MindSpore 推出动态图无图融合能力:为运行时实时融合提供新路径
MindSpore 推出动态图无图融合能力:为运行时实时融合提供新路径
在动态图训练与推理中,灵活性是其核心优势:网络沿真实执行路径逐步展开,shape 随输入实时变化。但灵活性的代价是运行时开销上升:算子以细粒度逐个下发,Host 侧需反复进行 shape 推导、显存申请与算子下发,Device 侧则执行大量碎片化 Kernel。模型越复杂、shape 越动态,开销越显著。
自动算子融合是降低此类开销的关键手段。其目标是将分散的小算子组织为更大粒度的执行单元,减少下发次数、降低中间访存、提升执行效率。
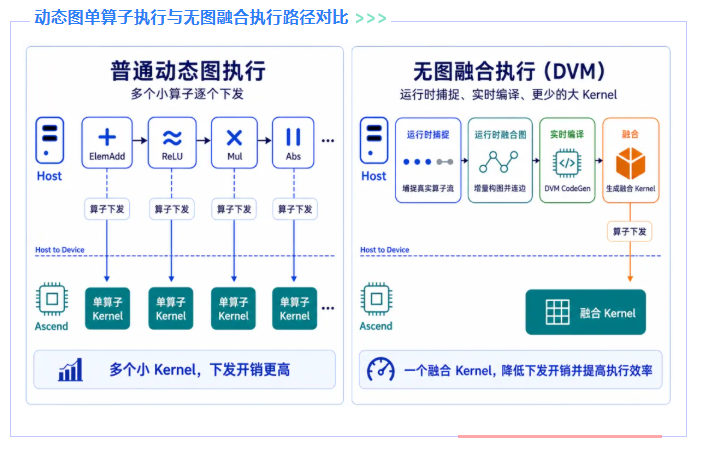
静态图场景下,融合依赖“先成图、再编译”的离线流程,相对容易落地。动态图中,框架拿到的并非预定义的完整计算图,而是一条随运行不断产生的算子流。若仍沿用整图编译思路,shape 变化即触发秒级重编译,而动态图算子下发为微秒级,两者时间尺度严重错位,传统方案难以直接适用。
MindSpore 动态图“无图融合” 正是为此设计。它不依赖静态图缓存,而是在运行时沿真实算子流做增量捕捉与轻量构图,再交由底层实时编译组件完成融合编译与执行,使自动融合直接在动态图链路中生效。这里的“无图”并非内部没有图结构,而是不依赖传统静态图编译流程和整图缓存。
01 动态图融合为何困难
静态图和动态图都希望减少算子碎片、提升执行局部性,但它们面对的问题并不相同。静态图在编译阶段就拿到了稳定计算图,可以围绕整图做融合改写和代码生成;动态图拿到的则是一条持续出现的算子流,真实执行路径、真实输入 shape,甚至真实分支选择,往往都要等到运行时才能确定。
进入 Ascend NPU 的动态 shape 场景后,这个问题会进一步放大,核心挑战主要有三类:
- 多层级 local memory:算子必须根据实际 shape 做 tiling 切分,切分策略直接影响搬运开销和计算效率。
- SIMD 对齐约束:实际实现通常要区分 body 块和 tail 块,动态 shape 会让实现分支快速增多。
- 算子结构可变性:例如 Add 的 broadcast,在不同 shape 组合下可能对应不同的底层执行结构。
因此,动态图融合的难点不仅在于“没有静态图”,更在于算子生成、融合决策和执行路径必须随真实运行实例动态变化。若仍沿用秒级编译链路,图缓存命中率、重复编译开销与端到端时延将很快成为瓶颈。
02 MindSpore 动态图无图融合的核心机制
MindSpore 动态图本身采用多级流水执行机制。无图融合并不是另起一套运行时,而是精准接入到这条既有流水线上。
MindSpore 侧:运行时捕捉与增量构图
在动态图运行过程中,MindSpore 会在 FrontendTask 等关键阶段,对满足条件的 Ascend 算子进行捕捉,并逐步组织成一张轻量级的运行时融合图。这个过程不是离线分析,而是顺着真实执行中的算子流边捕捉、边判断、边决定是否继续融合。
