驱动的ML模型缺乏物理约束,长期预报容易产生累积误差和不现实的预测。为了解决这个问题,引入自回归的多步损失,类似于4D-Var方法的成本函数,有效减小长期预报的误差。然而,增加自回归步数会导致短期预报的准确性降低,且需要更多的内存和计算资源。
在进行迭代预测时,随着提前时间的增加,误差累积不可避免。此外,单个模型无法在所有提前时间上表现最佳。为了同时在短期和长期预报中获得最佳性能,提出了级联模型架构。该级联模型使用预先训练的伏羲模型,并对特定5天预报时间窗口进行了优化微调,分别为伏羲-短期(0-5天)、伏羲-中期(5-10天)和伏羲-长期(10-15天)。
模型架构
基本的伏羲模型体系结构由三个主要组件组成,如图所示: cube embedding、U-Transformer和全连接层。输入数据结合了上层空气和地表变量,并创建了一个维度为2×70×721×1440的数据立方体,以两个时间步作为一个step。
高维输入数据通过联合时空cube embedding进行维度缩减,转换为C×180×360。cube embedding的主要目的是减少输入数据的时空维度,减少冗余信息。随后,U-Transformer处理嵌入数据,并使用简单的全连接层进行预测,输出首先被重塑为70×720×1440。
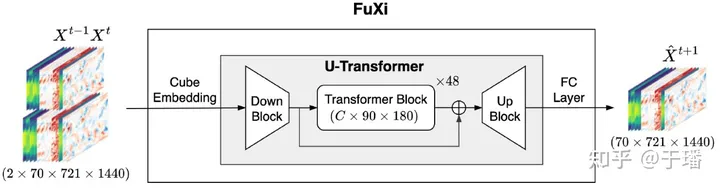
图1. 伏羲模型整体架构
Cube Embedding
为了减少输入数据的空间和时间维度,并加快训练过程,应用了cube embedding方法。在盘古Weather模型中也使用了类似的方法,称为patch embedding。patch embedding将图像划分为N × N大小的块,每个块被转换成一个特征向量。
具体地,空时立方体嵌入采用了一个三维(3D)卷积层,卷积核和步幅分别为2×4×4(相当于T/2×H/2×W/2),输出通道数为C。在空时立方体嵌入之后,采用了层归一化(LayerNorm)来提高训练的稳定性。最终得到的数据立方体的维度是C×180×360。
U-Transformer
U-Transformer还包括U-Net模型的下采样和上采样块。下采样块在图中称为Down Block,将数据维度减少为C×90×180,从而最小化自注意力计算的计算和内存需求。Down Block由一个步长为2的3×3 2D卷积层和一个残差块组成,该残差块有两个3×3卷积层,后面跟随一个组归一化(GN)层和一个Sigmoid加权激活函数(SiLU)。SiLU加权激活函数通过将Sigmoid函数与其输入相乘来计算σ(x)×x。
