昇思应用案例 | 助推AI研究的利器:自动化向量vmap
昇思应用案例 | 助推AI研究的利器:自动化向量vmap
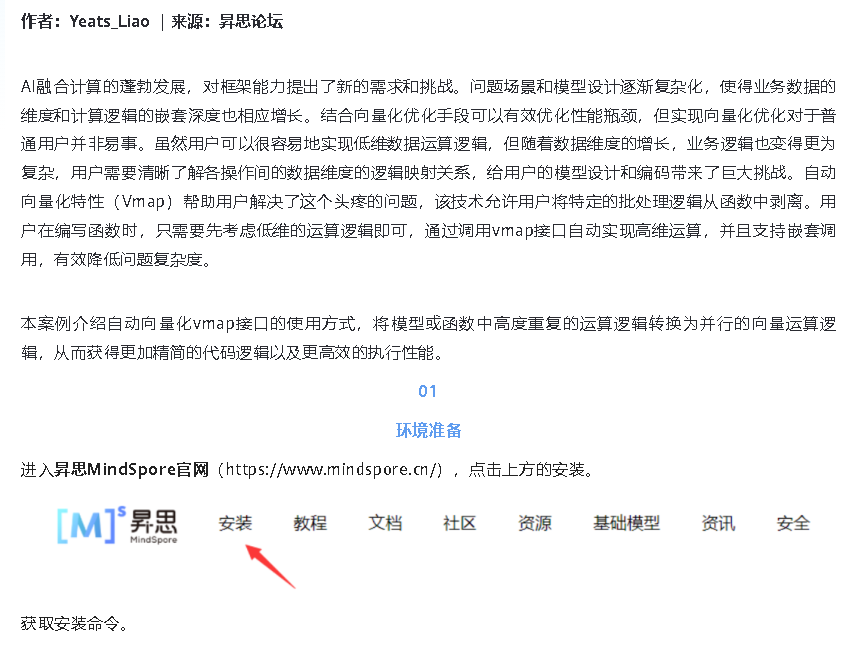
conda install mindspore=2.0.0a0 -c mindspore -c conda-forge
安装mindvision。
pip install mindvision
02
向量化思维
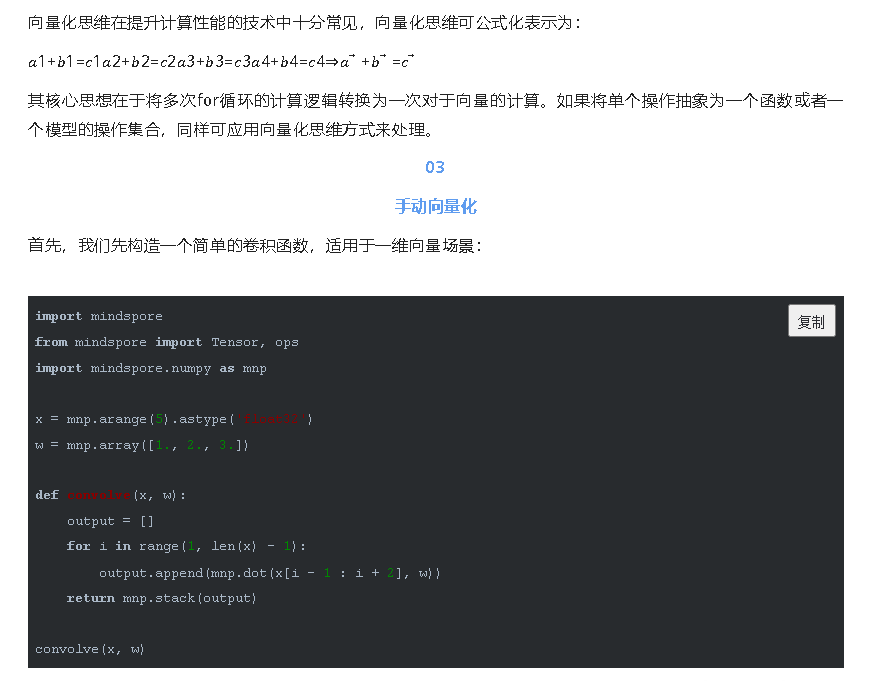
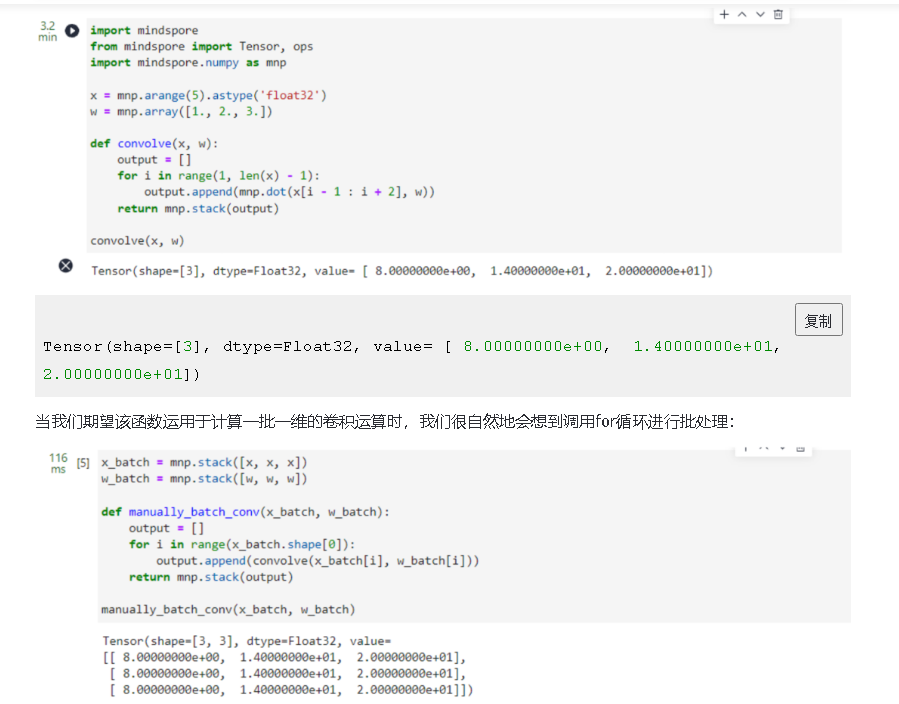
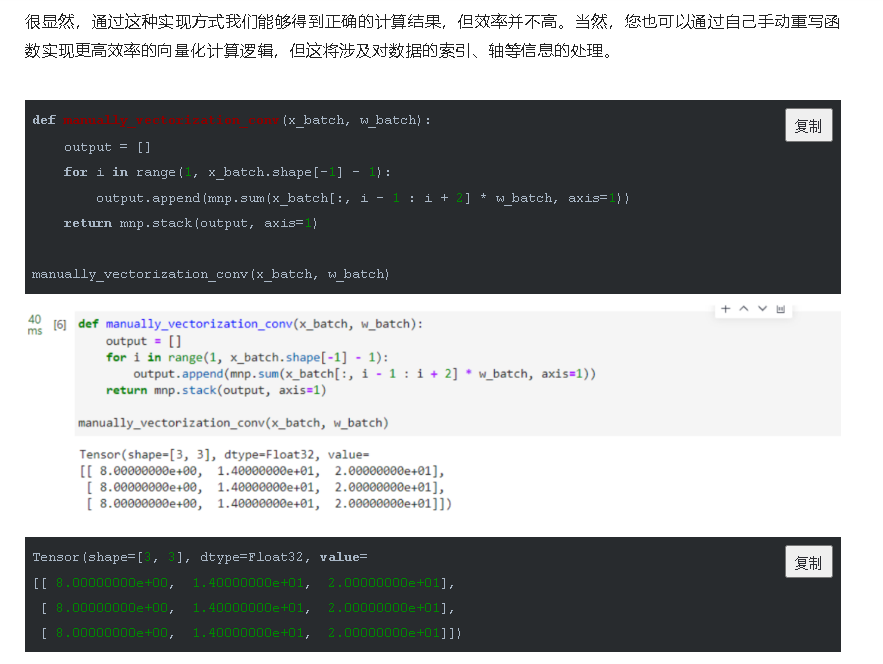
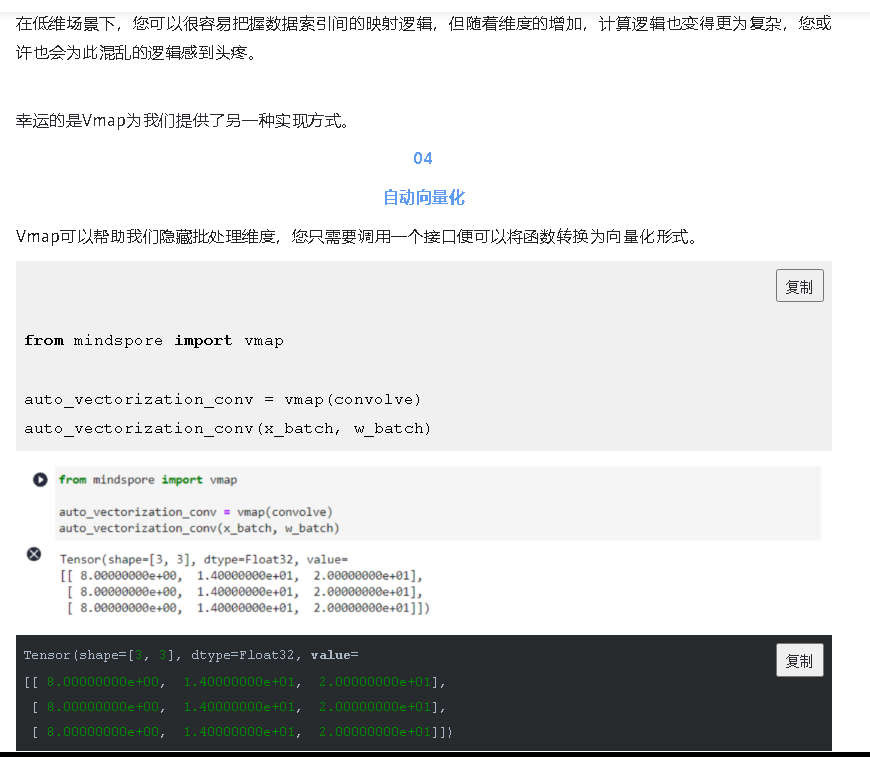
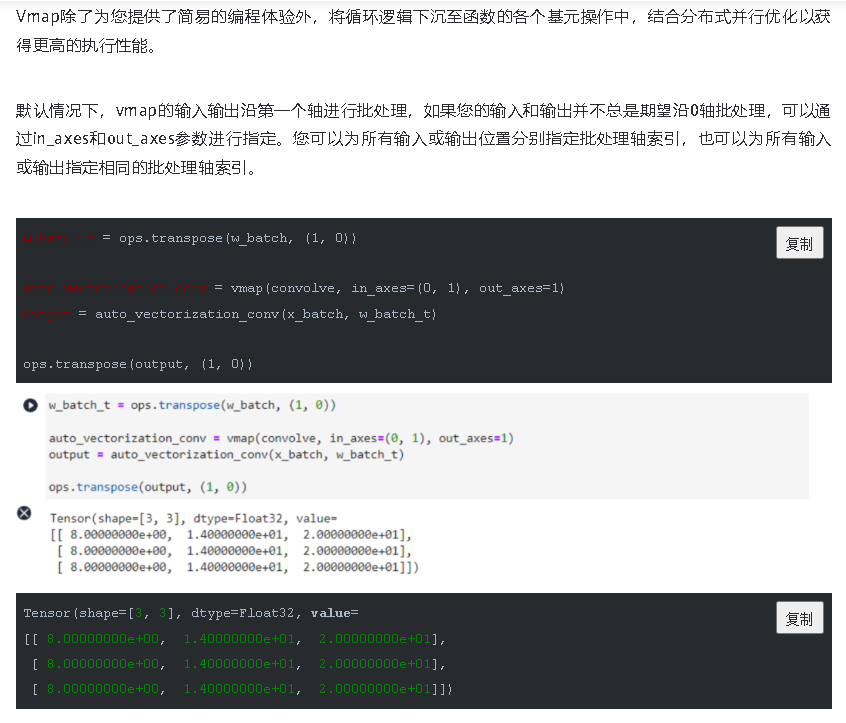
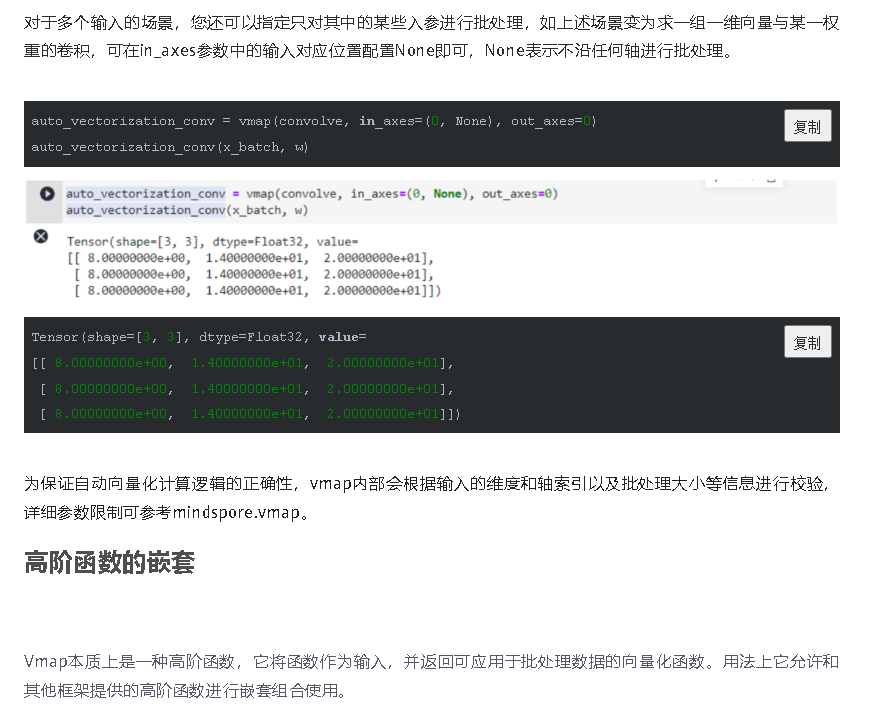
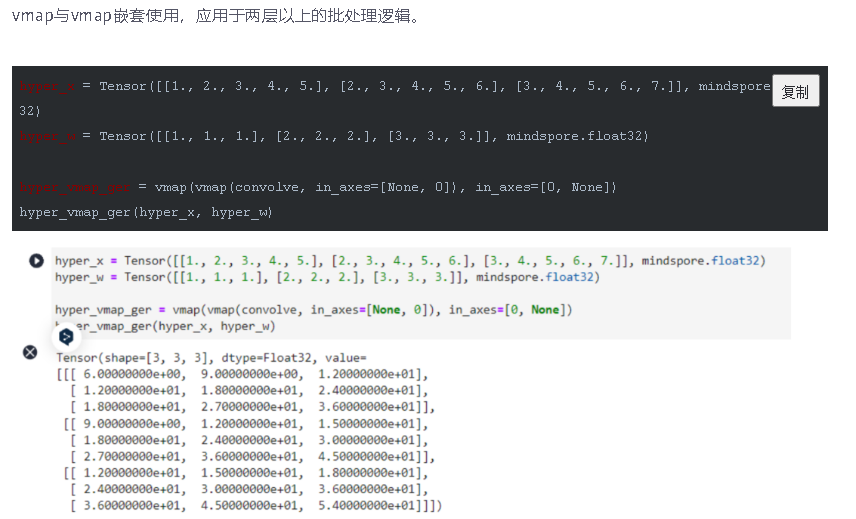
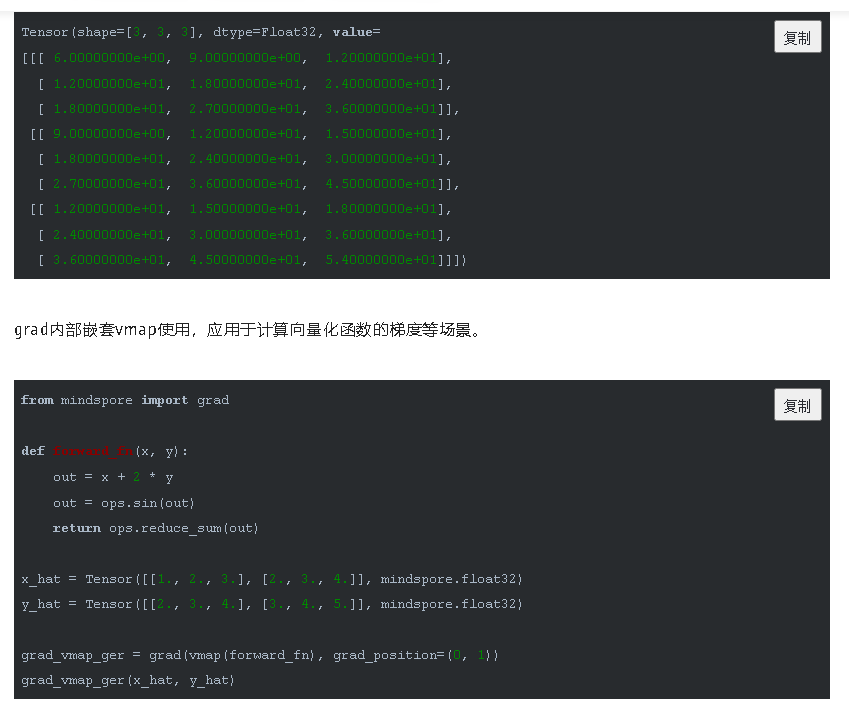
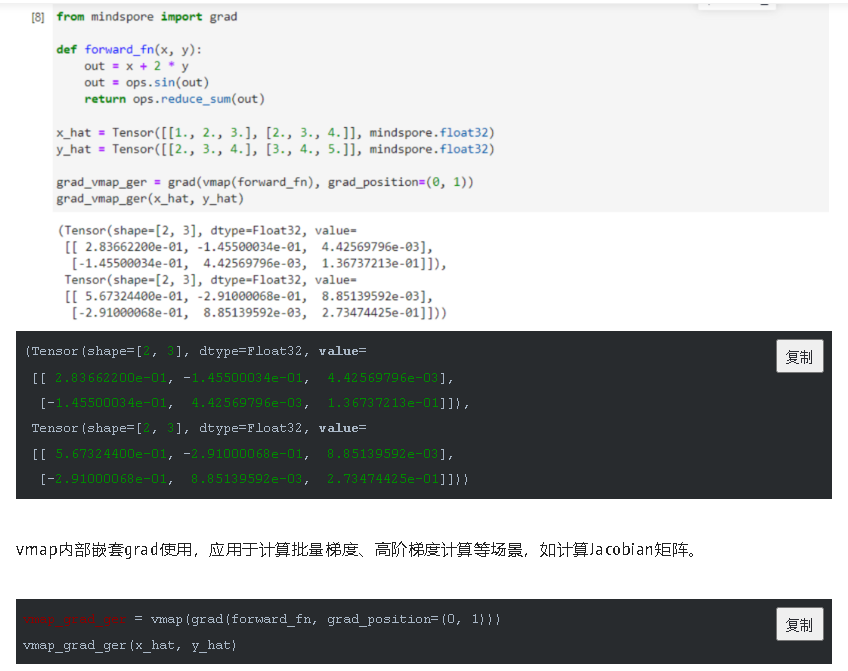
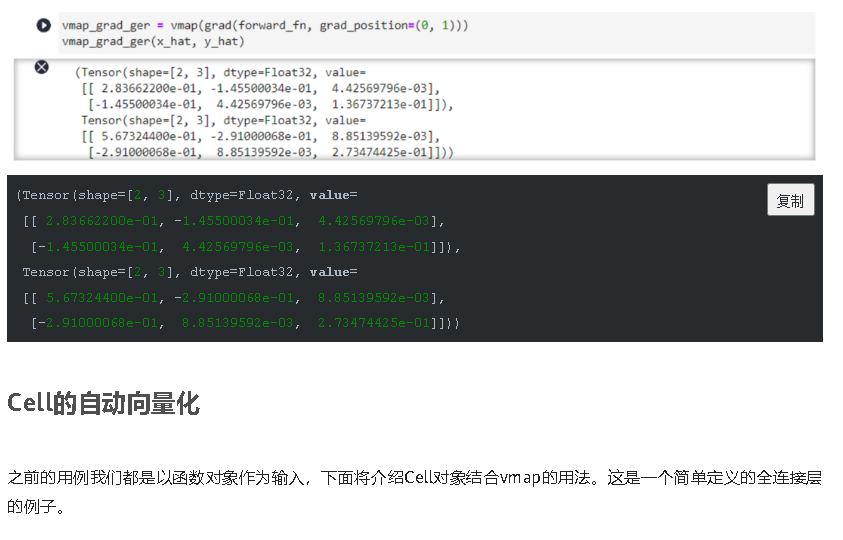
通过这种方式,我们可以实现批量输入在同一个模型上进行训练或推理等功能,与现有网络模型输入支持batch轴输入的区别在于,利用Vmap实现的批处理维度更加灵活,不局限于NCHW等输入格式。
模型集成场景
模型集成场景将来自多个模型的预测结果组合在一起,传统的实现方式是通过分别在某些输入上运行各个模型,然后将各自的预测结果组合在一起。假如您正在运行的是具有相同架构的模型,那么您可以借助Vmap将它们进行向量化,从而实现加速效果。
该场景下涉及权重数据的向量化,如果您运行的模型是通过函数式编程形式实现,即权重参数在模型外部定义并通过入参传递给模型操作,那您可以直接通过配置in_axes的方式进行相应的批处理。而MindSpore框架为了提供便捷的模型定义功能,绝大部分nn接口的权重参数都在接口内部定义并初始化,这意味着模型中的权重参数在原始Vmap中无法对权重进行批处理,改造成通过入参传递的函数式实现需要额外工作量。不过您不必担心,MindSpore的vmap接口已经替您优化了该场景。您只需要将运行的多个模型实例以CellList的形式传入给vmap,框架即可自动实现权重参数的批处理。
让我们演示如何使用一组简单的CNN模型来实现模型集成推理和训练。
class LeNet5(nn.Cell):
"""
LeNet-5网络结构
"""
def __init__(self, num_class=10, num_channel=1):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid')
self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid')
self.fc1 = nn.Dense(16 * 5 * 5, 120)
self.fc2 = nn.Dense(120, 84)
self.fc3 = nn.Dense(84, num_class)
self.relu = nn.ReLU()
self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
def construct(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.conv2(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
假设我们正在验证同一模型架构在不同权重参数下的效果,让我们模拟四个已经训练好的模型实例和一份batch大小为16,尺寸为32 x 32的虚拟图像数据集的minibatch。
net1 = LeNet5()
net2 = LeNet5()
net3 = LeNet5()
net4 = LeNet5()
minibatch = Tensor(mnp.randn(3, 1, 32, 32), mindspore.float32)
相较于利用for循环分别运行各个模型后将预测结果集合到一起,Vmap能够一次运行获得多个模型的预测结果。
注意,由于vmap的实现机制,会对设备运行内存有要求,使用vmap可能会占用更多内存,请用户根据实际场景使用。
nets = nn.CellList([net1, net2, net3, net4])
vmap(nets, in_axes=None)(minibatch)
Tensor(shape=[4, 3, 10], dtype=Float32, value=
[[[ 4.66281290e-06, -7.24548045e-06, 8.68147254e-07 ... 1.42438457e-05, 1.49375774e-05, -1.18535736e-05],
[ 9.10962353e-06, -5.63606591e-06, -7.06250285e-06 ... 1.68580664e-05, 1.41603141e-05, -3.55220163e-06],
[ 1.11184154e-05, -6.08020900e-06, -5.08124231e-06 ... 1.37913748e-05, 1.20597506e-05, -1.01803471e-05]],
[[ 3.22165624e-06, 6.22022753e-06, 2.60713023e-07 ... -1.53302244e-05, 2.34313102e-05, -4.16413786e-06],
[ 2.82950850e-06, 1.54561894e-06, 5.19753303e-06 ... -1.53819674e-05, 1.58681542e-05, -7.10185304e-07],
[ 1.77780748e-07, 4.33479636e-06, -1.35376536e-06 ... -1.06113021e-05, 1.58355688e-05, -5.78900153e-06]],
[[ 6.66864071e-06, -1.99870119e-05, -1.30958688e-05 ... 3.68208202e-06, -9.69678968e-06, 9.59075351e-06],
[ 7.99765985e-06, -1.16931469e-05, -1.06589669e-05 ... -1.24687813e-06, -8.65744005e-06, 6.81729716e-06],
[ 6.87587362e-06, -1.23972441e-05, -1.05251866e-05 ... 1.44004912e-06, -5.40550172e-06, 6.71799853e-06]],
