论文精讲 | 基于上下文感知转换器的全局视频场景分割
论文精讲 | 基于上下文感知转换器的全局视频场景分割
作者:黄禹睿 |学校**:**南京理工大学
论文标题
基于上下文感知Transformer的全局视频场景分割
论文来源
AAAI2023
代码链接
01
研究背景
随着近年来人们拍摄视频的需求更多、传输视频的速度更快、存储视频的空间更大, 多种场景下积累了大量的视频数据,需要有效地对视频进行管理、分析和处理。视频理解旨在通过智能分析技术,自动化地对视频中的内容进行识别和解析。
视频理解算法顺应了这个时代的需求,因此,近年来受到了广泛关注,取得了快速发展。视频理解涉及多个领域,如动作识别、视频检索、视频问答以及视频场景分割。以电影为例,对于人类来说,理解电影首先要明白电影的每一部分都在讲述着怎样的故事,对于人工智能来说亦是此。视频场景分割任务,就是将视频按照其所讲述的事件划分成一系列视频场景片段,是实现更高层次视频理解的重要步骤。
具体来说,视频具有帧(frame)、镜头(shot)、场景(scene)这样三级的语义结构。帧是最小的结构单元,镜头是由一台相机在一段时间内连续拍摄的帧,在视觉上是具有连续性;而场景是更高级的语义单元,由一系列语义连贯的镜头构成。场景是基于情节的,在一个场景中,有特定的活动发生在特定的一组角色中。视频场景分割任务就是将视频划分为场景,其可以表述为一个二分类问题,即确定构成视频的一系列镜头是否为场景边界(场景的最后一个镜头)。
目前该领域的解决办法可以分为三类:
1)无监督视频场景分割方法:由于标记数据较少,早期的尝试主要是采用无监督学习的方法将相邻的镜头进行对比或聚类。Rui 等人[1]将镜头分组到具有时间自适应相似性的语义相关场景中;Rasheed 等人[2]对动作内容、镜头长度和颜色属性进行聚类,将细粒度聚类作为动态场景;Chasanis 等人[3]提出了一种改进的光谱聚类方法,并采用全局k-means算法对镜头进行分组Baraldi 等人[4]引入深度连体网络,将视频分割成连贯的场景;Baraldi等人[4]和Sidiropoulos 等人[5]融合多模态数据,如音频和视觉特征来生成最终的分割。然而,这些方法往往依赖于人工设计的相似度机制,并且没有引入监督数据,因此存在着性能和效率低下的问题。
2)监督视频场景分割方法。为了更好的提升视频场景分割的表现,一些学者开始利用监督数据并使用监督学习的算法。Rotman 等人[6]将场景检测作为一个通用优化问题,将镜头优化后分组作为场景;Das 等人[7]将一个镜头与它的左右上下文连接,进行片段边界预测;Rao 等人[8]提出了分层学习镜头嵌入方法,以提供具有多模态信息的自顶向下场景分割。这些方法往往只考虑了监督视频,而大量无标记视频并没有被很好的利用。
3)自监督视频场景分割。随着自监督学习的兴起,一些学者尝试使用自监督学习的方式解决视频场景分割问题,自监督学习的优点是可以更好的利用无标记数据,为样本学习到更好的表征。Chen 等人[9]提出了一种自监督镜头嵌入方法,学习一个镜头表示,最大限度地提高了临近镜头与随机选择的镜头之间的相似性;Wu 等人[10]在预训练的时候,采用数据增强和变换方法提高模型的鲁棒性;Mun 等人[11]预先训练一个带有伪边界的Transformer Encoder,然后用标记数据对编码器进行微调。然而,在现有的自监督方法中,没有很好地解决借口任务设计策略和高阶上下文表示问题。
02
模型介绍
电影或电视剧等视频通常需要将较长的故事情节划分为有凝聚力的单元,即场景,以便于理解视频语义。关键的挑战在于综合考虑复杂的时间结构和语义信息,找到场景的边界。为此,我们引入了一种新颖的具有自监督学习框架的上下文感知转换器(CAT),以学习高质量的镜头表示,用于生成边界良好的场景。更具体地说,我们设计了具有局部全局自关注的CAT,它可以有效地考虑长期和短期上下文,以改进镜头编码。
对于CAT的训练,我们采用了自我监督学习模式。首先,利用镜头到场景级别的借口任务,利用伪边界进行预训练,指导CAT在无监督的情况下学习最大限度地提高场景内相似度和场景间区分度的判别镜头表示;然后,我们将上下文表示转换为带有监督数据的CAT进行微调,这鼓励CAT准确地检测场景分割的边界。
因此,CAT能够学习上下文感知的镜头表示,并为场景分割提供全局指导。我们的实证分析表明,在MovieNet数据集上进行场景分割任务时,CAT可以实现SOTA的性能,例如,在AP上提供2.15的改进。
技术要点一:Context-Aware Transformer(CAT)
我们修改了Transformer的自注意力机制,使得多头自注意力能够同时关注局部和全局特征,以综合来自长期和短期邻居的互补信息,而不是仅用单一层次的上下文信息编码镜头。
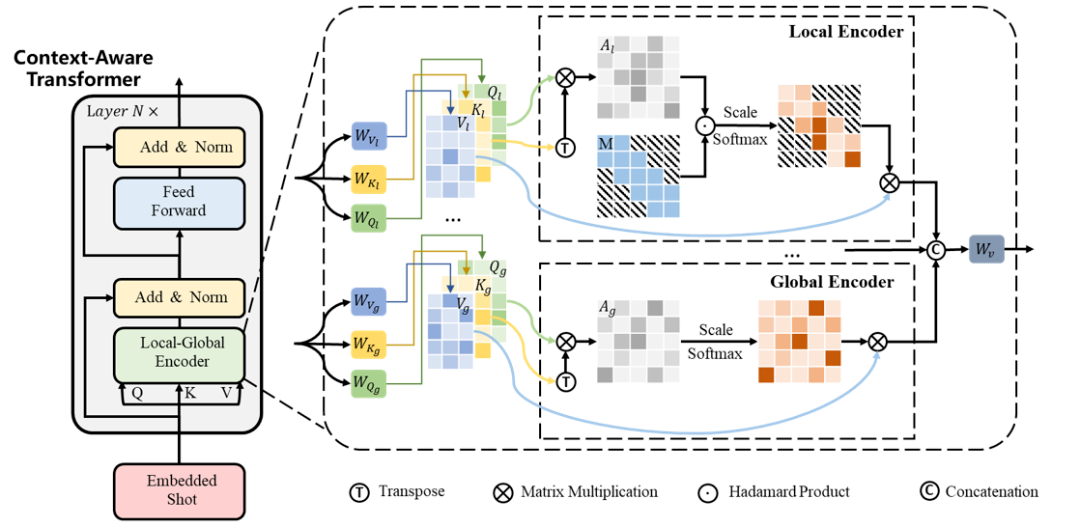
技术要点二:镜头到场景级别的预训练
设计两种级别的代理任务,包括镜头级别(SMM、SOM)代理任务和场景级别(GSM、LSM)代理任务。通过大量无标记数据做预训练,使得模型学习到潜在的场景分割边界。在微调阶段,冻结卷积神经网络参数,通过有标记数据微调CAT,并使用Cross Entropy作为微调阶段的损失函数,具体形式如下:
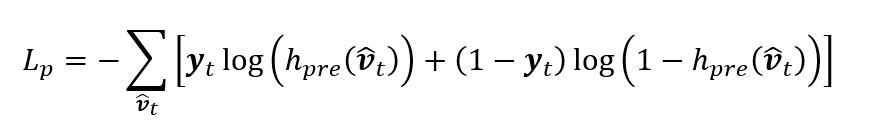
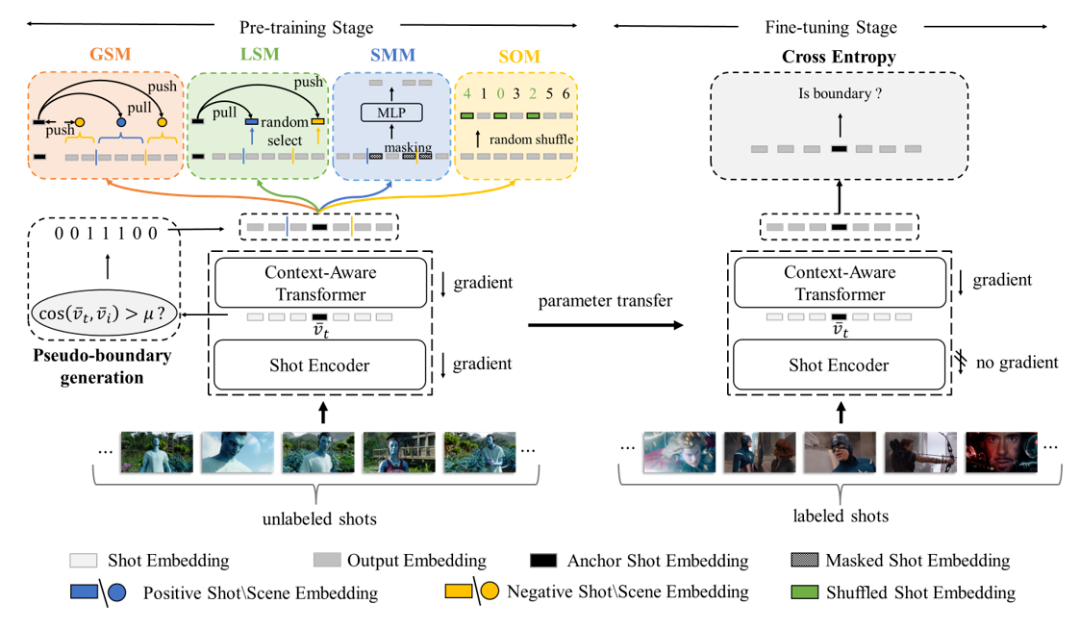
图2.自监督学习拆条架构
03
实验结果
**数据集:**考虑到视频场景分割数据集的可用性和规模,我们采用了遵循所有当前最先进方法的MovieNet数据集[8,9,10,11]。MovieNet数据集[12]发布了1100部电影,其中318部电影带有场景绑定的注解。具体的,MovieNet上的大多数电影的时间分配在90到120分钟之间,提供了关于单个电影故事的丰富信息。整个注释集按照以下[12]在视频级别按10:2:3的比例分为Train、Valid-ation和Test集,场景边界在镜头级别进行注释。注释场景的长度从10秒到120秒不等,其中大部分持续10 ~ 30秒。
**对比方法:**我们将我们的CAT方法与最先进的分割方法进行比较:1)无监督方法,即GraphCut[2],SCSA[3],DP[13],StoryGraph[14],Grouping[6]。2)监督方法,包括Siamese[4],MS-LSTM[12],LGSS[8]; 3)自监督方法,包括ShotCoL[9],SCRL[10],BaSSL[11]。
**评价指标:**在[11]之后,我们采用了四个常用的指标:1)平均精度(AP),2) AUC,3)F1和4)Miou,它测量预测的场景片段和它们最近的地面真实场景片段之间的平均交集/联合(IoU)。
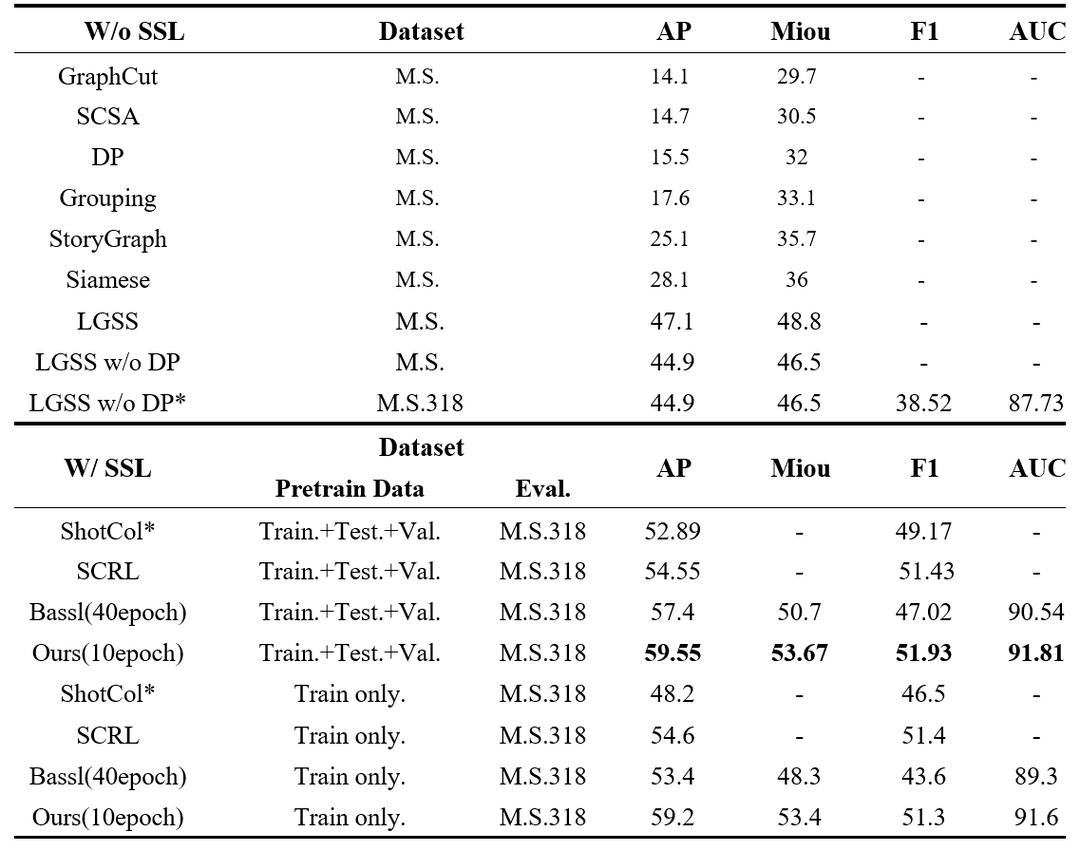
表1. 视频场景分割结果对比
表1总结了对比方法的分割结果。M.S.表示包含150个注释电影的Movie-Scenes数据集,M.S-318表示包含318个注释电影的MovieNet数据集。Eval.表示自监督预训练后用于监督微调的数据集。Train.,Test.,Val.代表MovieNet的训练、测试和验证集[12]。分割结果除*标注外,均直接按照原文采用。“-”表示该结果未在原始论文中给出。
结果表明:
1)有监督方法优于无监督方法,LGSS在AP方面至少提高了20%。这是因为有监督数据可以更好地指导表示学习。
2)自监督式方法进一步提高了性能,这表明了使用无监督数据进行预训练的优势。
- CAT在各种指标上表现最佳,例如CAT优于有监督的最先进方法,即LGSS在AP/mIOU方面的边际为12.45/4.87,优于最先进的自监督方法,即BaSSL在AP/mIOU/F1/AUC方面的边际为2.15/2.98 /4.91/1.27,这表明上下文感知Transformer和预训练目标的有效性。此外,仅使用全局注意力的Transformer的CAT(即使用Transformer的CAT)的性能比CAT差,揭示了使用上下文感知注意力的优势。
4)为了防止数据泄露,我们在训练数据集(660部电影)上再现了自监督方法的性能,以进行比较。与其他性能下降的自监督方法相比,CAT可以在训练数据较少的情况下获得具有竞争力的性能,AP /mIOU /F1 /AUC仅下降0.33/0.23/0.58/0.18。
**代理任务的影响:**为了探索每个训练前目标的贡献,我们用改变训练前任务的使用。从表2中,我们可以得出以下结论:1)SMM任务的性能最差,这表明上下文感知的前文本任务(即GSM、LSM和SOM)能够很好地考虑上下文关系,这对场景分割至关重要。2)场景级任务,即GSM实现了最佳的性能,这表明了考虑场景内和场景间距离的重要性。
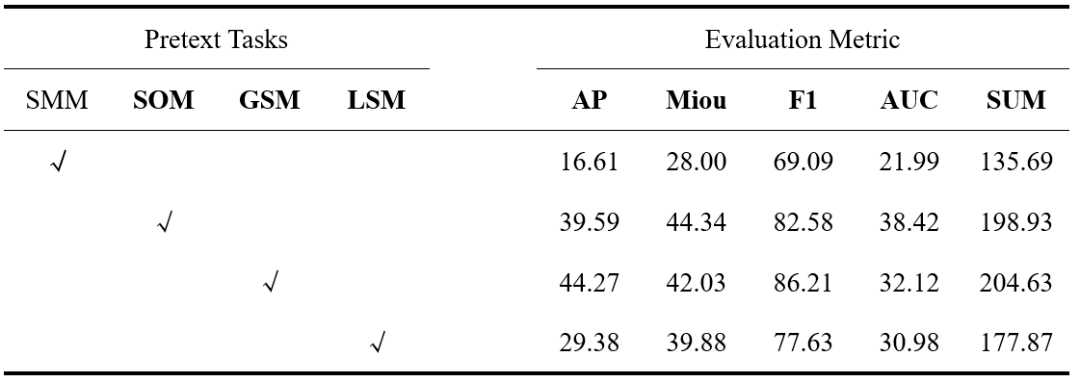
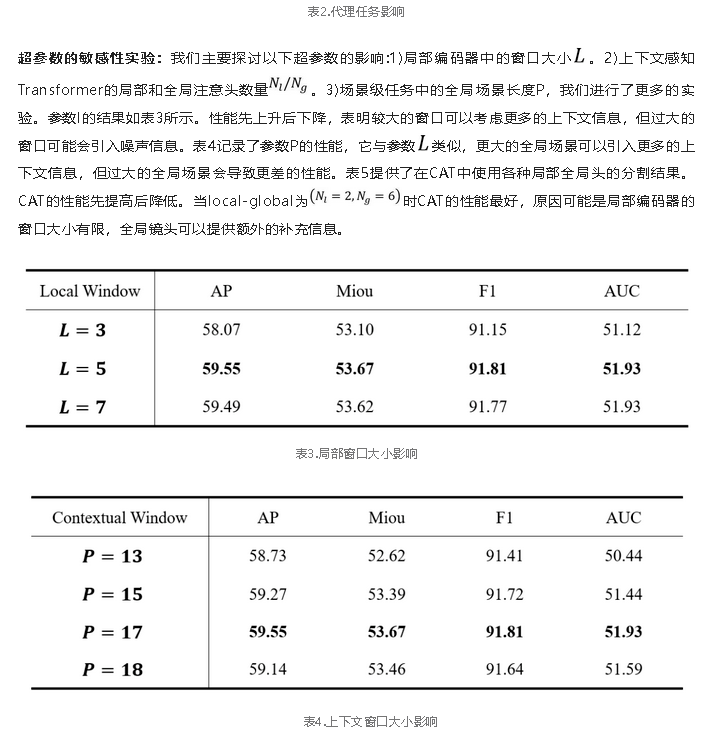
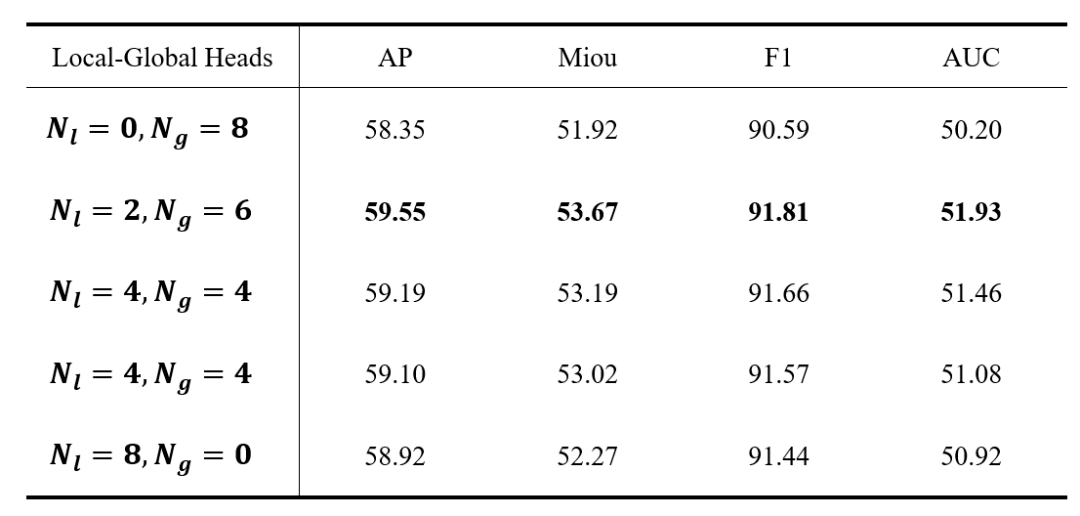
表5.局部和全局头影响
**多模态融合实验:**同前人[8,9,10,11]工作,我们使用多模态数据(即音频和视觉模态)对所提出的方法进行了实验。具体而言,我们采用了后期融合(即使用多模态预测的最大池)同[11]。" - "表示在原文件中没有给出结果。表6记录了结果,我们发现多模态融合比单模态融合性能更好,但音频是弱模态,几乎没有提升。
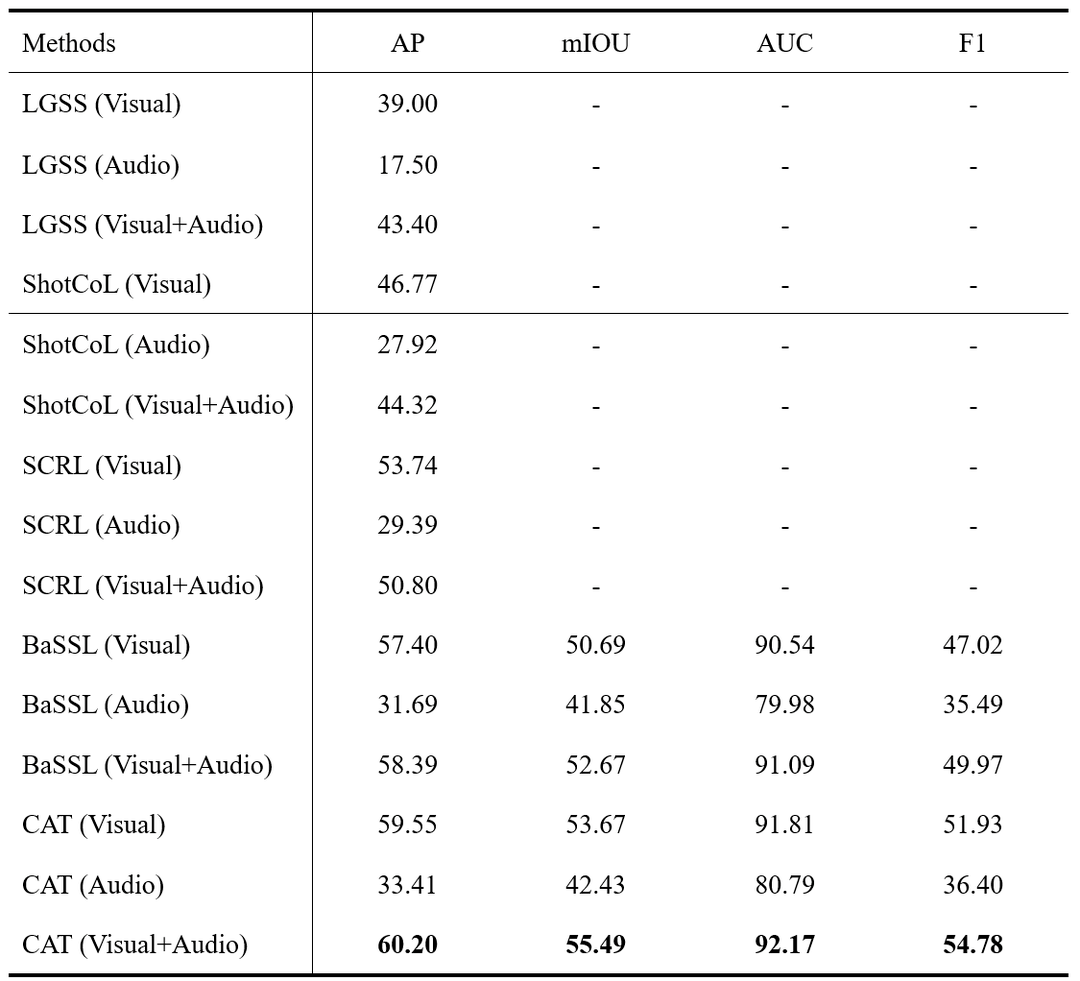
表6.多模态融合实验
**可视化:**为了探索镜头表征的学习,我们进行了更多的实验。我们在图3中展示了分段案例来演示CAT。有两个场景,我们发现一个有明显变化的镜头很可能通过上下文限制的方法预测错误的边界(即黄线),即使它与上下文镜头具有相似的语义。而CAT可以成功预测边界。

图3.预测结果可视化分析
04
总结
在本文中,我们研究了视频分割任务。随着自监督学习的发展,将无监督数据和有监督数据同时用于训练,我们引入了一种新颖的上下文感知转换器(CAT),它具有自监督学习框架,可以学习高质量的镜头表示,用于生成边界良好的场景。详细地,CAT利用局部全局自关注改进镜头编码。
此外,我们设计了镜头到场景级别的借口任务来学习镜头表示,然后我们用监督数据直接微调CAT。实证分析表明,CAT在执行场景分割任务时能够达到最先进的性能。
在未来,如何设计一种更健壮的多模态融合策略将是一项有趣的工作。昇思MindSpore是华为开源的新一代全场景AI框架,支持端、边、云全场景灵活部署,开创全新的AI编程范式,降低AI开发门槛,旨在实现开发友好、运行高效、部署灵活三大目标,同时着力构筑面向全球的人工智能开源社区,推动人工智能软硬件应用生态繁荣发展。在未来将会有越来越多的基于昇思MindSpore的AI应用诞生。
参考文献:
[1] Rui Y, Huang T S, Mehrotra S. Exploring video structure beyond the shots[C]//Proceedings. IEEE International Conference on Multimedia Computing and Systems (Cat. No. 98TB100241). IEEE, 1998: 237-240.
[2] Rasheed Z, Shah M. Scene detection in Hollywood movies and TV shows[C]//2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2003. Proceedings. IEEE, 2003, 2: II-343.
[3] Chasanis V T, Likas A C, Galatsanos N P. Scene detection in videos using shot clustering and sequence alignment[J]. IEEE transactions on multimedia, 2008, 11(1): 89-100.
[4] Baraldi L, Grana C, Cucchiara R. A deep siamese network for scene detection in broadcast videos[C]//Proceedings of the 23rd ACM international conference on Multimedia. 2015: 1199-1202.
[5] Sidiropoulos P, Mezaris V, Kompatsiaris I, et al. Temporal video segmentation to scenes using high-level audiovisual features[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2011, 21(8): 1163-1177.
[6] Rotman D, Porat D, Ashour G. Optimal sequential grouping for robust video scene detection using multiple modalities[J]. International Journal of Semantic Computing, 2017, 11(02): 193-208.
[7] Das A, Das P P. Incorporating domain knowledge to improve topic segmentation of long MOOC lecture videos[J]. arXiv preprint arXiv:2012.07589, 2020.
[8] Rao A, Xu L, Xiong Y, et al. A local-to-global approach to multi-modal movie scene segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10146-10155.
[9] Chen S, Nie X, Fan D, et al. Shot contrastive self-supervised learning for scene boundary detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 9796-9805.
[10] Wu H, Chen K, Luo Y, et al. Scene Consistency Representation Learning for Video Scene Segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 14021-14030.
[11] Mun J, Shin M, Han G, et al. Boundary-aware Self-supervised Learning for Video Scene Segmentation[J]. arXiv preprint arXiv:2201.05277, 2022.
[12] Huang Q, Xiong Y, Rao A, et al. Movienet: A holistic dataset for movie understanding[C]//European Conference on Computer Vision. Springer, Cham, 2020: 709-727.
[13] Han B, Wu W. Video scene segmentation using a novel boundary evaluation criterion and dynamic programming[C]//2011 IEEE International conference on multimedia and expo. IEEE, 2011: 1-6.
[14] Tapaswi M, Bauml M, Stiefelhagen R. Storygraphs: visualizing character interactions as a timeline[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 827-834.
[15] Lin T, Liu X, Li X, et al. Bmn: Boundary-matching network for temporal action proposal generation[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 3889-3898.
[16] Long F, Yao T, Qiu Z, et al. Learning to localize actions from moments[C]//European Conference on Computer Vision. Springer, Cham, 2020: 137-154.
[17] Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representations[C]//International conference on machine learning. PMLR, 2020: 1597-1607.
[18] Roh B, Shin W, Kim I, et al. Spatially consistent representation learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 1144-1153.