上采样块在图中称为Up Block,它与Down Block使用相同的残差块,同时还包括一个2D反卷积,内核为2,步长为2。Up Block将数据大小缩放回C×180×360。此外,在馈送到Up Block之前,还包括一个跳跃连接,将Down Block的输出与Transformer Block的输出连接起来。
中间结构是由48个重复的Swin Transformer V2块构建而成,通过使用残差后归一化代替前归一化,缩放余弦注意力代替原始点积自注意力,Swin Transformer V2解决了诸如训练不稳定等训练和应用大规模的Swin Transformer模型会出现几个问题[5]。
模型训练
伏羲模型的训练过程同样是走预训练加微调的线路,与GraphCast方法类似。
1. 单步预训练
通过下一个时间步的监督信息来优化经度加权的L1损失函数:
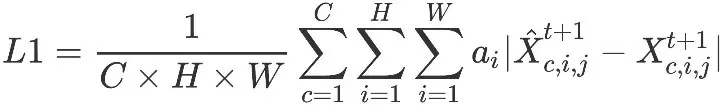
其中,C,H,_W_分别表示通道数和纬度、经度方向上的网格点数。c,i,_j_分别是变量、纬度和经度坐标的索引,_ai_表示在纬度_i_处的权重,随着纬度增加,_ai_的值逐渐减小。最终对某个变量和位置(纬度和经度坐标)的绝对误差进行求和。
2. 微调级联模型
在预训练后,首先对基础伏羲模型进行微调,以实现从0到5天(0-20个时间步)的每6小时预报的最佳性能。这个微调过程使用自回归策略,产生20个时间步,与GraphCast类似,微调后的模型被称为伏羲-Short。
使用伏羲-Short的权重来初始化伏羲-Medium模型,然后对其进行微调,以实现从5天到10天(21-40个时间步)的最佳预报性能。其中,伏羲-Short模型在第20个时间步(第5天)的输出是伏羲-Medium模型的输入,直接实时进行伏羲-Short模型的在线推理会导致显著的内存消耗并且降低微调速度。因此需要提前在六年(2012-2017年)的数据上计算并将伏羲-Short模型的输出结果缓存到硬盘上。
最后,伏羲-Long应用同样的过程,三者被级联在一起,形成完整的15天预报。级联的设计有助于减小误差的积累并提高长期预报的性能,如图所示。
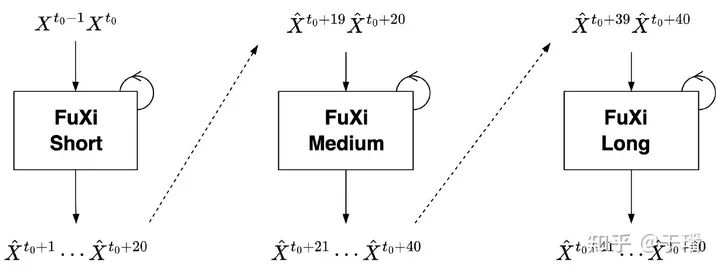
图2. 级联模型架构
评估方法与结果分析
_RMSE_和_ACC_的计算方式如下所示,D_代表测试集,τ_代表预测的提前时间步数,为了比较伏羲模型与基准模型的预测性能,对(RMSEA-RMSEB)/RMSEB_和(ACCA-ACCB)/(1-ACCB)_进行可视化。
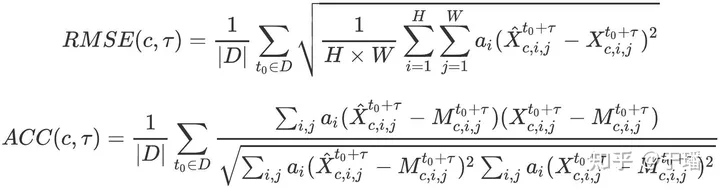 测试集选用了2018年数据,并选择了每天两个初始化时间(00:00 UTC和12:00 UTC),以产生每6小时间隔的15天预报。为了评估ECMWF HRES和EM模型的性能,研究采用了ECMWF机构应用的验证方法。在这种验证方法中,模型分析数据,即HRES-fc0和ENS-fc0,分别作为HRES和EM模型的"地面真实值"。
测试集选用了2018年数据,并选择了每天两个初始化时间(00:00 UTC和12:00 UTC),以产生每6小时间隔的15天预报。为了评估ECMWF HRES和EM模型的性能,研究采用了ECMWF机构应用的验证方法。在这种验证方法中,模型分析数据,即HRES-fc0和ENS-fc0,分别作为HRES和EM模型的"地面真实值"。
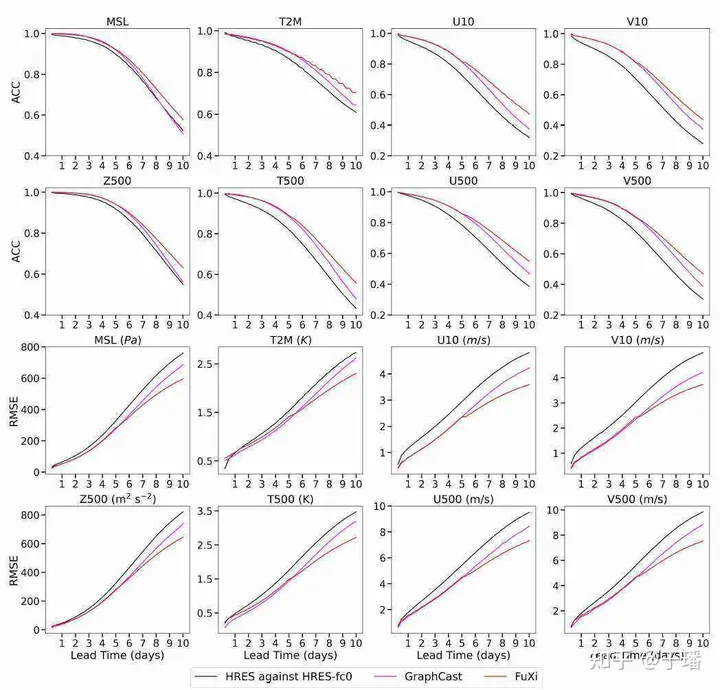
图3. HRES、GraphCast和伏羲的全球平均纬度加权 ACC 和 RMSE 比较
从图中可以看出,FuXi和GraphCast的预测性能明显优于ECMWF HRES。在预测7天内,FuXi和GraphCast的性能相当;然而,超过7天后,FuXi表现出更优越的性能,其在所有变量和预测提前时间上均具有最低的_RMSE_值和最高的_ACC_值。此外,随着提前时间的增加,FuXi的优势变得越来越显著。值得注意的是,FuXi在图中未显示的变量上也胜过ECMWF HRES和GraphCast。
另一方面,ECMWF EM被用作15天预报ACC和RMSE的归一化差异的基准。在0-9天的预测中,FuXi的性能优于ECMWF EM,归一化_ACC_差异为正值,归一化_RMSE_差异为负值。然而,对于超过9天的预测,FuXi的性能略逊于ECMWF EM,结果如下图所示。
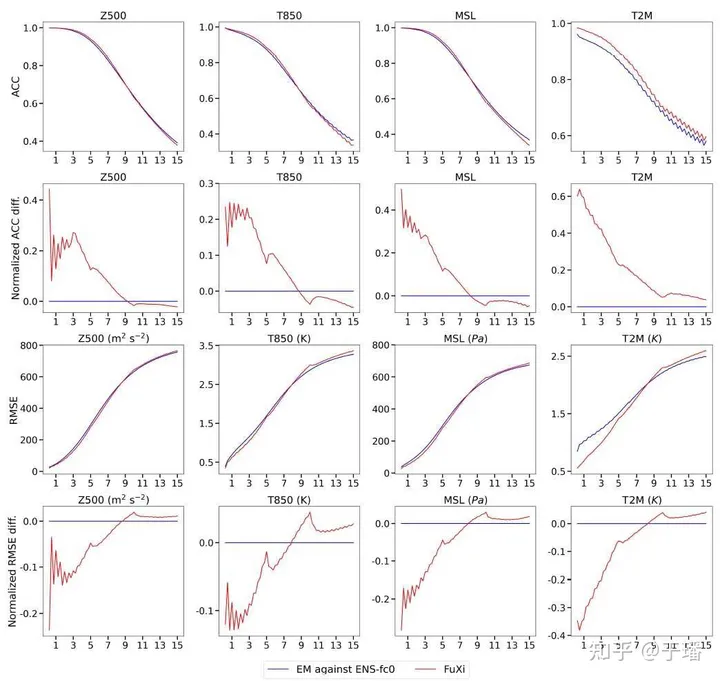
图4. ECMWF EM和伏羲的全球平均纬度加权ACC和RMSE以及归一化ACC和RMSE差异的比较
更进一步,通过FuXi的平均RMSE、ECMWF HRES与FuXi之间的_RMSE_差异,以及ECMWF EM与FuXi之间的_RMSE_差异的空间分布可视化看到,三个预测的空间误差分布相似。最高的_RMSE_值出现在高纬度地区,而相对较小的值出现在中低纬度地区。在陆地上,_RMSE_值较海洋上较高。ECMWF HRES与FuXi之间的_RMSE_差异显示FuXi在大多数网格点上表现优于ECMWF HRES,如红色占优势所示。相比之下,ECMWF EM在大多数区域与FuXi表现相当,如白色占优势所示。
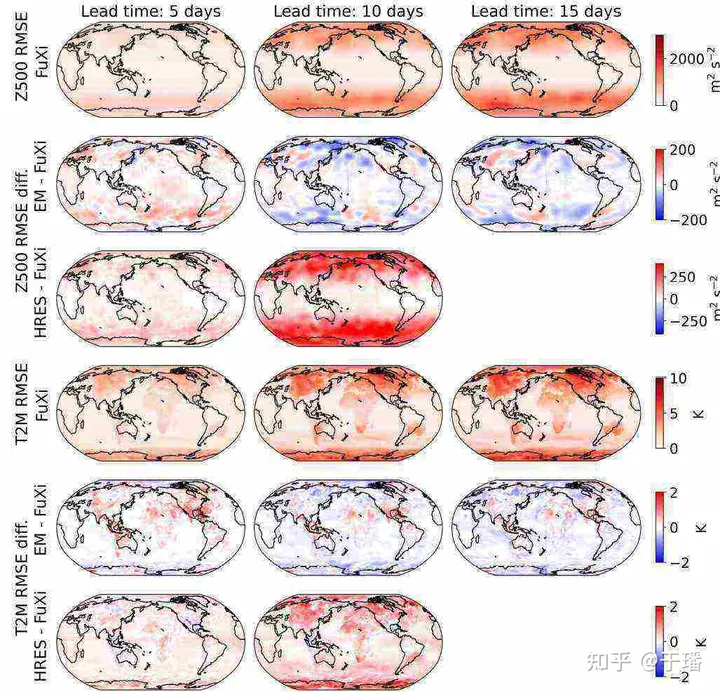
图5. 伏羲的平均RMSE, ECMWF HRES和伏羲的RMSE差异以及EM和伏羲的RMSE差异在空间图上的表示
最后,尽管通过级联模型的方式,伏羲在15天预报中与ECMWF EM性能相当,但基于机器学习的天气预报方法的一个局限性是它们还不完全是端到端的,因为它们仍然依赖于由传统数值天气预报模型生成的分析数据用于初始条件。因此,开发数据驱动的数据同化方法,利用观测数据为基于机器学习的天气预报系统生成初始条件也是未来的一个趋势,从而构建一个真正的端到端、系统无偏和计算高效的基于机器学习的天气预报系统。
[1] Bi, K., Xie, L., Zhang, H., Chen, X., Gu, X., Tian, Q.: Pangu-Weather:A 3D High-Resolution Model for Fast and Accurate Global Weather Forecast (2022)
[2] Lam, R., Sanchez-Gonzalez, A., Willson, M., Wirnsberger, P., Fortunato,M., Pritzel, A., Ravuri, S., Ewalds, T., Alet, F., Eaton-Rosen, Z., Hu, W.,Merose, A., Hoyer, S., Holland, G., Stott, J., Vinyals, O., Mohamed, S.,
Battaglia, P.: GraphCast: Learning skillful medium-range global weather forecasting (2022)
[3] Chen L, Zhong X, Zhang F, et al. FuXi: A cascade machine learning forecasting system for 15-day global weather forecast (2023)
[4] Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Hor´anyi, A., Mu˜noz-Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., et al.: The era5 global reanalysis. Quarterly Journal of the Royal Meteorological Society146(730), 1999–2049 (2020)
[5] Liu, Z., Hu, H., Lin, Y., Yao, Z., Xie, Z., Wei, Y., Ning, J., Cao, Y., Zhang, Z., Dong, L., Wei, F., Guo, B.: Swin Transformer V2: Scaling Up Capacity and Resolution (2022)