[[-3.44783439e-06, 2.32537104e-07, -8.64402864e-06 ... 3.52633970e-06, -6.27670488e-06, 3.27721250e-06],
[-6.90392517e-06, -9.97693860e-07, -6.48076320e-06 ... 7.61923275e-07, -2.54563452e-06, 3.08638573e-06],
[-3.78440518e-06, 3.93633945e-06, -7.90367903e-06 ... 5.13138957e-07, -4.50420839e-06, 2.13702333e-06]]])
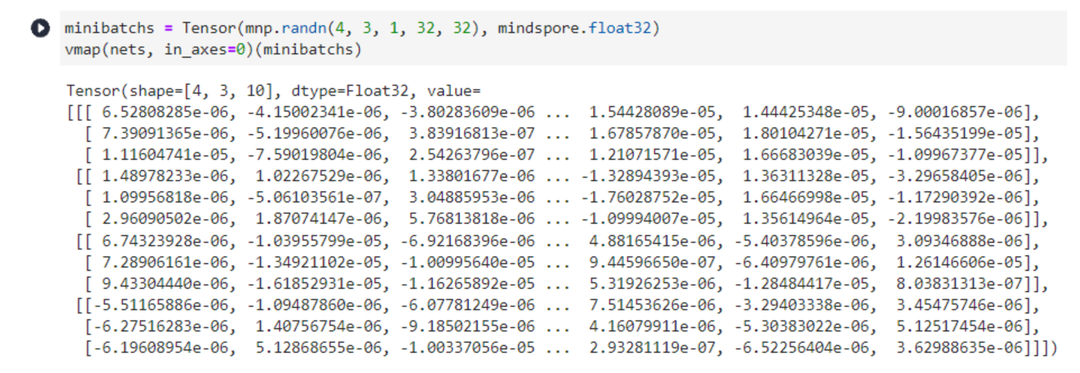
又或者,我们期望得到多个模型分别执行不同minibatch数据的预测结果。
模型集成场景下,vmap的第一个入参应为CellList类型,需要确保每个模型的架构完全相同,否则无法保证计算正确性,如果in_axes不为None是需保证模型数量与映射轴索引对应的axis_size一致,以实现一一映射关系。
minibatchs = Tensor(mnp.randn(4, 3, 1, 32, 32), mindspore.float32)
vmap(nets, in_axes=0)(minibatchs)
Tensor(shape=[4, 3, 10], dtype=Float32, value=
[[[ 6.52808285e-06, -4.15002341e-06, -3.80283609e-06 ... 1.54428089e-05, 1.44425348e-05, -9.00016857e-06],
[ 7.39091365e-06, -5.19960076e-06, 3.83916813e-07 ... 1.67857870e-05, 1.80104271e-05, -1.56435199e-05],
[ 1.11604741e-05, -7.59019804e-06, 2.54263796e-07 ... 1.21071571e-05, 1.66683039e-05, -1.09967377e-05]],
[[ 1.48978233e-06, 1.02267529e-06, 1.33801677e-06 ... -1.32894393e-05, 1.36311328e-05, -3.29658405e-06],
[ 1.09956818e-06, -5.06103561e-07, 3.04885953e-06 ... -1.76028752e-05, 1.66466998e-05, -1.17290392e-06],
[ 2.96090502e-06, 1.87074147e-06, 5.76813818e-06 ... -1.09994007e-05, 1.35614964e-05, -2.19983576e-06]],
[[ 6.74323928e-06, -1.03955799e-05, -6.92168396e-06 ... 4.88165415e-06, -5.40378596e-06, 3.09346888e-06],
[ 7.28906161e-06, -1.34921102e-05, -1.00995640e-05 ... 9.44596650e-07, -6.40979761e-06, 1.26146606e-05],
[ 9.43304440e-06, -1.61852931e-05, -1.16265892e-05 ... 5.31926253e-06, -1.28484417e-05, 8.03831313e-07]],
[[-5.51165886e-06, -1.09487860e-06, -6.07781249e-06 ... 7.51453626e-06, -3.29403338e-06, 3.45475746e-06],
[-6.27516283e-06, 1.40756754e-06, -9.18502155e-06 ... 4.16079911e-06, -5.30383022e-06, 5.12517454e-06],
[-6.19608954e-06, 5.12868655e-06, -1.00337056e-05 ... 2.93281119e-07, -6.52256404e-06, 3.62988635e-06]]])
除了支持模型集成推理外,结合Vmap特性同样能够实现模型集成训练。
from mindspore.common.parameter import ParameterTuple
class TrainOneStepNet(nn.Cell):
def __init__(self, net, lr):
super(TrainOneStepNet, self).__init__()
self.loss_fn = nn.WithLossCell(net, nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean'))
self.weight = ParameterTuple(net.trainable_params())
self.adam_optim = nn.Adam(self.weight, learning_rate=lr, use_amsgrad=True)
def construct(self, batch, targets):
loss = self.loss_fn(batch, targets)
grad_weights = grad(self.loss_fn, grad_position=None, weights=self.weight)(batch, targets)
self.adam_optim(grad_weights)
return loss
train_net1 = TrainOneStepNet(net1, lr=1e-2)
train_net2 = TrainOneStepNet(net2, lr=1e-3)
train_net3 = TrainOneStepNet(net3, lr=2e-3)
train_net4 = TrainOneStepNet(net4, lr=3e-3)
train_nets = nn.CellList([train_net1, train_net2, train_net3, train_net4])
model_ensembling_train_one_step = vmap(train_nets)
images = Tensor(mnp.randn(4, 3, 1, 32, 32), mindspore.float32)
labels = Tensor(mnp.randint(1, 10, (4, 3)), mindspore.int32)
for i in range(1, 11):
loss = model_ensembling_train_one_step(images, labels)
print("Step {} - loss: {}".format(i, loss))
vmap(nets, in_axes=None)(minibatch)
Step 1 - loss: [2.3025837 2.3025882 2.3025858 2.3025842]
Step 2 - loss: [2.260927 2.301028 2.2992857 2.2976868]
Step 3 - loss: [1.8539654 2.2993202 2.2951114 2.2899477]
Step 4 - loss: [0.77165794 2.2973287 2.288719 2.2726345 ]
Step 5 - loss: [0.9397469 2.2948549 2.2777178 2.2313874]
Step 6 - loss: [0.6747699 2.29158 2.2579656 2.1410708]
Step 7 - loss: [0.64673084 2.2870557 2.2232006 1.966973 ]
Step 8 - loss: [1.0506033 2.2806385 2.1645374 1.6848679]
Step 9 - loss: [0.612196 2.2714498 2.0706694 1.3499321]
Step 10 - loss: [0.8843982 2.258316 1.9299208 1.1472267]
Tensor(shape=[4, 3, 10], dtype=Float32, value=
[[[-1.91058636e+01, -1.92182674e+01, 1.06328402e+01 ... -1.87287464e+01, -1.87855473e+01, -2.02504387e+01],
[-1.94767399e+01, -1.95909595e+01, 1.08379564e+01 ... -1.90921249e+01, -1.91503220e+01, -2.06434765e+01],
[-1.96521702e+01, -1.97674465e+01, 1.09355783e+01 ... -1.92643051e+01, -1.93227654e+01, -2.08293762e+01]],
[[-4.07293849e-02, -4.27918807e-02, 5.22112176e-02 ... -4.67570126e-02, -3.88025381e-02, 4.88412194e-02],
[-3.91553082e-02, -4.11494374e-02, 5.00433967e-02 ... -4.48847115e-02, -3.73134986e-02, 4.68519926e-02],
[-3.80369201e-02, -3.99325565e-02, 4.84890938e-02 ... -4.35365662e-02, -3.62745039e-02, 4.54225838e-02]],
[[-5.08784056e-01, -5.05123973e-01, 5.20882547e-01 ... 4.72596169e-01, -5.00697553e-01, -4.60489392e-01],
[-4.80103493e-01, -4.76664037e-01, 4.91507798e-01 ... 4.46062207e-01, -4.72493649e-01, -4.34652239e-01],
[-4.81168061e-01, -4.77702975e-01, 4.92583781e-01 ... 4.47029382e-01, -4.73524809e-01, -4.35579300e-01]],
[[-3.66236401e+00, -3.25362825e+00, 3.51312804e+00 ... 3.77490187e+00, -3.36864424e+00, -3.34358120e+00],
[-3.49160767e+00, -3.10209608e+00, 3.34935308e+00 ... 3.59894991e+00, -3.21167707e+00, -3.18782210e+00],
[-3.57623625e+00, -3.17717075e+00, 3.43059325e+00 ... 3.68615556e+00, -3.28948307e+00, -3.26504302e+00]]])
经过模型集成训练的模型除了可以集成推理之外,仍然可以单独进行推理。
net1(minibatch)
往期回顾