当遇到以下时机时,MindSpore 会触发一次 flush,把当前运行时融合图交给后续阶段继续处理:
- 遇到当前不支持融合的算子,需要在该算子自己的 DeviceTask 下发前先 flush。
- 遇到明确的融合边界,例如当前 Reduce 类算子主要支持前向融合。
- 遇到值依赖或同步接口,例如 asnumpy()、print。
- 遇到 stream 变化或显式同步边界。
DVM 侧:继续切图、Tiling、字节码生成与执行
MindSpore 侧捕捉到的是一张运行时融合图,但它未必适合整体直接下沉为一个执行子图。进入 DVM 后,会结合当前支持的融合规则与编译能力继续切图,并完成:
- 基于实际 shape 和硬件约束做 Tile 切分。
- 判断哪些子结构适合融合到同一个执行子图。
- 为每个执行子图生成可执行字节码。
- 在 Device 侧由虚拟机内核解释执行。
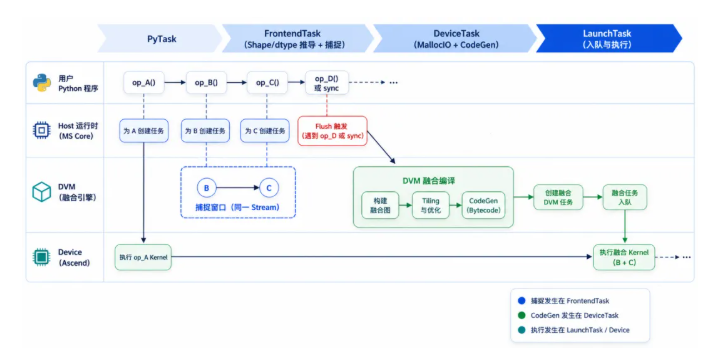
也就是说,MindSpore 侧负责把动态图里的算子流捕捉起来,DVM 侧负责把它继续切成一个或多个执行子图;每个执行子图最终对应一个 DVM 执行单元,也可理解为一个融合 Kernel。
03 真实案例:看懂无图融合的执行链路
以 Add + Abs 为例,不开启无图融合时,Add 和 Abs 会分别完成设备任务与下发,最终对应两个独立 Kernel。
开启无图融合后,这两个算子会先在 MindSpore 侧形成同一个运行时融合图,随后由 DVM 继续完成 Tile 切分和字节码生成;在这个示例里,最终只形成一个执行子图,对应一个 DVM 执行单元。
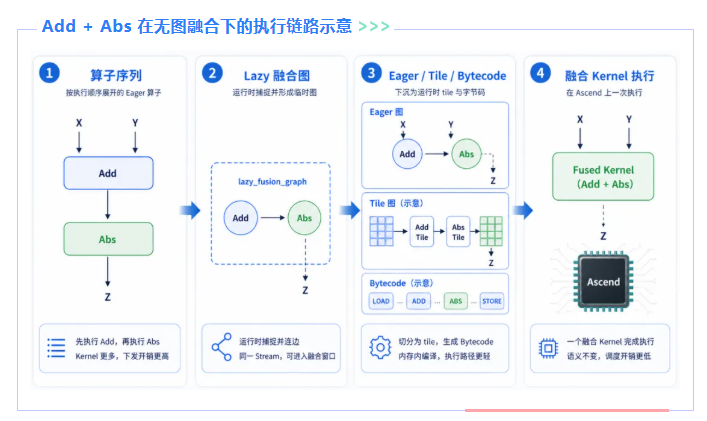
这个例子说明了几件事:
- 动态图算子流如何进入运行时捕捉窗口。
- 运行时融合图如何继续下沉为 DVM 可处理的执行子图。
- Tile 切分和字节码生成如何把图结构落实为执行单元。
- 为何“两次独立下发”最终可收敛成“一次融合执行”。
也就是说,这条链路已经从“两个独立算子”变成了“一个运行时融合图 + 一个 DVM 执行单元”,同时仍保持动态图逐算子执行语义。
04 当前能力边界与 CV 融合扩展
动态图无图融合不只是覆盖最简单的单算子替换,而是已经具备一套明确的融合规则与场景边界。 当前能力可以概括为:
- Elemwise 类算子可相互融合:例如 Abs、Add、Mul、Sub、Div、Exp、Sqrt、Sigmoid、SiLU、GeLU 等。
- Reduce 类算子支持前向融合:例如 SumExt。
- Inplace 类算子支持在对应边界内融合。
- 部分 BatchNorm 相关算子已接入无图融合路径。
此外,MatMul、BatchMatMul 等算子已具备接入路径,但默认不自动开启,需通过白名单显式使能。
在此基础上,更高价值的扩展方向之一,是 CV 融合。这里的 C 指 MatMul 类算子,V 指 Elemwise 类算子。
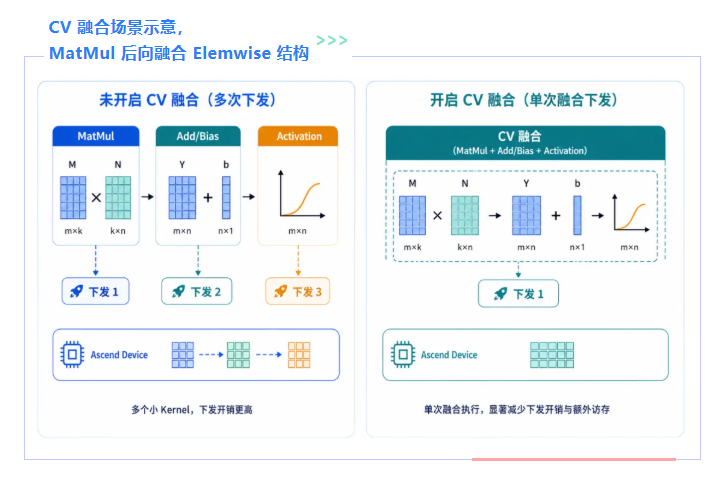
以 MatMul + Add、MatMul + Add + 激活 这类链路为例,它们在训练和推理中都很常见。CV 融合扩展要解决的,就是让 MatMul 的结果继续向后与 Elemwise 结构协同融合。这说明无图融合并不局限于轻量 Elemwise,而是在向更复杂、更贴近真实网络热点路径的场景推进。
05 效果验证与性能数据
无图融合的收益可以从两个层面观察:一是整网端到端性能,二是典型融合链路在 Device 侧的执行收益。
在已验证的训练场景中,开启无图融合后,整网端到端性能收益约为 1%~5%。这类数据覆盖完整训练流程中的 Host 调度、运行时管理和 Device 执行开销,更适合衡量真实网络的最终收益。
下面给出两个已验证场景的 Device 侧算子执行耗时,收益会受到 shape、dtype 和算子组合影响:
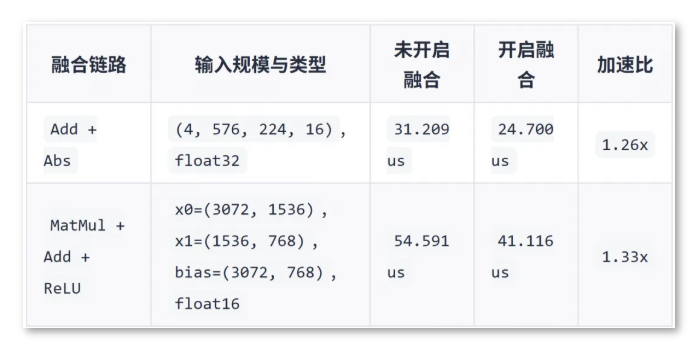
这组数据说明,典型 Elemwise 与 CV 融合链路都能获得实质性收益。
06 如何开启无图融合
通过环境变量 MS_DEV_PYNATIVE_FUSION_FLAGS 即可开启无图融合。
1、开启基础无图融合能力
export MS_DEV_PYNATIVE_FUSION_FLAGS="--opt_level=1"
默认主要覆盖 elemwise、reduce、inplace 等类别算子,以及部分已默认接入的相关算子。
2、额外开启 MatMul 类算子的无图融合
MatMul、BatchMatMul 等算子默认不自动参与无图融合。如果希望它们也接入无图融合流程,可通过 --enable_ops 增量开启:
export MS_DEV_PYNATIVE_FUSION_FLAGS="--opt_level=1 --enable_ops=MatMul,BatchMatMul"
其中:
--opt_level=1:开启动态图无图融合能力。
--enable_ops=MatMul,BatchMatMul:额外打开默认不自动融合的 MatMul 类算子。
07 开源与参与
动态图无图融合的价值,不只是新增了一个优化开关,而是让 MindSpore 在动态图场景下形成了不依赖静态图缓存的原生自动融合能力。
借助 DVM 的实时编译能力,MindSpore 把算子捕捉、运行时构图、实时字节码生成和虚拟机执行串成了一条完整链路,让自动融合不再只是静态图时代的专属能力。后续,随着更多高价值算子和融合模式持续接入,这条能力路线还会继续向更复杂、更贴近真实网络热点路径的场景推进。
我们欢迎大家在昇腾NPU上的动态图训练场景中尝试使用无图融合能力,也欢迎在实际网络中反馈效果与建议,帮助我们一起把这条线路打磨得更实用、更完整。
MindSpore是一个开源深度学习框架,动态图无图融合能力会在开源代码中持续推进,欢迎大家加入MindSpore开源社区,通过如下方式参与开发共建:
